

RequireJs source code analysis reveals how script loading works
Introduction
As the saying goes, programmers who don’t like to study principles are not good programmers, and programmers who don’t like to read source code are not good jser. In the past two days, I have seen issues related to front-end modularization, and I have discovered that the JavaScript community has worked really hard for front-end engineering. Today I studied the issue of front-end modularization for a day. First, I briefly understood the standard specifications of modularization, then learned about the syntax and usage of RequireJs, and finally studied the design pattern and source code of RequireJs, so I wanted to record the relevant experience. , analyze the principle of module loading.
1. Understanding RequireJs
Before we begin, we need to understand front-end modularization. This article does not discuss issues related to front-end modularization. For questions in this regard, you can refer to Ruan Yifeng’s series of articles Javascript Modular Programming.
The first step to use RequireJs: Go to the official website;
The second step: Download the file;


Step 3: Introduce requirejs.js into the page and set the main function;
1 <script type="text/javascript" src="scripts/require.js?1.1.11" data-main="scripts/main.js?1.1.11"></script>
Then we can program in the main.js file. requirejs adopts the main functional idea. A file is a module. There can be dependencies between modules, or there can be no dependencies between modules. relationship. Using requirejs, we don't have to introduce all modules into the page when programming. Instead, we need a module. Introducing a module is equivalent to import in Java.
Define module:
1 //直接定义一个对象 2 define({ 3 color: "black", 4 size: "unisize" 5 }); 6 //通过函数返回一个对象,即可以实现 IIFE 7 define(function () { 8 //Do setup work here 9 10 return {11 color: "black",12 size: "unisize"13 }14 });15 //定义有依赖项的模块16 define(["./cart", "./inventory"], function(cart, inventory) {17 //return an object to define the "my/shirt" module.18 return {19 color: "blue",20 size: "large",21 addToCart: function() {22 inventory.decrement(this);23 cart.add(this);24 }25 }26 }27 );Import module:
1 //导入一个模块2 require(['foo'], function(foo) {3 //do something4 });5 //导入多个模块6 require(['foo', 'bar'], function(foo, bar) {7 //do something8 });Regarding the use of requirejs, you can check the official website API, or you can refer to RequireJS and AMD specifications. This article will not explain the use of requirejs for the time being.
2. Main function entry
One of the core ideas of requirejs is to use a specified function entry, just like C++'s int main(), Java's public static void main( ), requirejs is used by caching the main function in the script tag. That is, the URL of the script file is cached on the script tag.
1 <script type="text/javascript" src="scripts/require.js?1.1.11" data-main="scripts/main.js?1.1.11"></script>
When I first came to the computer, I saw it, wow! Does the script tag have any unknown attributes? I was so scared that I quickly opened W3C to view the relevant API, and felt ashamed of my basic knowledge of HTML. But unfortunately, the script tag has no relevant attributes, and it is not even a standard attribute. So what is it? Now go directly to the requirejs source code:
1 //Look for a data-main attribute to set main script for the page2 //to load. If it is there, the path to data main becomes the3 //baseUrl, if it is not already set.4 dataMain = script.getAttribute('data-main');In fact, in requirejs we just get the data cached on the script tag, and then take out the data and load it, that is, just follow the The dynamic loading script is the same. How to operate it specifically, the source code will be released in the explanation below.
3. Dynamic loading script
This part is the core of the entire requirejs. We know that the way to load modules in Node.js is synchronously Yes, this is because all files on the server side are stored on the local hard disk, and the transfer rate is fast and stable. If you switch to the browser, you can't do this, because the browser loading script will communicate with the server. This is an unknown request. If you use a synchronous method to load, it may continue to be blocked. In order to prevent the browser from blocking, we need to load the script asynchronously. Because it is loaded asynchronously, operations that depend on the module must be executed after the script is loaded, and a callback function must be used here.
We know that if the script file is defined in HTML, the execution order of the script is synchronous, for example:
1 //module1.js2 console.log("module1");1 //module2.js2 console.log("module2");1 //module3.js2 console.log("module3");1 <script type="text/javascript" src="scripts/module/module1.js?1.1.11"></script>2 <script type="text/javascript" src="scripts/module/module2.js?1.1.11"></script>3 <script type="text/javascript" src="scripts/module/module3.js?1.1.11"></script>
那么在浏览器端总是会输出:

但是如果是动态加载脚本的话,脚本的执行顺序是异步的,而且不光是异步的,还是无序的:
1 //main.js 2 console.log("main start"); 3 4 var script1 = document.createElement("script"); 5 script1.src = "scripts/module/module1.js?1.1.11"; 6 document.head.appendChild(script1); 7 8 var script2 = document.createElement("script"); 9 script2.src = "scripts/module/module2.js?1.1.11";10 document.head.appendChild(script2);11 12 var script3 = document.createElement("script");13 script3.src = "scripts/module/module3.js?1.1.11";14 document.head.appendChild(script3);15 16 console.log("main end");使用这种方式加载脚本会造成脚本的无序加载,浏览器按照先来先运行的方法执行脚本,如果 module1.js 文件比较大,那么极其有可能会在 module2.js 和 module3.js 后执行,所以说这也是不可控的。要知道一个程序当中最大的 BUG 就是一个不可控的 BUG ,有时候它可能按顺序执行,有时候它可能乱序,这一定不是我们想要的。
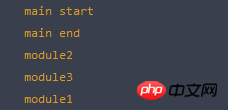
注意这里的还有一个重点是,"module" 的输出永远会在 "main end" 之后。这正是动态加载脚本异步性的特征,因为当前的脚本是一个 task ,而无论其他脚本的加载速度有多快,它都会在 Event Queue 的后面等待调度执行。这里涉及到一个关键的知识 — Event Loop ,如果你还对 JavaScript Event Loop 不了解,那么请先阅读这篇文章 深入理解 JavaScript 事件循环(一)— Event Loop。
四、导入模块原理
在上一小节,我们了解到,使用动态加载脚本的方式会使脚本无序执行,这一定是软件开发的噩梦,想象一下你的模块之间存在上下依赖的关系,而这时候他们的加载顺序是不可控的。动态加载同时也具有异步性,所以在 main.js 脚本文件中根本无法访问到模块文件中的任何变量。那么 requirejs 是如何解决这个问题的呢?我们知道在 requirejs 中,任何文件都是一个模块,一个模块也就是一个文件,包括主模块 main.js,下面我们看一段 requirejs 的源码:
1 /** 2 * Creates the node for the load command. Only used in browser envs. 3 */ 4 req.createNode = function (config, moduleName, url) { 5 var node = config.xhtml ? 6 document.createElementNS('http://www.w3.org/1999/xhtml', 'html:script') : 7 document.createElement('script'); 8 node.type = config.scriptType || 'text/javascript'; 9 node.charset = 'utf-8';10 node.async = true;11 return node;12 };在这段代码中我们可以看出, requirejs 导入模块的方式实际就是创建脚本标签,一切的模块都需要经过这个方法创建。那么 requirejs 又是如何处理异步加载的呢?传说江湖上最高深的医术不是什么灵丹妙药,而是以毒攻毒,requirejs 也深得其精髓,既然动态加载是异步的,那么我也用异步来对付你,使用 onload 事件来处理回调函数:
1 //In the browser so use a script tag 2 node = req.createNode(config, moduleName, url); 3 4 node.setAttribute('data-requirecontext', context.contextName); 5 node.setAttribute('data-requiremodule', moduleName); 6 7 //Set up load listener. Test attachEvent first because IE9 has 8 //a subtle issue in its addEventListener and script onload firings 9 //that do not match the behavior of all other browsers with10 //addEventListener support, which fire the onload event for a11 //script right after the script execution. See:12 //13 //UNFORTUNATELY Opera implements attachEvent but does not follow the script14 //script execution mode.15 if (node.attachEvent &&16 //Check if node.attachEvent is artificially added by custom script or17 //natively supported by browser18 //read 19 //if we can NOT find [native code] then it must NOT natively supported.20 //in IE8, node.attachEvent does not have toString()21 //Note the test for "[native code" with no closing brace, see:22 //23 !(node.attachEvent.toString && node.attachEvent.toString().indexOf('[native code') < 0) &&24 !isOpera) {25 //Probably IE. IE (at least 6-8) do not fire26 //script onload right after executing the script, so27 //we cannot tie the anonymous define call to a name.28 //However, IE reports the script as being in 'interactive'29 //readyState at the time of the define call.30 useInteractive = true;31 32 node.attachEvent('onreadystatechange', context.onScriptLoad);33 //It would be great to add an error handler here to catch34 //404s in IE9+. However, onreadystatechange will fire before35 //the error handler, so that does not help. If addEventListener36 //is used, then IE will fire error before load, but we cannot37 //use that pathway given the connect.microsoft.com issue38 //mentioned above about not doing the 'script execute,39 //then fire the script load event listener before execute40 //next script' that other browsers do.41 //Best hope: IE10 fixes the issues,42 //and then destroys all installs of IE 6-9.43 //node.attachEvent('onerror', context.onScriptError);44 } else {45 node.addEventListener('load', context.onScriptLoad, false);46 node.addEventListener('error', context.onScriptError, false);47 }48 node.src = url;注意在这段源码当中的监听事件,既然动态加载脚本是异步的的,那么干脆使用 onload 事件来处理回调函数,这样就保证了在我们的程序执行前依赖的模块一定会提前加载完成。因为在事件队列里, onload 事件是在脚本加载完成之后触发的,也就是在事件队列里面永远处在依赖模块的后面,例如我们执行:
1 require(["module"], function (module) {2 //do something3 });那么在事件队列里面的相对顺序会是这样:

相信细心的同学可能会注意到了,在源码当中不光光有 onload 事件,同时还添加了一个 onerror 事件,我们在使用 requirejs 的时候也可以定义一个模块加载失败的处理函数,这个函数在底层也就对应了 onerror 事件。同理,其和 onload 事件一样是一个异步的事件,同时也永远发生在模块加载之后。
谈到这里 requirejs 的核心模块思想也就一目了然了,不过其中的过程还远不直这些,博主只是将模块加载的实现思想抛了出来,但 requirejs 的具体实现还要复杂的多,比如我们定义模块的时候可以导入依赖模块,导入模块的时候还可以导入多个依赖,具体的实现方法我就没有深究过了, requirejs 虽然不大,但是源码也是有两千多行的... ...但是只要理解了动态加载脚本的原理过后,其思想也就不难理解了,比如我现在就可以想到一个简单的实现多个模块依赖的方法,使用计数的方式检查模块是否加载完全:
1 function myRequire(deps, callback){ 2 //记录模块加载数量 3 var ready = 0; 4 //创建脚本标签 5 function load (url) { 6 var script = document.createElement("script"); 7 script.type = 'text/javascript'; 8 script.async = true; 9 script.src = url;10 return script;11 }12 var nodes = [];13 for (var i = deps.length - 1; i >= 0; i--) {14 nodes.push(load(deps[i]));15 }16 //加载脚本17 for (var i = nodes.length - 1; i >= 0; i--) {18 nodes[i].addEventListener("load", function(event){19 ready++;20 //如果所有依赖脚本加载完成,则执行回调函数;21 if(ready === nodes.length){22 callback()23 }24 }, false);25 document.head.appendChild(nodes[i]);26 }27 }实验一下是否能够工作:
1 myRequire(["module/module1.js?1.1.11", "module/module2.js?1.1.11", "module/module3.js?1.1.11"], function(){2 console.log("ready!");3 }); 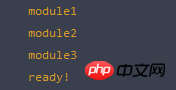
Yes, it's work!
Summary
The core idea of requirejs loading module is to take advantage of the asynchronous nature of dynamically loaded scripts and the onload event to fight virus with poison. Regarding the loading of scripts, we need to pay attention to the following points:
Introducing the

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos
AI Clothes Remover
Online AI tool for removing clothes from photos.
Undress AI Tool
Undress images for free
Clothoff.io
AI clothes remover
Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
What's New in Windows 11 KB5054979 & How to Fix Update Issues3 weeks ago By DDDHow to fix KB5055523 fails to install in Windows 11?2 weeks ago By DDDInZoi: How To Apply To School And University4 weeks ago By DDDHow to fix KB5055518 fails to install in Windows 10?2 weeks ago By DDDRoblox: Dead Rails – How To Summon And Defeat Nikola Tesla1 months ago By 尊渡假赌尊渡假赌尊渡假赌
Hot Tools
Notepad++7.3.1
Easy-to-use and free code editor
SublimeText3 Chinese version
Chinese version, very easy to use
Zend Studio 13.0.1
Powerful PHP integrated development environment
Dreamweaver CS6
Visual web development tools
SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics













![Error loading plugin in Illustrator [Fixed]](https://img.php.cn/upload/article/000/465/014/170831522770626.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) Error loading plugin in Illustrator [Fixed]
Feb 19, 2024 pm 12:00 PM
Error loading plugin in Illustrator [Fixed]
Feb 19, 2024 pm 12:00 PM
When launching Adobe Illustrator, does a message about an error loading the plug-in pop up? Some Illustrator users have encountered this error when opening the application. The message is followed by a list of problematic plugins. This error message indicates that there is a problem with the installed plug-in, but it may also be caused by other reasons such as a damaged Visual C++ DLL file or a damaged preference file. If you encounter this error, we will guide you in this article to fix the problem, so continue reading below. Error loading plug-in in Illustrator If you receive an "Error loading plug-in" error message when trying to launch Adobe Illustrator, you can use the following: As an administrator
 How to implement an online speech recognition system using WebSocket and JavaScript
Dec 17, 2023 pm 02:54 PM
How to implement an online speech recognition system using WebSocket and JavaScript
Dec 17, 2023 pm 02:54 PM
How to use WebSocket and JavaScript to implement an online speech recognition system Introduction: With the continuous development of technology, speech recognition technology has become an important part of the field of artificial intelligence. The online speech recognition system based on WebSocket and JavaScript has the characteristics of low latency, real-time and cross-platform, and has become a widely used solution. This article will introduce how to use WebSocket and JavaScript to implement an online speech recognition system.
 WebSocket and JavaScript: key technologies for implementing real-time monitoring systems
Dec 17, 2023 pm 05:30 PM
WebSocket and JavaScript: key technologies for implementing real-time monitoring systems
Dec 17, 2023 pm 05:30 PM
WebSocket and JavaScript: Key technologies for realizing real-time monitoring systems Introduction: With the rapid development of Internet technology, real-time monitoring systems have been widely used in various fields. One of the key technologies to achieve real-time monitoring is the combination of WebSocket and JavaScript. This article will introduce the application of WebSocket and JavaScript in real-time monitoring systems, give code examples, and explain their implementation principles in detail. 1. WebSocket technology
 Stremio subtitles not working; error loading subtitles
Feb 24, 2024 am 09:50 AM
Stremio subtitles not working; error loading subtitles
Feb 24, 2024 am 09:50 AM
Subtitles not working on Stremio on your Windows PC? Some Stremio users reported that subtitles were not displayed in the videos. Many users reported encountering an error message that said "Error loading subtitles." Here is the full error message that appears with this error: An error occurred while loading subtitles Failed to load subtitles: This could be a problem with the plugin you are using or your network. As the error message says, it could be your internet connection that is causing the error. So please check your network connection and make sure your internet is working properly. Apart from this, there could be other reasons behind this error, including conflicting subtitles add-on, unsupported subtitles for specific video content, and outdated Stremio app. like
 How to use JavaScript and WebSocket to implement a real-time online ordering system
Dec 17, 2023 pm 12:09 PM
How to use JavaScript and WebSocket to implement a real-time online ordering system
Dec 17, 2023 pm 12:09 PM
Introduction to how to use JavaScript and WebSocket to implement a real-time online ordering system: With the popularity of the Internet and the advancement of technology, more and more restaurants have begun to provide online ordering services. In order to implement a real-time online ordering system, we can use JavaScript and WebSocket technology. WebSocket is a full-duplex communication protocol based on the TCP protocol, which can realize real-time two-way communication between the client and the server. In the real-time online ordering system, when the user selects dishes and places an order
 How to implement an online reservation system using WebSocket and JavaScript
Dec 17, 2023 am 09:39 AM
How to implement an online reservation system using WebSocket and JavaScript
Dec 17, 2023 am 09:39 AM
How to use WebSocket and JavaScript to implement an online reservation system. In today's digital era, more and more businesses and services need to provide online reservation functions. It is crucial to implement an efficient and real-time online reservation system. This article will introduce how to use WebSocket and JavaScript to implement an online reservation system, and provide specific code examples. 1. What is WebSocket? WebSocket is a full-duplex method on a single TCP connection.
 Outlook freezes when inserting hyperlink
Feb 19, 2024 pm 03:00 PM
Outlook freezes when inserting hyperlink
Feb 19, 2024 pm 03:00 PM
If you encounter freezing issues when inserting hyperlinks into Outlook, it may be due to unstable network connections, old Outlook versions, interference from antivirus software, or add-in conflicts. These factors may cause Outlook to fail to handle hyperlink operations properly. Fix Outlook freezes when inserting hyperlinks Use the following fixes to fix Outlook freezes when inserting hyperlinks: Check installed add-ins Update Outlook Temporarily disable your antivirus software and then try creating a new user profile Fix Office apps Program Uninstall and reinstall Office Let’s get started. 1] Check the installed add-ins. It may be that an add-in installed in Outlook is causing the problem.
 JavaScript and WebSocket: Building an efficient real-time weather forecasting system
Dec 17, 2023 pm 05:13 PM
JavaScript and WebSocket: Building an efficient real-time weather forecasting system
Dec 17, 2023 pm 05:13 PM
JavaScript and WebSocket: Building an efficient real-time weather forecast system Introduction: Today, the accuracy of weather forecasts is of great significance to daily life and decision-making. As technology develops, we can provide more accurate and reliable weather forecasts by obtaining weather data in real time. In this article, we will learn how to use JavaScript and WebSocket technology to build an efficient real-time weather forecast system. This article will demonstrate the implementation process through specific code examples. We
