

To understand the running mechanism of JavaScript, you need to have a deep understanding of several points: JavaScript's single-thread mechanism, task queue (synchronous tasks and asynchronous tasks), events and callback functions, timers, and Event Loop.
One of the language features of JavaScript (also the core of this language) is the single-threaded. Simply put, a single thread means that can only do one thing at the same time. When there are multiple tasks, they can only be completed in one order before executing the next one.
JavaScript's single thread is related to its language purpose. As a browser scripting language, the main purpose of JavaScript is to complete user interaction and operate the DOM. This determines that it can only be single-threaded, otherwise it will cause complex synchronization problems.
Imagine that JavaScript has two threads at the same time. One thread needs to add content to a certain DOM node, and the operation of the other thread is to delete the node. So who should the browser use as the criterion? ?
So in order to avoid complexity, JavaScript has been single-threaded since its birth.
In order to improve CPU utilization, HTML5 proposes the Web Worker standard, which allows JavaScript scripts to create multiple threads, but the child threads are completely controlled by the main thread and are not allowed to operate the DOM. So this standard does not change the single-threaded nature of JavaScript.
Completing tasks one after another means that the tasks to be completed need to be queued, so why do they need to be queued?
Usually there are two reasons for queuing:
The task calculation amount is too large and the CPU is busy;
Task The required things are not ready so execution cannot continue, causing the CPU to idle, waiting for input and output devices (I/O devices).
For example, for some tasks you need Ajax to obtain data before executing it
From this, the designers of JavaScript also realized that at this time, it is completely possible to run the tasks that are ready later to improve the operating efficiency, that is, to suspend the waiting tasks and put them aside, and then execute them after getting what is needed. It's like when the other party leaves for a moment when you answer the phone, another call comes in, so you hang up the current call, wait for that call to end, and then connect back to the previous call.
Therefore, the concepts of synchronization and asynchronous appeared, and tasks were divided into two types, one is synchronous task (Synchronous) and the other is asynchronous task (Asynchronous).
Synchronous tasks: Tasks that need to be executed are queued on the main thread, one after another. After the previous one is completed, the next one will be executed
Asynchronously Task: Tasks that are not executed immediately but need to be executed are stored in the "task queue". The "task queue" will notify the main thread when which asynchronous task can be executed, and then the task will enter the main thread and be executed. implement.
All synchronous execution can be regarded as asynchronous execution without asynchronous tasks
Specifically, asynchronous execution is as follows:
(1) All synchronous tasks are executed on the main thread, forming an execution context stack (execution context stack).
That is, all tasks that can be executed immediately are queued on the main thread and executed one after another.
# (2) In addition to the main thread, there is also a "task queue". As long as the asynchronous task has running results, an event is placed in the "task queue".
That is to say, each asynchronous task will set a unique flag when it is ready. This flag is used to identify the corresponding asynchronous task.
(3) Once all synchronization tasks in the "execution stack" are completed, the system will read the "task queue" to see what events are in it. Those corresponding asynchronous tasks end the waiting state and enter the execution stack to begin execution.
That is, after the main thread completes the previous task, it will look at the flag in the "task queue" to package the corresponding asynchronous task for execution.
(4) The main thread continues to repeat the above three steps.
As long as the main thread is empty, it will read the "task queue". This process will be repeated over and over again. This is how JavaScript works.
How do you know that the main thread execution stack is empty? There is a monitoring process in the js engine, which will continuously check whether the main thread execution stack is empty. Once it is empty, it will go to the Event Queue to check whether there is a function waiting to be called.
The following uses a
guide to illustrate the main thread and task queue.

If the content of the map is expressed in words:
Synchronous and asynchronous tasks enter different execution "places" respectively, synchronously entering the main thread, and asynchronously entering the Event Table and registering functions.
When the specified thing is completed, the Event Table will move this function into the Event Queue.
The task in the main thread is empty after execution. It will go to the Event Queue to read the corresponding function and enter the main thread for execution.
The above process will be repeated continuously, which is often called Event Loop.
"Task queue" is an event queue (can also be understood as a message queue), IO When the device completes a task, an event will be added to the "task queue", indicating that the related asynchronous tasks can enter the "execution stack". Then the main thread reads the "task queue" to see what events are in it.
The events in the "Task Queue", in addition to IO device events, also include some user-generated events (such as mouse clicks, page scrolling, etc.). As long as the callback function is specified, these events will enter the "task queue" when they occur, waiting for the main thread to read.
The so-called "callback function" (callback) is the code that will be hung up by the main thread. Asynchronous tasks must specify a callback function. When the main thread starts executing an asynchronous task, the corresponding callback function is executed.
"Task queue" is a first-in, first-out data structure. The events ranked first are read by the main thread first. The reading process of the main thread is basically automatic. As soon as the execution stack is cleared, the first event on the "task queue" will automatically enter the main thread. However, if a "timer" is included, the main thread must first check the execution time. Certain events can only return to the main thread after the specified time.
The main thread reads events from the "task queue". This process is continuous, so the entire operating mechanism is also called "Event Loop" (event loop).
In order to better understand Event Loop, let’s refer to a picture in Philip Roberts’ speech.
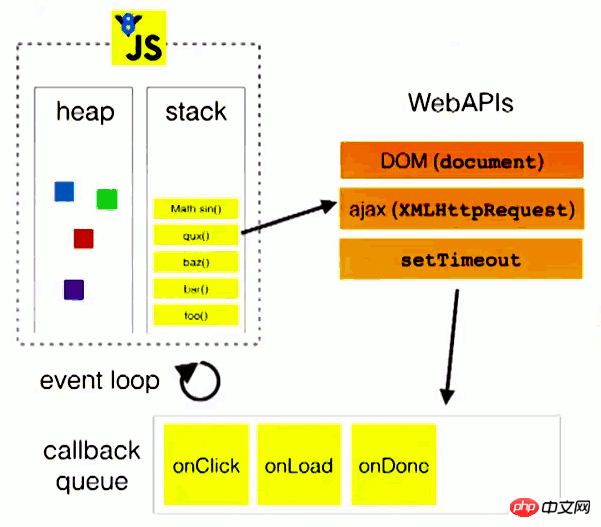
In the above figure, when the main thread is running, it generates a heap (heap) and a stack (stack). The code in the stack calls various external APIs, and in " Various events (click, load, done) are added to the "Task Queue". When the code in the stack is executed, the main thread will read the "task queue" and execute the callback functions corresponding to those events in sequence.
The code in the execution stack (synchronous task) is always executed before reading the "task queue" (asynchronous task).
let data = [];
$.ajax({ url:www.javascript.com, data:data, success:() => { console.log('发送成功!');
}
})console.log('代码执行结束');The above is a simple ajax request code:
ajax enters the Event Table and registers the callback function success.
Execution console.log('Code execution ends').
ajax event is completed, the callback function success enters the Event Queue.
The main thread reads the callback function success from the Event Queue and executes it.
In addition to placing events for asynchronous tasks, the "task queue" can also place timed events, that is, specifying how much time certain code will be executed after. This is called the timer function, which is code that is executed regularly.
SetTimeout() and setInterval() can be used to register functions that are called once or repeatedly after a specified time. Their internal operating mechanisms are exactly the same. The difference The code specified by the former is executed once, while the latter will be called repeatedly at intervals of specified milliseconds:
setInterval(updateClock, 60000); //60秒调用一次updateClock()
Because they are important global functions in client-side JavaScript, they are defined as methods of the Window object .
But as a general function, it will not actually do anything to the window.
The setTImeout() method of the Window object is used to implement a function that runs after a specified number of milliseconds. So it accepts two parameters, the first is the callback function and the second is the number of milliseconds to defer execution. setTimeout() and setInterval() return a value, which can be passed to clearTimeout() to cancel the execution of this function.
console.log(1);
setTimeout(function(){console.log(2);}, 1000);console.log(3);The execution results of the above code are 1, 3, 2, because setTimeout() delays the execution of the second line until 1000 milliseconds later.
If the second parameter of setTimeout() is set to 0, it means that after the current code is executed (the execution stack is cleared), the specified callback function will be executed immediately (0 millisecond interval) .
setTimeout(function(){console.log(1);}, 0);console.log(2)The execution result of the above code is always 2, 1, because the system will execute the callback function in the "task queue" only after the second line is executed.
In short, setTimeout(fn,0) means to specify a task to be executed in the earliest available idle time of the main thread, that is, to be executed as early as possible. It adds an event at the end of the "task queue", so it will not be executed until the synchronization task and the existing events in the "task queue" have been processed.
HTML5标准规定了
setTimeout()的第二个参数的最小值(最短间隔),不得低于4毫秒,如果低于这个值,就会自动增加。
需要注意的是,setTimeout()只是将事件插入了“任务队列”,必须等到当前代码(执行栈)执行完,主线程才会去执行它指定的回调函数。要是当前代码耗时很长,有可能要等很久,所以并没有办法保证回调函数一定会在setTimeout()指定的时间执行。
由于历史原因,setTimeout()和setInterval()的第一个参数可以作为字符串传入。如果这么做,那这个字符串会在指定的超时时间或间隔之后进行求值(相当于执行eval())。
Node.js也是单线程的Event Loop,但是它的运行机制不同于浏览器环境。
Node.js的运行机制如下。
(1)V8引擎解析JavaScript脚本。
(2)解析后的代码,调用Node API。
(3)libuv库负责Node API的执行。它将不同的任务分配给不同的线程,形成一个Event Loop(事件循环),以异步的方式将任务的执行结果返回给V8引擎。
(4)V8引擎再将结果返回给用户。
除了setTimeout和setInterval这两个方法,Node.js还提供了另外两个与”任务队列”有关的方法:process.nextTick和setImmediate。它们可以帮助我们加深对”任务队列”的理解。
process.nextTick方法可以在当前”执行栈”的尾部—-下一次Event Loop(主线程读取”任务队列”)之前—-触发回调函数。也就是说,它指定的任务总是发生在所有异步任务之前。setImmediate方法则是在当前”任务队列”的尾部添加事件,也就是说,它指定的任务总是在下一次Event Loop时执行,这与setTimeout(fn, 0)很像。请看下面的例子
process.nextTick(function A() {console.log(1);process.nextTick(function B(){console.log(2);});});
setTimeout(function timeout() {console.log('TIMEOUT FIRED');
}, 0)// 1// 2// TIMEOUT FIRED上面代码中,由于process.nextTick方法指定的回调函数,总是在当前”执行栈”的尾部触发,所以不仅函数A比setTimeout指定的回调函数timeout先执行,而且函数B也比timeout先执行。这说明,如果有多个process.nextTick语句(不管它们是否嵌套),将全部在当前”执行栈”执行。
现在,再看setImmediate。
setImmediate(function A() {console.log(1);
setImmediate(function B(){console.log(2);});});
setTimeout(function timeout() {console.log('TIMEOUT FIRED');
}, 0);上面代码中,setImmediate与setTimeout(fn,0)各自添加了一个回调函数A和timeout,都是在下一次Event Loop触发。那么,哪个回调函数先执行呢?答案是不确定。运行结果可能是1–TIMEOUT FIRED–2,也可能是TIMEOUT FIRED–1–2。
令人困惑的是,Node.js文档中称,setImmediate指定的回调函数,总是排在setTimeout前面。实际上,这种情况只发生在递归调用的时候。
setImmediate(function (){setImmediate(function A() {console.log(1);
setImmediate(function B(){console.log(2);});});
setTimeout(function timeout() {console.log('TIMEOUT FIRED');
}, 0);
});
// 1 // TIMEOUT FIRED // 2上面代码中,setImmediate和setTimeout被封装在一个setImmediate里面,它的运行结果总是1–TIMEOUT FIRED–2,这时函数A一定在timeout前面触发。至于2排在TIMEOUT FIRED的后面(即函数B在timeout后面触发),是因为setImmediate总是将事件注册到下一轮Event Loop,所以函数A和timeout是在同一轮Loop执行,而函数B在下一轮Loop执行。
我们由此得到了process.nextTick和setImmediate的一个重要区别:多个process.nextTick语句总是在当前”执行栈”一次执行完,多个setImmediate可能则需要多次loop才能执行完。事实上,这正是Node.js 10.0版添加setImmediate方法的原因,否则像下面这样的递归调用process.nextTick,将会没完没了,主线程根本不会去读取”事件队列”!
process.nextTick(function foo() {process.nextTick(foo);
});事实上,现在要是你写出递归的process.nextTick,Node.js会抛出一个警告,要求你改成setImmediate。
另外,由于process.nextTick指定的回调函数是在本次”事件循环”触发,而setImmediate指定的是在下次”事件循环”触发,所以很显然,前者总是比后者发生得早,而且执行效率也高(因为不用检查”任务队列”)。
除了广义的同步任务和异步任务,任务还有更精细的定义:
macro-task(宏任务):包括整体代码script,setTimeout,setInterval
micro-task(微任务):Promise,process.nextTick
事件循环,宏任务,微任务的关系如图所示:
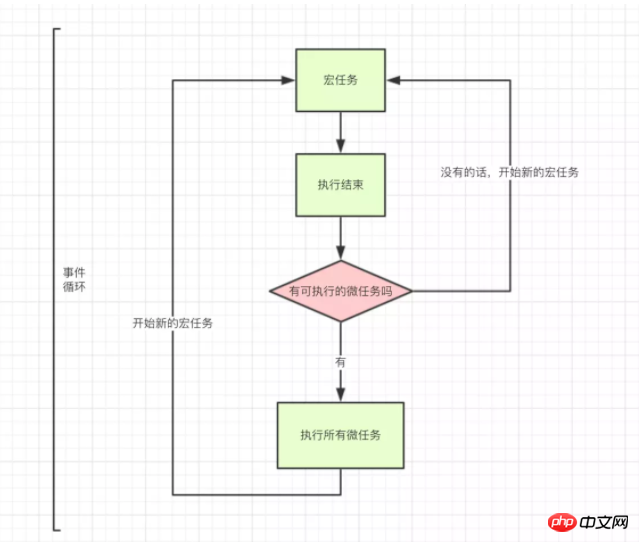
按照宏任务和微任务这种分类方式,JS的执行机制是
执行一个宏任务,过程中如果遇到微任务,就将其放到微任务的【事件队列】里
当前宏任务执行完成后,会查看微任务的【事件队列】,并将里面全部的微任务依次执行完
请看下面的例子:
setTimeout(function(){
console.log('定时器开始啦')
});
new Promise(function(resolve){
console.log('马上执行for循环啦'); for(var i = 0; i < 10000; i++){
i == 99 && resolve();
}
}).then(function(){
console.log('执行then函数啦')
}); console.log('代码执行结束');首先执行script下的宏任务,遇到setTimeout,将其放到宏任务的【队列】里
遇到 new Promise直接执行,打印”马上执行for循环啦”
遇到then方法,是微任务,将其放到微任务的【队列里】
打印 “代码执行结束”
本轮宏任务执行完毕,查看本轮的微任务,发现有一个then方法里的函数, 打印”执行then函数啦”
到此,本轮的event loop 全部完成。
下一轮的循环里,先执行一个宏任务,发现宏任务的【队列】里有一个 setTimeout里的函数,执行打印”定时器开始啦”
所以最后的执行顺序是【马上执行for循环啦 — 代码执行结束 — 执行then函数啦 — 定时器开始啦】
我们来分析一段较复杂的代码,看看你是否真的掌握了js的执行机制:
console.log('1');
setTimeout(function() {
console.log('2'); process.nextTick(function() {
console.log('3');
})
new Promise(function(resolve) {
console.log('4');
resolve();
}).then(function() {
console.log('5')
})
})process.nextTick(function() {
console.log('6');
})
new Promise(function(resolve) {
console.log('7');
resolve();
}).then(function() {
console.log('8')
})
setTimeout(function() {
console.log('9'); process.nextTick(function() {
console.log('10');
})
new Promise(function(resolve) {
console.log('11');
resolve();
}).then(function() {
console.log('12')
})
})第一轮事件循环流程分析如下:
整体script作为第一个宏任务进入主线程,遇到console.log,输出1。
遇到setTimeout,其回调函数被分发到宏任务Event Queue中。我们暂且记为setTimeout1。
遇到process.nextTick(),其回调函数被分发到微任务Event Queue中。我们记为process1。
遇到Promise,new Promise直接执行,输出7。then被分发到微任务Event Queue中。我们记为then1。
又遇到了setTimeout,其回调函数被分发到宏任务Event Queue中,我们记为setTimeout2。
| 宏任务Event Queue | 微任务Event Queue |
|---|---|
| setTimeout1 | process1 |
| setTimeout2 | then1 |
* 上表是第一轮事件循环宏任务结束时各Event Queue的情况,此时已经输出了1和7。
我们发现了process1和then1两个微任务。
执行process1,输出6。
执行then1,输出8。
好了,第一轮事件循环正式结束,这一轮的结果是输出1,7,6,8。那么第二轮时间循环从setTimeout1宏任务开始:
首先输出2。接下来遇到了process.nextTick(),同样将其分发到微任务Event Queue中,记为process2。new Promise立即执行输出4,then也分发到微任务Event Queue中,记为then2。
| 宏任务Event Queue | 微任务Event Queue |
|---|---|
| setTimeout2 | process2 |
| then2 |
* 第二轮事件循环宏任务结束,我们发现有process2和then2两个微任务可以执行。
* 输出3。
* 输出5。
* 第二轮事件循环结束,第二轮输出2,4,3,5。
* 第三轮事件循环开始,此时只剩setTimeout2了,执行。
* 直接输出9。
* 将process.nextTick()分发到微任务Event Queue中。记为process3。
* 直接执行new Promise,输出11。
* 将then分发到微任务Event Queue中,记为then3。
| 宏任务Event Queue | 微任务Event Queue |
|---|---|
| process3 | |
| then3 |
* 第三轮事件循环宏任务执行结束,执行两个微任务process3和then3。
* 输出10。
* 输出12。
* 第三轮事件循环结束,第三轮输出9,11,10,12。
整段代码,共进行了三次事件循环,完整的输出为1,7,6,8,2,4,3,5,9,11,10,12。
(请注意,node环境下的事件监听依赖libuv与前端环境不完全相同,输出顺序可能会有误差)
The above is the detailed content of Detailed explanation of js execution mechanism examples. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



