现在可以从网上下载这些代码,怎么进行部署和运行代码从github上下载了关于分布式的代码,不知道怎么用,求各位大神指点下。。。下面是网址https://github.com/rolando/scrapy-redis环境已经按照上面的配置好了,但不知道如何实现分布式。分布式我是这样理解的,有一个redis服务器,从一个网页上获取url种子,并将url种子放到redis服务器了,然后将这些url种子分配给其他机器。中间存在调度方面的问题,以及服务器和机器间的通信。
谢谢。。。
业精于勤,荒于嬉;行成于思,毁于随。
これは一言や二文ではうまく言い表せない気がします。
以前参照したこのブログ投稿がお役に立てば幸いです。
私の個人的な理解を話させてください。
scrapy は、改良された python 独自の collection.deque を使用して、クロールされる request を保存します。 2 つ以上の Spider がこの deque を共有しますか? scrapy使用改良之后的python自带的collection.deque来存放待爬取的request,该怎么让两个以上的Spider共用这个deque呢?
scrapy
python
collection.deque
request
Spider
deque
待爬队列都不能共享,分布式就是无稽之谈。scrapy-redis提供了一个解决方法,把collection.deque换成redis数据库,多个爬虫从同一个redis服务器存放要爬取的request,这样就能让多个spider去同一个数据库里读取,这样分布式的主要问题就解决了.
scrapy-redis
redis
spider
注意:并不是换了redis来存放request,scrapy就能直接分布式了!
scrapy中跟待爬队列直接相关的就是调度器Scheduler。
待爬队列
Scheduler
参考scrapy的结构
它负责对新的request进行入列操作,取出下一个要爬取的request等操作。所以,换了redis之后,其他组件都要改动。
所以,我个人的理解就是,在多个机器上部署相同的爬虫,分布式部署redis,参考地址我的博客,比较简单。而这些工作,包括url去重,就是已经写好的scrapy-redis框架的功能。
参考地址在这里,你可以去下载example看看具体的实现。我最近也在搞这个scrapy-redis
redis サーバーはクロールされる request を保存するため、複数の spider が同じデータベースから読み取ることができ、分散の主な問題が解決されます。 注: redis が request を保存するために置き換えられるわけではありません。scrapy は直接配布できます。 🎜scrapy は、クロールされるキュー であるスケジューラー Scheduler に直接関連しています。 🎜 🎜scrapy🎜 🎜新しい request をキューに入れたり、クロールされる次の request を取り出したり、その他の操作を担当します。したがって、redis を置き換えた後は、他のコンポーネントを変更する必要があります。 🎜 🎜つまり、私の個人的な理解は、同じクローラーを複数のマシン、分散デプロイメント redis、参照アドレス私のブログにデプロイするのは比較的簡単であるということです。 URL 重複排除を含むこれらのタスクは、すでに作成された scrapy-redis フレームワークの機能です。 🎜 🎜参照アドレスはここにあります。サンプルをダウンロードして具体的な実装を確認できます。私も最近この scrapy-redis に取り組んでおり、デプロイ後にこの回答を更新します。 🎜 🎜新しい進捗状況がある場合は、それを共有してコミュニケーションすることができます。 🎜
注: redis が request を保存するために置き換えられるわけではありません。scrapy は直接配布できます。
クロールされるキュー
@伟兴 こんにちは、15.10.11 にこのコメントを見ました。今何か結果はありますか? あなたのブログをいくつか紹介していただけますか?ありがとうございます〜chenjian158978@gmail.comまでご連絡ください
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




これは一言や二文ではうまく言い表せない気がします。
以前参照したこのブログ投稿がお役に立てば幸いです。
私の個人的な理解を話させてください。
scrapyは、改良されたpython独自のcollection.dequeを使用して、クロールされるrequestを保存します。 2 つ以上のSpiderがこのdequeを共有しますか?scrapy使用改良之后的python自带的collection.deque来存放待爬取的request,该怎么让两个以上的Spider共用这个deque呢?待爬队列都不能共享,分布式就是无稽之谈。
scrapy-redis提供了一个解决方法,把collection.deque换成redis数据库,多个爬虫从同一个redis服务器存放要爬取的request,这样就能让多个spider去同一个数据库里读取,这样分布式的主要问题就解决了.注意:并不是换了
redis来存放request,scrapy就能直接分布式了!scrapy中跟待爬队列直接相关的就是调度器Scheduler。参考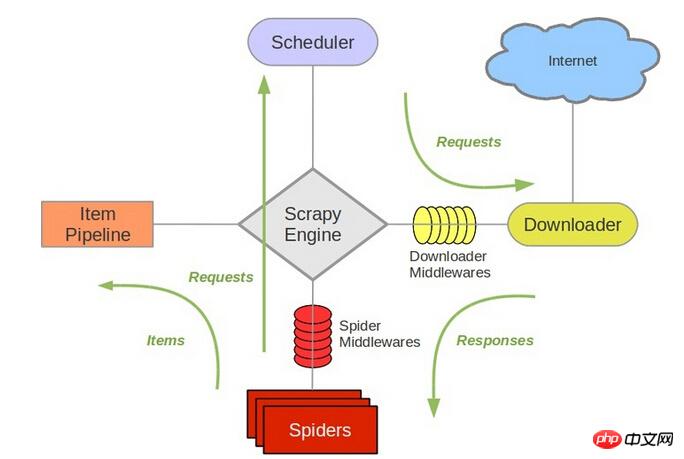
scrapy的结构它负责对新的
request进行入列操作,取出下一个要爬取的request等操作。所以,换了redis之后,其他组件都要改动。所以,我个人的理解就是,在多个机器上部署相同的爬虫,分布式部署
redis,参考地址我的博客,比较简单。而这些工作,包括url去重,就是已经写好的
scrapy-redis框架的功能。参考地址在这里,你可以去下载example看看具体的实现。我最近也在搞这个
クロール対象のキューは共有できず、分散もナンセンス。scrapy-redisscrapy-redisは解決策を提供し、collection.dequeをredisデータベースに置き換えます。これにより、複数のクローラーが同じredis サーバーはクロールされる 🎜
🎜新しい
🎜
🎜新しい requestを保存するため、複数のspiderが同じデータベースから読み取ることができ、分散の主な問題が解決されます。注:
🎜redisがrequestを保存するために置き換えられるわけではありません。scrapyは直接配布できます。scrapyは、クロールされるキューであるスケジューラーSchedulerに直接関連しています。 🎜 🎜scrapyrequestをキューに入れたり、クロールされる次のrequestを取り出したり、その他の操作を担当します。したがって、redis を置き換えた後は、他のコンポーネントを変更する必要があります。 🎜 🎜つまり、私の個人的な理解は、同じクローラーを複数のマシン、分散デプロイメントredis、参照アドレス私のブログにデプロイするのは比較的簡単であるということです。 URL 重複排除を含むこれらのタスクは、すでに作成された
scrapy-redisフレームワークの機能です。 🎜 🎜参照アドレスはここにあります。サンプルをダウンロードして具体的な実装を確認できます。私も最近このscrapy-redisに取り組んでおり、デプロイ後にこの回答を更新します。 🎜 🎜新しい進捗状況がある場合は、それを共有してコミュニケーションすることができます。 🎜@伟兴 こんにちは、15.10.11 にこのコメントを見ました。今何か結果はありますか?
あなたのブログをいくつか紹介していただけますか?ありがとうございます〜
chenjian158978@gmail.comまでご連絡ください