需要用到这方面的数据,单独一页一页的复制了一段时间的数据,发现很是耗时,想从深圳市环保局下载空气质量历史数据。选择日期后,页面出现一个相应的数据表格,每天有24个时间点的。需要将每一天每一个小时的数据都爬下来。页面如下:网址:http://www.szhec.gov.cn/pages/szepb/kqzl...
麻烦大家
拥有18年软件开发和IT教学经验。曾任多家上市公司技术总监、架构师、项目经理、高级软件工程师等职务。 网络人气名人讲师,...
requests.post を使用してリクエスト
上記画像のURL
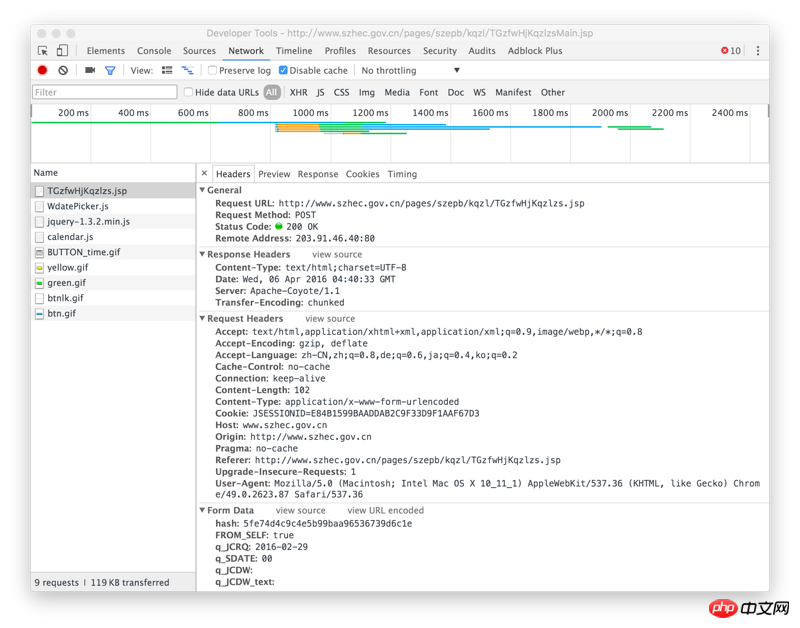
ハッシュ値は上の図の位置にあります。
この写真は応答です
#coding=utf-8bs4 import BeautifulSoup からのインポート リクエスト
get_url="http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp?FLAG=FIRSTFW"#ハッシュ値を取得post_url="http://www.szhec. gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp" #大気質時間を取得するhtml=requests.get(get_url) #Beautiful を使用して Web ページを解析し、ハッシュ値を取得しますhtml_soup=BeautifulSoup (html .text,"html.parser")hash=html_soup.select("input[name=hash]")hash=hash[0].get('value') #Constructデータデータ={
} #この時点で品質管理時間の情報は正しく取得されています tqHtml=requests.post(post_url,data=data)print tqHtml.text
右クリックして要素を検査し、ネットワークを表示し、時間検索を選択して、次の名前の ajax API アドレスを表示します:
続き: おそらくこのコードを試しましたが、プログラムはエラーを報告せず、結果も生成しませんでした。どうしたの? インポートリクエストimport xlwtfrom bs4 import BeautifulSoupimport datetimeimport tqdm
def datelist(開始、終了):
def get_html():
def get_excel():
get_excel()















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




requests.post を使用してリクエスト
上記画像のURL
ハッシュ値は上の図の位置にあります。
この写真は応答です

#coding=utf-8
bs4 import BeautifulSoup からのインポート リクエスト
get_url="http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp?FLAG=FIRSTFW"#ハッシュ値を取得
リーリーpost_url="http://www.szhec. gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp" #大気質時間を取得する
html=requests.get(get_url)
#Beautiful を使用して Web ページを解析し、ハッシュ値を取得します
html_soup=BeautifulSoup (html .text,"html.parser")
hash=html_soup.select("input[name=hash]")
hash=hash[0].get('value')
#Constructデータ
データ={
}
#この時点で品質管理時間の情報は正しく取得されています
tqHtml=requests.post(post_url,data=data)
print tqHtml.text
右クリックして要素を検査し、ネットワークを表示し、時間検索を選択して、次の名前の ajax API アドレスを表示します:
続き:
おそらくこのコードを試しましたが、プログラムはエラーを報告せず、結果も生成しませんでした。どうしたの?
インポートリクエスト
import xlwt
from bs4 import BeautifulSoup
import datetime
import tqdm
def datelist(開始、終了):
リーリーdef get_html():
リーリーdef get_excel():
リーリーget_excel()