
初学使用scrapy,按照教程建了很小一个例子,还没有到用pipeline之类的地步,只想看看能不能爬东西下来。代码如下:
spider.py:
from scrapy.spider import Spider
class newsSpider(Spider):
name = "News"
allowed_domains = ["people.com.cn"]
start_urls = ["http://people.com.cn"]
def parse(self,response):
print response.url
filename = response.url.split('/')[-2]
print filename
open(filename,'w').write(response.body)items.py:
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class newsItem(Item):
title = Field()
link = Field()
desc = Field()但是发现几个新闻网站都爬取失败了,包括:
people.com.cn
news.163.com
ifeng.com
以上几个都会报错:
ERROR: Spider error processing <GET http://.....com> (referer: None)但是,我爬tieba.baidu.com和例子中的"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/"是可以爬下来东西的,也就是response是有内容的,也没有error。
我从以下几个方面改了改:
1.绕过robots.txt,在setting里把ROBOTSTXT_OBEY = False
2.禁用/启用cookie,COOKIES_ENABLED = False/True
3.设置USER_AGENT,USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'
`
结果并没有改变,那些新闻网站还是起始网页就爬不下来东西,请问怎么办?















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




こんにちは、これがこの問題を解決する方法です。
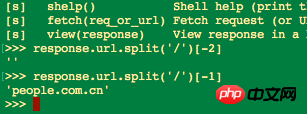
を最初に開きました。 リーリーシェルモードに入り、次のように入力します:
リーリー中身が空になっていることが分かりましたので、この時点でURLの分割を間違えたと判断し、以下のコードを試してみました。 リーリー
次の出力が見つかりました:
元のポスターの背後にある理由は、ファイル名が存在しないため、ドキュメントは生成されないということです。試してみてください。
ターミナルでテストして試してみてください
http://scrapy-chs.readthedocs...
scrapy のドキュメントを注意深く読んだかどうかはわかりません

http://scrapy-chs.readthedocs...