
This article mainly introduces the example of Node Puppeteer image recognition to implement Baidu index crawler. The editor thinks it is quite good. Now I will share it with you and give it as a reference. Let’s follow the editor and take a look.
I have read an enlightening article before, which introduced the front-end anti-crawler techniques of various major manufacturers, but as this article said, there is no 100% anti-crawler. Crawler method, this article introduces a simple method to bypass all these front-end anti-crawler methods.
The following code takes Baidu Index as an example. The code has been packaged into a Baidu Index crawler node library: https://github.com/Coffcer/baidu-index-spider
note: Please do not abuse crawlers to cause trouble to others
Baidu Index’s anti-crawler strategy
Observe the interface of Baidu Index. The index data is a trend chart. When the mouse hovers over a certain day, two requests will be triggered and the results will be displayed in the floating box:
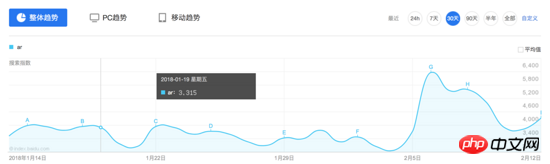
According to the general idea, let’s first look at the content of this request. :
Request 1:
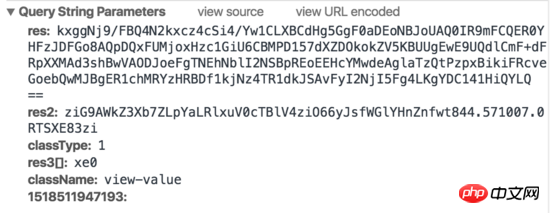
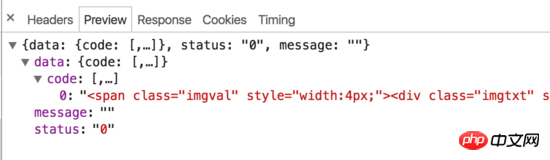
Request 2:

Reptile Ideas
How to break through Baidu’s anti-reptile method is actually very simple, just don’t pay attention to how it anti-reptile. We only need to simulate user operations, screenshot the required values, and do image recognition. The steps are probably:puppeteer Simulate browser operation
tesseract Encapsulation, used for image recognition
Image cropping
Puppeteer is a Chrome automation tool produced by the Google Chrome team, used to control Chrome execution commands. You can simulate user operations, do automated testing, crawlers, etc. Usage is very simple. There are many introductory tutorials on the Internet. You can probably know how to use it after reading this article.
API documentation: https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md
Installation:
npm install --save puppeteer
Puppeteer will Automatically download Chromium to ensure it works properly. However, domestic networks may not be able to successfully download Chromium. If the download fails, you can use cnpm to install it, or change the download address to the Taobao mirror and then install it:
npm config set PUPPETEER_DOWNLOAD_HOST=https://npm.taobao.org/mirrors npm install --save puppeteer
You can also skip Chromium during installation. Download and run by specifying the native Chrome path through the code:
// npm
npm install --save puppeteer --ignore-scripts
// node
puppeteer.launch({ executablePath: '/path/to/Chrome' });To keep the layout tidy, only the main parts are listed below, and the code involves the selector part All used... instead. For the complete code, please see the github repository at the top of the article.
Open the Baidu Index page and simulate loginWhat we do here is to simulate user operations, click and enter step by step. There is no need to handle the login verification code. Handling the verification code is another topic. If you have logged into Baidu locally, you generally do not need a verification code.
// 启动浏览器,
// headless参数如果设置为true,Puppeteer将在后台操作你Chromium,换言之你将看不到浏览器的操作过程
// 设为false则相反,会在你电脑上打开浏览器,显示浏览器每一操作。
const browser = await puppeteer.launch({headless:false});
const page = await browser.newPage();
// 打开百度指数
await page.goto(BAIDU_INDEX_URL);
// 模拟登陆
await page.click('...');
await page.waitForSelecto('...');
// 输入百度账号密码然后登录
await page.type('...','username');
await page.type('...','password');
await page.click('...');
await page.waitForNavigation();
console.log(':white_check_mark: 登录成功');You need to scroll the page to the trend chart area, then move the mouse to a certain date and wait for the request to end. The tooltip displays the value, and then takes a screenshot to save the image.
// 获取chart第一天的坐标
const position = await page.evaluate(() => {
const $image = document.querySelector('...');
const $area = document.querySelector('...');
const areaRect = $area.getBoundingClientRect();
const imageRect = $image.getBoundingClientRect();
// 滚动到图表可视化区域
window.scrollBy(0, areaRect.top);
return { x: imageRect.x, y: 200 };
});
// 移动鼠标,触发tooltip
await page.mouse.move(position.x, position.y);
await page.waitForSelector('...');
// 获取tooltip信息
const tooltipInfo = await page.evaluate(() => {
const $tooltip = document.querySelector('...');
const $title = $tooltip.querySelector('...');
const $value = $tooltip.querySelector('...');
const valueRect = $value.getBoundingClientRect();
const padding = 5;
return {
title: $title.textContent.split(' ')[0],
x: valueRect.x - padding,
y: valueRect.y,
width: valueRect.width + padding * 2,
height: valueRect.height
}
});Calculate the coordinates of the value, take a screenshot and use jimp to crop the image.
await page.screenshot({ path: imgPath });
// 对图片进行裁剪,只保留数字部分
const img = await jimp.read(imgPath);
await img.crop(tooltipInfo.x, tooltipInfo.y, tooltipInfo.width, tooltipInfo.height);
// 将图片放大一些,识别准确率会有提升
await img.scale(5);
await img.write(imgPath);Here we use Tesseract for image recognition. Tesseracts is an open source OCR tool from Google that is used to recognize text in images and can Improve accuracy through training. There is already a simple node package on github: node-tesseract. You need to install Tesseract first and set it to environment variables.
Tesseract.process(imgPath, (err, val) => {
if (err || val == null) {
console.error(':x: 识别失败:' + imgPath);
return;
}
console.log(val);实际上未经训练的Tesseracts识别起来会有少数几个错误,比如把9开头的数字识别成`3,这里需要通过训练去提升Tesseracts的准确率,如果识别过程出现的问题都是一样的,也可以简单通过正则去修复这些问题。
封装
实现了以上几点后,只需组合起来就可以封装成一个百度指数爬虫node库。当然还有许多优化的方法,比如批量爬取,指定天数爬取等,只要在这个基础上实现都不难了。
const recognition = require('./src/recognition');
const Spider = require('./src/spider');
module.exports = {
async run (word, options, puppeteerOptions = { headless: true }) {
const spider = new Spider({
imgDir,
...options
}, puppeteerOptions);
// 抓取数据
await spider.run(word);
// 读取抓取到的截图,做图像识别
const wordDir = path.resolve(imgDir, word);
const imgNames = fs.readdirSync(wordDir);
const result = [];
imgNames = imgNames.filter(item => path.extname(item) === '.png');
for (let i = 0; i < imgNames.length; i++) {
const imgPath = path.resolve(wordDir, imgNames[i]);
const val = await recognition.run(imgPath);
result.push(val);
}
return result;
}
}反爬虫
最后,如何抵挡这种爬虫呢,个人认为通过判断鼠标移动轨迹可能是一种方法。当然前端没有100%的反爬虫手段,我们能做的只是给爬虫增加一点难度。
上面是我整理给大家的,希望今后会对大家有帮助。
相关文章:
在Node.js中使用cheerio制作简单的网页爬虫(详细教程)
在React中使用Native如何实现自定义下拉刷新上拉加载的列表
The above is the detailed content of How to implement Baidu index crawler using Puppeteer image recognition technology. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



