
根据网页所给的字符编码将其字节数据decode('gb2312')
用的是scrapy,从给出的url获取body
def parse(self, response):
body = response.body.decode('gb2312')
print(body)
学分:1.5 # body就是这样之类的,中间的冒号是中文的冒号
# 想弄成的效果就是['学分','1.5']
body = body.split(':') # 就这样使用中文的冒号符来分割,但是出错
SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0xa3 in position 0: invalid start byte
请问怎么解决?















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




リーリー
上記のエラーをもう一度見ると、
リーリーbyte 0xa3だったので、ターミナルで何度か試してみたところ、コロン gb2312 がエンコードされていることがわかりました
つまり、Python は gb2312 の本体をデコードするためにデフォルトの utf-8 を使用するはずです。そのため、私が考える 1 つの方法は、デフォルトのエンコード値を変更することです。これは最初の行のステートメントです。
# -*- coding: gb2312 -*-これで操作は成功しましたが、他の方法はありますか?
Python3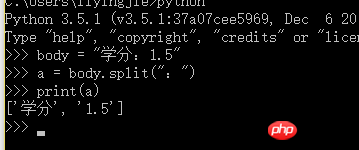
デコード後、本文は Unicode エンコードされる必要があります。次の方法を使用します。
リーリーもう 1 つのエンコーディングの問題については、「人間とコンピューターの対話のための文字エンコーディング」および「5 分で Python 文字エンコーディングを克服する」を参照してください。
リーリー