
代码
'{"code":"A00185","data":"\\u5bf9\\u4e0d\\u8d77\\uff0c\\u60a8\\u77ed\\u65f6\\u95f4\\u53d1\\u8868\\u535a\\u6587\\u8fc7\\u591a\\uff0c\\u8bf7\\u591a\\u4f11\\u606f\\uff0c\\u6ce8\\u610f\\u8eab\\u4f53\\uff01\\u611f\\u8c22\\u60a8\\u5bf9\\u65b0\\u6d6a\\u535a\\u5ba2\\u7684\\u652f\\u6301\\u548c\\u5173\\u6ce8\\uff01"}'用正则不行,用replace不行,应该是\是属于转义符,不过因为访问的源码中,想把这个替换一下,要怎么处理!?
问题补充:
我是想把\\替换成\ 请问要怎么处理?
错如如下!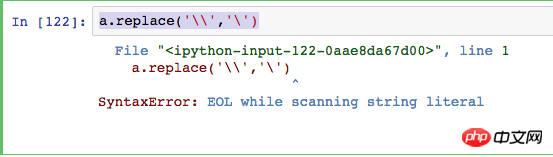
楼下一楼的大哥一直答不对题,我也是比较郁闷.我就想把一个字符串
\\的替换成\
然后想要如下结果:

其他的原理什么的其实我一点也不关心,最好是用一行代码就能回答问题的,万分感谢!














![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




の転送文字の場合、
\=となります。元の投稿者はノーと言っていたので、具体的にテストしてみました。
リーリー結果は次のとおりです
リーリーポスターの新しい投稿でコード スニペットを見つけて、コード プロンプトが表示されずにポスターが再度更新されました。
リーリーこの文はもともと間違って書かれています。
リーリー'エスケープが閉じ引用符をエスケープした後、2 番目の文字列が不完全であるため、当然エラーが報告されます。また、質問者様の要望によれば、この文字列は元々
なので、文字列を定義する際に\を 2 つ書くと、実際のに相当するとのことです。 。次のコードで確認できます:
出力結果
リーリー数回の交渉の後、最終的に質問の目的がわかりました。それは、json 内の中国語を解析することです。 。 。
とてもシンプル
リーリー出力
リーリー