

1. Crawler process
Our ultimate goal is to crawl the daily sales of Lima Financial Management, and know which products are sold, and which users each product uses at what time bought. First, let’s introduce the main steps of crawling:
We want to crawl the page data. The first step is of course to analyze the page structure and what to crawl. Page, what is the structure of the page, does it require login? Is there an ajax interface, what kind of data is returned, etc.
After analyzing clearly which pages and ajax to crawl, it is time to crawl the data. Today's web page data is roughly divided into synchronization pages and ajax interfaces. Synchronous capture of page data requires us to first analyze the structure of the web page. Python crawls data generally to obtain the required data through regular expression matching; node has a cheerio tool that can convert the obtained page content into a jquery object. Then you can use jquery's powerful dom API to obtain node-related data. In fact, if you look at the source code, the essence of these APIs is regular matching. Ajax interface data is generally in json format and is relatively simple to process.
After the captured data, a simple filtering will be done, and then the required data will be saved for subsequent analysis and processing. Of course we can use databases such as MySQL and Mongodb to store data. Here, for convenience, we directly use file storage.
Because we ultimately want to display the data, we need to process and analyze the original data according to certain dimensions, and then return it to the client. This process can be processed during storage, or during display, the front-end sends a request, and the background retrieves the stored data and processes it again. This depends on how we want to display the data.
After so much work, there is no display output at all, how can we be willing to do so? This is back to our old business, and everyone should be familiar with the front-end display page. Displaying the data is more intuitive and makes it easier for us to analyze statistics.
Superagent is a lightweight http library and a very convenient client request proxy module in nodejs. , when we need to make network requests such as get, post, head, etc., try it.
Cheerio can be understood as a Node.js version of jquery, which is used to retrieve data from web pages using css selector. The usage method is exactly the same as jquery.
Async is a process control toolkit that provides direct and powerful asynchronous function mapLimit(arr, limit, iterator, callback). We mainly use this method. Everyone You can check out the API on the official website.
arr-del is a tool I wrote myself to delete array elements. You can perform one-time deletion by passing in an array consisting of the index of the array elements to be deleted.
arr-sort is an array sorting tool I wrote myself. Sorting can be based on one or more attributes, and nested attributes are supported. Moreover, the sorting direction can be specified in each condition, and comparison functions can be passed in.
Let’s first review our crawling ideas. The products on Lima Financial Management Online are mainly fixed-term and Lima Treasury (the latest financial management products of China Everbright Bank are difficult to process and have high starting investment amounts, so few people buy them, so there are no statistics here). Periodically we can crawl the ajax interface of the financial management page: https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=0. (Update: Regularly out of stock in the near future, you may not be able to see the data) The data is as shown below:
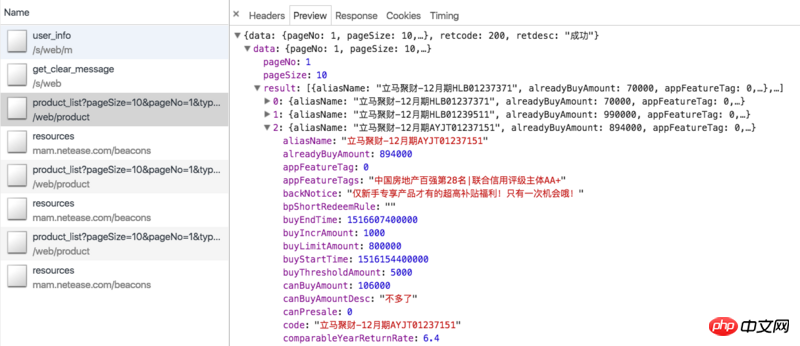
This includes all products currently on sale online For periodic products, the ajax data only has information related to the product itself, such as product ID, raised amount, current sales, annualized rate of return, number of investment days, etc., but no information about which users purchased the product. So we need to take the id parameter to crawl its product details page, such as Jucai immediately - December issue HLB01239511. The details page has a column of investment records, which contains the information we need, as shown in the following figure:
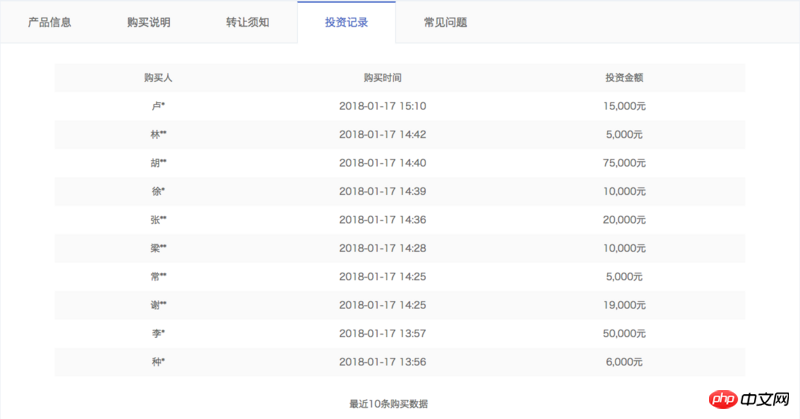
However, the details page requires us to log in It can only be viewed in the status, which requires us to bring cookies to visit, and cookies have validity limits. How can we keep our cookies in the logged-in state? Please see below.
In fact, Lima Treasury also has a similar ajax interface: https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=1, but the relevant data inside is written Dead, meaningless. Moreover, there is no investment record information on the vault’s details page. This requires us to crawl the ajax interface of the homepage mentioned at the beginning: https://www.lmlc.com/s/web/home/user_buying. But later I discovered that this interface is updated every three minutes, which means that the background requests data from the server every three minutes. There are 10 pieces of data at a time, so if the number of records of purchased products exceeds 10 within three minutes, data will be omitted. There is no way around this, so the statistics of Lima Treasury will be lower than the real ones.
Because the product details page requires login, we need to get the login cookie first. The getCookie method is as follows:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
} The phone and password parameters are passed in from the command line, which are the account number and password used to log in to Financial Management immediately with the mobile phone number. We use superagent to simulate the request for immediate financial management login interface: https://www.lmlc.com/user/s/web/logon. Pass in the corresponding parameters. In the callback, we get the set-cookie information of the header and send a setCookeie event. Because we have set up a listening event: emitter.on("setCookie", requestData), once we obtain the cookie, we will execute the requestData method.
The code of the requestData method is as follows:
function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i<len; i++){
if(+new Date() < addData.result[i].buyStartTime){
if(preIds.indexOf(addData.result[i].id) == -1){
preIds.push(addData.result[i].id);
setPreId(addData.result[i].buyStartTime, addData.result[i].id);
}
}else{
pageUrls.push('https://www.lmlc.com/web/product/product_detail.html?id=' + addData.result[i].id);
}
}
function setPreId(time, id){
cache[id] = setInterval(function(){
if(time - (+new Date()) < 1000){
// 预售产品开始抢购,直接修改爬取频次为1s,防止丢失数据
clearInterval(cache[id]);
clearInterval(timer);
delay = 1000;
timer = setInterval(function(){
requestData();
}, delay);
// 同时删除id记录
let index = preIds.indexOf(id);
sort.delArrByIndex(preIds, [index]);
}
}, 1000)
}
// 处理售卖金额信息
let oldData = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
for(let i=0, len=formatedAddData.length; i<len; i++){
let isNewProduct = true;
for(let j=0, len2=oldData.length; j<len2; j++){
if(formatedAddData[i].productId === oldData[j].productId){
isNewProduct = false;
}
}
if(isNewProduct){
oldData.push(formatedAddData[i]);
}
}
fs.writeFileSync('data/prod.json', JSON.stringify(oldData));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`理财列表ajax接口爬取完毕,时间:${time}`).warn);
if(!pageUrls.length){
delay = 32*1000;
clearInterval(timer);
timer = setInterval(function(){
requestData();
}, delay);
return
}
getDetailData();
});
}The code is very long, and the getDetailData function code will be analyzed later.
The ajax interface requested is a paging interface, because generally the total number of products on sale will not exceed 10. We set the parameter pageSize here to 100, so that all products can be obtained at one time.
clearProd is a global reset signal. At 0 o'clock every day, the prod (regular product) and user (home page user) data will be cleared.
Because sometimes there are fewer products that are rushed to buy, such as at 10 o'clock every day, so the data will be updated quickly at 10 o'clock every day. We must increase the frequency of crawling to prevent data loss. Therefore, for pre-sale products, that is, buyStartTime is greater than the current time, we need to record it and set a timer. When the sale starts, adjust the crawling frequency to 1 time/second, see the setPreId method.
If there are no products for sale, that is, pageUrls is empty, we will set the frequency of crawling to a maximum of 32 seconds.
This part of the code of the requestData function mainly records whether there are new products. If so, create a new object, record the product information, and push it to the prod array. The data structure of prod.json is as follows:
[{
"productName": "立马聚财-12月期HLB01230901",
"financeTotalAmount": 1000000,
"productId": "201801151830PD84123120",
"yearReturnRate": 6.4,
"investementDays": 364,
"interestStartTime": "2018年01月23日",
"interestEndTime": "2019年01月22日",
"getDataTime": 1516118401299,
"alreadyBuyAmount": 875000,
"records": [
{
"username": "刘**",
"buyTime": 1516117093472,
"buyAmount": 30000,
"uniqueId": "刘**151611709347230,000元"
},
{
"username": "刘**",
"buyTime": 1516116780799,
"buyAmount": 50000,
"uniqueId": "刘**151611678079950,000元"
}]
}]is an array of objects, each object represents a new product, and the records attribute records sales information.
Let’s take a look at the getDetailData code:
function getDetailData(){
// 请求用户信息接口,来判断登录是否还有效,在产品详情页判断麻烦还要造成五次登录请求
superagent
.post('https://www.lmlc.com/s/web/m/user_info')
.set('Cookie', cookie)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
let retcode = JSON.parse(pres.text).retcode;
if(retcode === 410){
handleErr('登陆cookie已失效,尝试重新登陆...');
getCookie();
return;
}
var reptileLink = function(url,callback){
// 如果爬取页面有限制爬取次数,这里可设置延迟
console.log( '正在爬取产品详情页面:' + url);
superagent
.get(url)
.set('Cookie', cookie)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
var $ = cheerio.load(pres.text);
var records = [];
var $table = $('.buy-records table');
if(!$table.length){
$table = $('.tabcontent table');
}
var $tr = $table.find('tr').slice(1);
$tr.each(function(){
records.push({
username: $('td', $(this)).eq(0).text(),
buyTime: parseInt($('td', $(this)).eq(1).attr('data-time').replace(/,/g, '')),
buyAmount: parseFloat($('td', $(this)).eq(2).text().replace(/,/g, '')),
uniqueId: $('td', $(this)).eq(0).text() + $('td', $(this)).eq(1).attr('data-time').replace(/,/g, '') + $('td', $(this)).eq(2).text()
})
});
callback(null, {
productId: url.split('?id=')[1],
records: records
});
});
};
async.mapLimit(pageUrls, 10 ,function (url, callback) {
reptileLink(url, callback);
}, function (err,result) {
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log(`所有产品详情页爬取完毕,时间:${time}`.info);
let oldRecord = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
let counts = [];
for(let i=0,len=result.length; i<len; i++){
for(let j=0,len2=oldRecord.length; j<len2; j++){
if(result[i].productId === oldRecord[j].productId){
let count = 0;
let newRecords = [];
for(let k=0,len3=result[i].records.length; k<len3; k++){
let isNewRec = true;
for(let m=0,len4=oldRecord[j].records.length; m<len4; m++){
if(result[i].records[k].uniqueId === oldRecord[j].records[m].uniqueId){
isNewRec = false;
}
}
if(isNewRec){
count++;
newRecords.push(result[i].records[k]);
}
}
oldRecord[j].records = oldRecord[j].records.concat(newRecords);
counts.push(count);
}
}
}
let oldDelay = delay;
delay = getNewDelay(delay, counts);
function getNewDelay(delay, counts){
let nowDate = (new Date()).toLocaleDateString();
let time1 = Date.parse(nowDate + ' 00:00:00');
let time2 = +new Date();
// 根据这次更新情况,来动态设置爬取频次
let maxNum = Math.max(...counts);
if(maxNum >=0 && maxNum <= 2){
delay = delay + 1000;
}
if(maxNum >=8 && maxNum <= 10){
delay = delay/2;
}
// 每天0点,prod数据清空,排除这个情况
if(maxNum == 10 && (time2 - time1 >= 60*1000)){
handleErr('部分数据可能丢失!');
}
if(delay <= 1000){
delay = 1000;
}
if(delay >= 32*1000){
delay = 32*1000;
}
return delay
}
if(oldDelay != delay){
clearInterval(timer);
timer = setInterval(function(){
requestData();
}, delay);
}
fs.writeFileSync('data/prod.json', JSON.stringify(oldRecord));
})
});
}We first request the user information interface to determine whether the login is still valid. Because it is troublesome to judge on the product details page, it will cause five login requests. Requesting with a cookie is very simple. Just set the cookie we got before after the post: .set('Cookie', cookie). If the retcode returned by the background is 410, it means that the login cookie has expired and you need to execute getCookie() again. This will ensure that the crawler is always logged in.
The mapLimit method of async will make concurrent requests for pageUrls, with a concurrency of 10 at a time. The reptileLink method will be executed for each pageUrl. Wait until all asynchronous execution is completed before executing the callback function. The result parameter of the callback function is an array composed of the data returned by each reptileLink function.
The reptileLink function is to obtain the investment record list information of the product details page. uniqueId is a string composed of the known username, buyTime, and buyAmount parameters, which is used to eliminate duplicates.
The callback of async is mainly to write the latest investment record information into the corresponding product object, and at the same time generate a counts array. The counts array is an array consisting of the number of new sales records for each product crawled this time, and is passed into the getNewDelay function together with delay. getNewDelay dynamically adjusts the crawling frequency, and counts are the only basis for adjusting delay. If the delay is too large, it may cause data loss; if it is too small, it will increase the burden on the server, and the administrator may block the IP address. Here, the maximum value of delay is set to 32, and the minimum value is 1.
First enter the code:
function requestData1() {
superagent.get(ajaxUrl1)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
let newData = JSON.parse(pres.text).data;
let formatNewData = formatData1(newData);
// 在这里清空数据,避免一个文件被同时写入
if(clearUser){
fs.writeFileSync('data/user.json', '');
clearUser = false;
}
let data = fs.readFileSync('data/user.json', 'utf-8');
if(!data){
fs.writeFileSync('data/user.json', JSON.stringify(formatNewData));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`首页用户购买ajax爬取完毕,时间:${time}`).silly);
}else{
let oldData = JSON.parse(data);
let addData = [];
// 排重算法,如果uniqueId不一样那肯定是新生成的,否则看时间差如果是0(三分钟内请求多次)或者三分钟则是旧数据
for(let i=0, len=formatNewData.length; i<len; i++){
let matchArr = [];
for(let len2=oldData.length, j=Math.max(0,len2 - 20); j<len2; j++){
if(formatNewData[i].uniqueId === oldData[j].uniqueId){
matchArr.push(j);
}
}
if(matchArr.length === 0){
addData.push(formatNewData[i]);
}else{
let isNewBuy = true;
for(let k=0, len3=matchArr.length; k<len3; k++){
let delta = formatNewData[i].time - oldData[matchArr[k]].time;
if(delta == 0 || (Math.abs(delta - 3*60*1000) < 1000)){
isNewBuy = false;
// 更新时间,这样下一次判断还是三分钟
oldData[matchArr[k]].time = formatNewData[i].time;
}
}
if(isNewBuy){
addData.push(formatNewData[i]);
}
}
}
fs.writeFileSync('data/user.json', JSON.stringify(oldData.concat(addData)));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`首页用户购买ajax爬取完毕,时间:${time}`).silly);
}
});
}The crawling of user.js is similar to prod.js. Here I mainly want to talk about how to eliminate duplicates. of. The user.json data format is as follows:
[
{
"payAmount": 5067.31,
"productId": "jsfund",
"productName": "立马金库",
"productType": 6,
"time": 1548489,
"username": "郑**",
"buyTime": 1516118397758,
"uniqueId": "5067.31jsfund郑**"
}, {
"payAmount": 30000,
"productId": "201801151830PD84123120",
"productName": "立马聚财-12月期HLB01230901",
"productType": 0,
"time": 1306573,
"username": "刘**",
"buyTime": 1516117199684,
"uniqueId": "30000201801151830PD84123120刘**"
}]和产品详情页类似,我们也生成一个uniqueId参数用来排除,它是payAmount、productId、username参数的拼成的字符串。如果uniqueId不一样,那肯定是一条新的记录。如果相同那一定是一条新记录吗?答案是否定的。因为这个接口数据是三分钟更新一次,而且给出的时间是相对时间,即数据更新时的时间减去购买的时间。所以每次更新后,即使是同一条记录,时间也会不一样。那如何排重呢?其实很简单,如果uniqueId一样,我们就判断这个buyTime,如果buyTime的差正好接近180s,那么几乎可以肯定是旧数据。如果同一个人正好在三分钟后购买同一个产品相同的金额那我也没辙了,哈哈。
每天零点我们需要整理user.json和prod.json数据,生成最终的数据。代码:
let globalTimer = setInterval(function(){
let nowTime = +new Date();
let nowStr = (new Date()).format("hh:mm:ss");
let max = nowTime;
let min = nowTime - 24*60*60*1000;
// 每天00:00分的时候写入当天的数据
if(nowStr === "00:00:00"){
// 先保存数据
let prod = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
let user = JSON.parse(fs.readFileSync('data/user.json', 'utf-8'));
let lmlc = JSON.parse(JSON.stringify(prod));
// 清空缓存数据
clearProd = true;
clearUser = true;
// 不足一天的不统计
// if(nowTime - initialTime < 24*60*60*1000) return
// 筛选prod.records数据
for(let i=0, len=prod.length; i<len; i++){
let delArr1 = [];
for(let j=0, len2=prod[i].records.length; j<len2; j++){
if(prod[i].records[j].buyTime < min || prod[i].records[j].buyTime >= max){
delArr1.push(j);
}
}
sort.delArrByIndex(lmlc[i].records, delArr1);
}
// 删掉prod.records为空的数据
let delArr2 = [];
for(let i=0, len=lmlc.length; i<len; i++){
if(!lmlc[i].records.length){
delArr2.push(i);
}
}
sort.delArrByIndex(lmlc, delArr2);
// 初始化lmlc里的立马金库数据
lmlc.unshift({
"productName": "立马金库",
"financeTotalAmount": 100000000,
"productId": "jsfund",
"yearReturnRate": 4.0,
"investementDays": 1,
"interestStartTime": (new Date(min)).format("yyyy年MM月dd日"),
"interestEndTime": (new Date(max)).format("yyyy年MM月dd日"),
"getDataTime": min,
"alreadyBuyAmount": 0,
"records": []
});
// 筛选user数据
for(let i=0, len=user.length; i<len; i++){
if(user[i].productId === "jsfund" && user[i].buyTime >= min && user[i].buyTime < max){
lmlc[0].records.push({
"username": user[i].username,
"buyTime": user[i].buyTime,
"buyAmount": user[i].payAmount,
});
}
}
// 删除无用属性,按照时间排序
lmlc[0].records.sort(function(a,b){return a.buyTime - b.buyTime});
for(let i=1, len=lmlc.length; i<len; i++){
lmlc[i].records.sort(function(a,b){return a.buyTime - b.buyTime});
for(let j=0, len2=lmlc[i].records.length; j<len2; j++){
delete lmlc[i].records[j].uniqueId
}
}
// 爬取金库收益,写入前一天的数据,清空user.json和prod.json
let dateStr = (new Date(nowTime - 10*60*1000)).format("yyyyMMdd");
superagent
.get('https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=1')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
var data = JSON.parse(pres.text).data;
var rate = data.result[0].yearReturnRate||4.0;
lmlc[0].yearReturnRate = rate;
fs.writeFileSync(`data/${dateStr}.json`, JSON.stringify(lmlc));
})
}
}, 1000);globalTimer是个全局定时器,每隔1s执行一次,当时间为00:00:00时,clearProd和clearUser全局参数为true,这样在下次爬取过程时会清空user.json和prod.json文件。没有同步清空是因为防止多处同时修改同一文件报错。取出user.json里的所有金库记录,获取当天金库相关信息,生成一条立马金库的prod信息并unshift进prod.json里。删除一些无用属性,排序数组最终生成带有当天时间戳的json文件,如:20180101.json。
前端总共就两个页面,首页和详情页,首页主要展示实时销售额、某一时间段内的销售情况、具体某天的销售情况。详情页展示某天的具体某一产品销售情况。页面有两个入口,而且比较简单,这里我们采用gulp来打包压缩构建前端工程。后台用express搭建的,匹配到路由,从data文件夹里取到数据再分析处理再返回给前端。
Echarts
Echarts是一个绘图利器,百度公司不可多得的良心之作。能方便的绘制各种图形,官网已经更新到4.0了,功能更加强大。我们这里主要用到的是直方图。
DataTables
Datatables是一款jquery表格插件。它是一个高度灵活的工具,可以将任何HTML表格添加高级的交互功能。功能非常强大,有丰富的API,大家可以去官网学习。
Datepicker
Datepicker是一款基于jquery的日期选择器,需要的功能基本都有,主要样式比较好看,比jqueryUI官网的Datepicker好看太多。
gulp配置比较简单,代码如下:
var gulp = require('gulp');
var uglify = require("gulp-uglify");
var less = require("gulp-less");
var minifyCss = require("gulp-minify-css");
var livereload = require('gulp-livereload');
var connect = require('gulp-connect');
var minimist = require('minimist');
var babel = require('gulp-babel');
var knownOptions = {
string: 'env',
default: { env: process.env.NODE_ENV || 'production' }
};
var options = minimist(process.argv.slice(2), knownOptions);
// js文件压缩
gulp.task('minify-js', function() {
gulp.src('src/js/*.js')
.pipe(babel({
presets: ['es2015']
}))
.pipe(uglify())
.pipe(gulp.dest('dist/'));
});
// js移动文件
gulp.task('move-js', function() {
gulp.src('src/js/*.js')
.pipe(babel({
presets: ['es2015']
}))
.pipe(gulp.dest('dist/'))
.pipe(connect.reload());
});
// less编译
gulp.task('compile-less', function() {
gulp.src('src/css/*.less')
.pipe(less())
.pipe(gulp.dest('dist/'))
.pipe(connect.reload());
});
// less文件编译压缩
gulp.task('compile-minify-css', function() {
gulp.src('src/css/*.less')
.pipe(less())
.pipe(minifyCss())
.pipe(gulp.dest('dist/'));
});
// html页面自动刷新
gulp.task('html', function () {
gulp.src('views/*.html')
.pipe(connect.reload());
});
// 页面自动刷新启动
gulp.task('connect', function() {
connect.server({
livereload: true
});
});
// 监测文件的改动
gulp.task('watch', function() {
gulp.watch('src/css/*.less', ['compile-less']);
gulp.watch('src/js/*.js', ['move-js']);
gulp.watch('views/*.html', ['html']);
});
// 激活浏览器livereload友好提示
gulp.task('tip', function() {
console.log('\n<----- 请用chrome浏览器打开 http://localhost:5000 页面,并激活livereload插件 ----->\n');
});
if (options.env === 'development') {
gulp.task('default', ['move-js', 'compile-less', 'connect', 'watch', 'tip']);
}else{
gulp.task('default', ['minify-js', 'compile-minify-css']);
}开发和生产环境都是将文件打包到dist目录。不同的是:开发环境只是编译es6和less文件;生产环境会再压缩混淆。支持livereload插件,在开发环境下,文件改动会自动刷新页面。
相关推荐:
The above is the detailed content of Detailed explanation of NodeJS crawler. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



