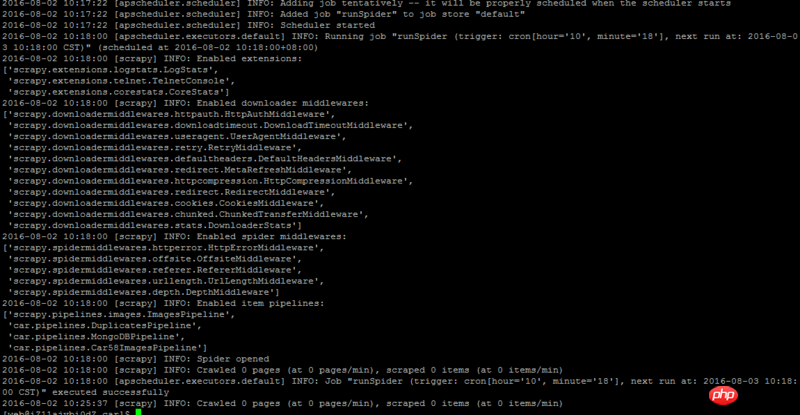
爬虫使用scrapy框架写的,使用脚本方式执行,配合APScheduler任务调度器定时执行,爬虫本身可以执行,只是定时执行失败,也没有报错误原因,日志见图,
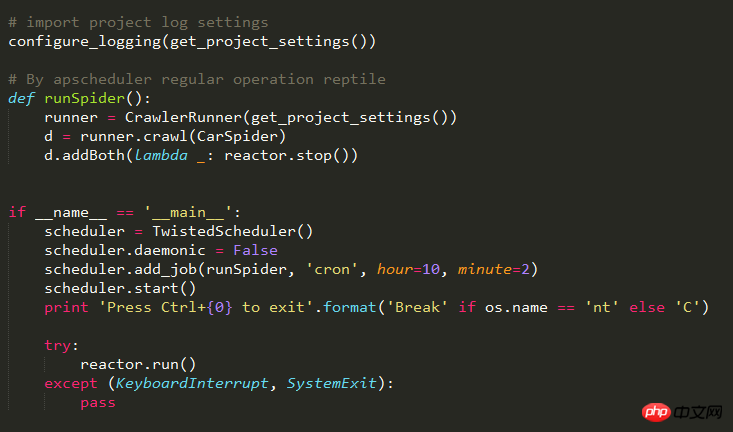
这是程序执行主要代码部分
代码在windows系统可以运行,目前在Linux失败了,请问是什么原因?
认证0级讲师
いろいろいじって調べた結果、最終的に Linux で実行できるようになりました。初めてクローラー ジョブをスケジュールしたときは有効になりましたが、スケジュールしたときのみ Web ページが解析されませんでした。 2回目は解析が開始され、正常に動作しました。私自身の推測では、apscheduler タスク スケジューリング フレームワークを Scrapy と組み合わせて使用する場合は、Twisted フレームワークの下で使用する必要があります。クローラータスクを定期的に実行する場合、初回の解析は行われず、2回目の解析が行われます。















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




いろいろいじって調べた結果、最終的に Linux で実行できるようになりました。初めてクローラー ジョブをスケジュールしたときは有効になりましたが、スケジュールしたときのみ Web ページが解析されませんでした。 2回目は解析が開始され、正常に動作しました。私自身の推測では、apscheduler タスク スケジューリング フレームワークを Scrapy と組み合わせて使用する場合は、Twisted フレームワークの下で使用する必要があります。クローラータスクを定期的に実行する場合、初回の解析は行われず、2回目の解析が行われます。