

Hbase的协处理器

1.起因(Why HBase Coprocessor) HBase作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和、计数、排序等操作。比如,在旧版本的(0.92)Hbase中,统计数据表的总行数,需要使用Counter方法,执行一次MapReduce Job才能得到。虽
1.起因(Why HBase Coprocessor)
HBase作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和、计数、排序等操作。比如,在旧版本的(
2.灵感来源( Source of Inspration)
HBase协处理器的灵感来自于Jeff Dean 09年的演讲( P66-67)。它根据该演讲实现了类似于bigtable的协处理器,包括以下特性:
- 每个表服务器的任意子表都可以运行代码
- 客户端的高层调用接口(客户端能够直接访问数据表的行地址,多行读写会自动分片成多个并行的RPC调用)
- 提供一个非常灵活的、可用于建立分布式服务的数据模型
- 能够自动化扩展、负载均衡、应用请求路由
3.细节剖析(Implementation)
协处理器分两种类型,系统协处理器可以全局导入region server上的所有数据表,表协处理器即是用户可以指定一张表使用协处理器。协处理器框架为了更好支持其行为的灵活性,提供了两个不同方面的插件。一个是观察者(observer),类似于关系数据库的触发器。另一个是终端(endpoint),动态的终端有点像存储过程。
3.1观察者(Observer)
观察者的设计意图是允许用户通过插入代码来重载协处理器框架的upcall方法,而具体的事件触发的callback方法由HBase的核心代码来执行。协处理器框架处理所有的callback调用细节,协处理器自身只需要插入添加或者改变的功能。
以HBase0.92版本为例,它提供了三种观察者接口:
- RegionObserver:提供客户端的数据操纵事件钩子:Get、Put、Delete、Scan等。
- WALObserver:提供WAL相关操作钩子。
- MasterObserver:提供DDL-类型的操作钩子。如创建、删除、修改数据表等。
这些接口可以同时使用在同一个地方,按照不同优先级顺序执行.用户可以任意基于协处理器实现复杂的HBase功能层。HBase有很多种事件可以触发观察者方法,这些事件与方法从HBase0.92版本起,都会集成在HBase API中。不过这些API可能会由于各种原因有所改动,不同版本的接口改动比较大,具体参考Java Doc。
RegionObserver工作原理,如图1所示。更多关于Observer细节请参见HBaseBook的第9.6.3章节。

图1 RegionObserver工作原理
3.2终端(Endpoint)
终端是动态RPC插件的接口,它的实现代码被安装在服务器端,从而能够通过HBase RPC唤醒。客户端类库提供了非常方便的方法来调用这些动态接口,它们可以在任意时候调用一个终端,它们的实现代码会被目标region远程执行,结果会返回到终端。用户可以结合使用这些强大的插件接口,为HBase添加全新的特性。终端的使用,如下面流程所示:
- 定义一个新的protocol接口,必须继承CoprocessorProtocol.
- 实现终端接口,该实现会被导入region环境执行。
- 继承抽象类BaseEndpointCoprocessor.
- 在客户端,终端可以被两个新的HBase Client API调用 。单个region:HTableInterface.coprocessorProxy(Class
protocol, byte[] row) 。rigons区域:HTableInterface.coprocessorExec(Class protocol, byte[] startKey, byte[] endKey, Batch.Call callable)
整体的终端调用过程范例,如图2所示:
图2 终端调用过程范例
4.编程实践(Code Example)
在该实例中,我们通过计算HBase表中行数的一个实例,来真实感受协处理器 的方便和强大。在旧版的HBase我们需要编写MapReduce代码来汇总数据表中的行数,在0.92以上的版本HBase中,只需要编写客户端的代码即可实现,非常适合用在WebService的封装上。
4.1启用协处理器 Aggregation(Enable Coprocessor Aggregation)
我们有两个方法:1.启动全局aggregation,能过操纵所有的表上的数据。通过修改hbase-site.xml这个文件来实现,只需要添加如下代码:
<span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">property</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span> <span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">name</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span>hbase.coprocessor.user.region.classes<span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"></span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">name</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span> <span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">value</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span>org.apache.hadoop.hbase.coprocessor.AggregateImplementation<span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"></span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">value</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span> <span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"></span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">property</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span></span></span></span>
2.启用表aggregation,只对特定的表生效。通过HBase Shell 来实现。
(1)disable指定表。hbase> disable 'mytable'
(2)添加aggregation hbase> alter 'mytable', METHOD => 'table_att','coprocessor'=>'|org.apache.hadoop.hbase.coprocessor.AggregateImplementation||'
(3)重启指定表 hbase> enable 'mytable'
4.2统计行数代码(Code Snippet)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.coprocessor.AggregationClient;
import org.apache.hadoop.hbase.client.coprocessor.LongColumnInterpreter;
import org.apache.hadoop.hbase.coprocessor.ColumnInterpreter;
import org.apache.hadoop.hbase.util.Bytes;
public class MyAggregationClient {
private static final byte[] TABLE_NAME = Bytes.toBytes("bigtable1w");
private static final byte[] CF = Bytes.toBytes("bd");
public static void main(String[] args) throws Throwable {
Configuration customConf = new Configuration();
customConf.set("hbase.zookeeper.quorum",
"192.168.58.101");
//提高RPC通信时长
customConf.setLong("hbase.rpc.timeout", 600000);
//设置Scan缓存
customConf.setLong("hbase.client.scanner.caching", 1000);
Configuration configuration = HBaseConfiguration.create(customConf);
AggregationClient aggregationClient = new AggregationClient(
configuration);
Scan scan = new Scan();
//指定扫描列族,唯一值
scan.addFamily(CF);
//long rowCount = aggregationClient.rowCount(TABLE_NAME, null, scan);
long rowCount = aggregationClient.rowCount(TableName.valueOf("bigtable1w"), new LongColumnInterpreter(), scan);
System.out.println("row count is " + rowCount);
}
}
4.3 典型例子
协处理器其中的一个作用是使用Observer创建二级索引。先举个实际例子:
我们要查询指定店铺指定客户购买的订单,首先有一张订单详情表,它以被处理后的订单id作为rowkey;其次有一张以客户nick为rowkey的索引表,结构如下:
rowkey family
dp_id+buy_nick1 tid1:null tid2:null ...
dp_id+buy_nick2 tid3:null
...
该表可以通过Coprocessor来构建,实例代码:


- public class TestCoprocessor extends BaseRegionObserver {
- @Override
- public void prePut(final ObserverContextRegionCoprocessorEnvironment> e,
- final Put put, final WALEdit edit, final boolean writeToWAL)
- throws IOException {
- Configuration conf = new Configuration();
- HTable table = new HTable(conf, "index_table");
- ListKeyValue> kv = put.get("data".getBytes(), "name".getBytes());
- IteratorKeyValue> kvItor = kv.iterator();
- while (kvItor.hasNext()) {
- KeyValue tmp = kvItor.next();
- Put indexPut = new Put(tmp.getValue());
- indexPut.add("index".getBytes(), tmp.getRow(), Bytes.toBytes(System.currentTimeMillis()));
- table.put(indexPut);
- }
- table.close();
- }
- }
即继承BaseRegionObserver类,实现prePut方法,在插入订单详情表之前,向索引表插入索引数据。
4.4索引表的使用
先在索引表get索引表,获取tids,然后根据tids查询订单详情表。当有多个查询条件(多张索引表),根据逻辑运算符(and 、or)确定tids。
4.5使用时注意
1.索引表是一张普通的hbase表,为安全考虑需要开启Hlog记录日志。
2.索引表的rowkey最好是不可变量,避免索引表中产生大量的脏数据。
3.如上例子,column是横向扩展的(宽表),rowkey设计除了要考虑region均衡,也要考虑column数量,即表不要太宽。建议不超过3位数。
4.如上代码,一个put操作其实是先后向两张表put数据,为保证一致性,需要考虑异常处理,建议异常时重试。
4.6效率情况
put操作效率不高,如上代码,每插入一条数据需要创建一个新的索引表连接(可以使用htablepool优化),向索引表插入数据。即耗时是双倍的,对hbase的集群的压力也是双倍的。当索引表有多个时,压力会更大。
查询效率比filter高,毫秒级别,因为都是rowkey的查询。
如上是估计的效率情况,需要根据实际业务场景和集群情况而定,最好做预先测试。
4.7Coprocessor二级索引方案优劣
优点:在put压力不大、索引region均衡的情况下,查询很快。
缺点:业务性比较强,若有多个字段的查询,需要建立多张索引表,需要保证多张表的数据一致性,且在hbase的存储和内存上都会有更高的要求

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7457
7457
 15
1376
52
77
11
44
19
17
10
15
1376
52
77
11
44
19
17
10

 AMD Ryzen 9900X, 9700X, 9600X 프로세서 Cinebench R23 실행 점수 노출, 평균 10~15% 증가
Jul 29, 2024 am 11:38 AM
AMD Ryzen 9900X, 9700X, 9600X 프로세서 Cinebench R23 실행 점수 노출, 평균 10~15% 증가
Jul 29, 2024 am 11:38 AM
7월 29일 이 웹사이트의 소식에 따르면 AMD Ryzen 9000 시리즈 프로세서는 현재 JD.com에서 예약 가능합니다. 4개 모델의 첫 번째 배치가 출시되어 8월 15일에 출시될 예정입니다. 이들 프로세서의 평가 데이터는 출시 하루 전인 8월 14일에 공개될 예정이다. 그러나 일부 언론이나 기관에서는 사전에 샘플을 확보해 테스트를 시작한 바 있어 R99900X, R79700X, R59600X 프로세서의 러닝 스코어 데이터가 공개됐다. 유출되었습니다. ▲사진출처 : @9550pro 전체적으로 Zen4에서 Zen5로 전환하면 싱글코어 성능이 10~15%, 멀티코어 성능이 10~13% 정도 향상될 것으로 예상되는데, TDP는 다소 아쉽습니다. Ryzen 7000 시리즈보다 낮으며 이는 AMD의 공식 IPC 개선 데이터와도 일치합니다. 라이젠
 Jingyue 실제 측정: AMD R7 8700F, R5 8400F 코어리스 그래픽 프로세서 성능은 8700G 및 7500F와 유사합니다.
Apr 06, 2024 am 09:01 AM
Jingyue 실제 측정: AMD R7 8700F, R5 8400F 코어리스 그래픽 프로세서 성능은 8700G 및 7500F와 유사합니다.
Apr 06, 2024 am 09:01 AM
4월 5일 이 사이트의 소식에 따르면 Jingyue는 지난달 노출된 AMDR78700F 및 R58400F 코어리스 그래픽 프로세서가 중국에 특별히 공급된 모델임을 공식 확인하고 전체 네트워크에서 첫 번째 테스트 비디오를 공개하여 둘 다 코어 그래픽이 없음을 확인했습니다. TDP 구성은 모두 65W입니다. 사양으로 보면 AMD Ryzen78700F는 8코어 16스레드, 기본 주파수 4.1GHz, 가속 주파수 5.05GHz로 Ryzen78700G보다 0.10/0.05GHz 낮으며 16MB L3 캐시를 탑재하고 있습니다. AMD Ryzen58400F는 4.2~4.75GHz 주파수의 6코어 12스레드 설계를 채택했으며, R57500F 대비 기본 주파수는 0.1GHz 증가하고 가속 주파수는 0으로 감소했습니다.
 144코어, 3D 스택 SRAM: Fujitsu, 차세대 데이터 센터 프로세서 MONAKA 자세히 설명
Jul 29, 2024 am 11:40 AM
144코어, 3D 스택 SRAM: Fujitsu, 차세대 데이터 센터 프로세서 MONAKA 자세히 설명
Jul 29, 2024 am 11:40 AM
28일 본 홈페이지 소식에 따르면 외신 테크레이더(TechRader)는 후지쯔가 2027년 출하 예정인 FUJITSU-MONAKA(이하 MONAKA) 프로세서를 자세하게 소개했다고 보도했다. MONAKACPU는 "클라우드 네이티브 3D 매니코어" 아키텍처를 기반으로 하며 Arm 명령어 세트를 채택합니다. 이는 데이터 센터, 엣지 및 통신 분야를 지향하며 메인프레임 수준의 RAS1을 구현할 수 있습니다. Fujitsu는 MONAKA가 에너지 효율성과 성능의 도약을 이룰 것이라고 밝혔습니다. 초저전압(ULV) 기술 등의 기술 덕분에 CPU는 2027년에 경쟁 제품보다 2배의 에너지 효율성을 달성할 수 있으며 냉각에는 수냉이 필요하지 않습니다. ; 게다가 프로세서의 애플리케이션 성능도 상대보다 두 배나 뛰어납니다. 지침 측면에서 MONAKA에는 벡터가 장착되어 있습니다.
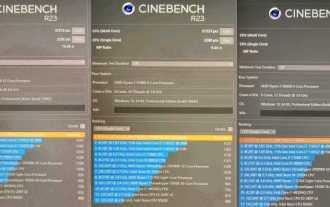
 AMD Ryzen 9 9950X는 6.6GHz로 오버클럭되었으며 CineBench R23은 최대 55296점을 획득했습니다.
Jul 17, 2024 pm 09:49 PM
AMD Ryzen 9 9950X는 6.6GHz로 오버클럭되었으며 CineBench R23은 최대 55296점을 획득했습니다.
Jul 17, 2024 pm 09:49 PM
7월 16일 이 웹사이트의 소식에 따르면 AMDXOC 팀은 Zen5 Technology Day에서 초대된 미디어와 게스트에게 오버클럭된 Ryzen 99950X 프로세서를 시연했으며 이 프로세서는 액체 질소(LN2)를 사용하여 오버클럭되었으며 CineBenchR23에서 5.5점 이상을 기록했습니다. , 전력 소비는 552W만큼 높습니다. XOC 팀이 사용하는 오버클러킹 플랫폼은 ASUS X670EROG CorsshairGene 마더보드입니다. 이 마더보드는 오버클러킹 플레이어를 위해 특별히 설계되었으며 2개의 DDR5DIMM이 장착된 마더보드입니다. 액체질소를 사용한 후 라이젠 99950X 프로세서의 작동온도는 영하 90도까지 떨어졌고, 소비전력은 552W, CPU는 6.4GHz로 오버클럭됐고, CineBenchR23 점수는 55296을 넘었다.
 멀티 코어 100,000개 초과, AMD EPYC 9755 프로세서 CPU-Z 실행 점수 노출: EPYC 9654보다 14% 빠름
Jul 25, 2024 am 10:46 AM
멀티 코어 100,000개 초과, AMD EPYC 9755 프로세서 CPU-Z 실행 점수 노출: EPYC 9654보다 14% 빠름
Jul 25, 2024 am 10:46 AM
7월 25일 이 사이트의 소식에 따르면, 출처 HXL(@9550pro)은 어제(7월 24일) 트윗을 통해 CPU-Z 벤치마크 테스트에서 우수한 결과를 얻은 Zen5 기반 AMDEPYC9755 "Turin" CPU에 대한 정보를 공유했습니다. . AMDEPYC9755 "Turin" CPU 정보 EPYC9755는 AMD의 5세대 EPYC 제품군 제품으로 Zen5 아키텍처에 128개의 코어와 256개의 스레드를 갖추고 있습니다. EPYC9755 프로세서의 기본 클록 주파수는 2.70GHz이고 가속 클록 주파수는 4.10GHz에 도달할 수 있습니다. 이전 세대에 비해 코어/스레드 수가 33% 증가했으며 클록 주파수는 11% 증가했습니다. EPYC9755
 AMD는 수백만 개의 Ryzen 및 EPYC 프로세서에 영향을 미치는 심각도가 높은 'Sinkclose' 취약점을 발표했습니다.
Aug 10, 2024 pm 10:31 PM
AMD는 수백만 개의 Ryzen 및 EPYC 프로세서에 영향을 미치는 심각도가 높은 'Sinkclose' 취약점을 발표했습니다.
Aug 10, 2024 pm 10:31 PM
8월 10일 이 사이트의 뉴스에 따르면 AMD는 일부 EPYC 및 Ryzen 프로세서에 전 세계 수백만 명의 AMD 사용자가 관련될 수 있는 코드 "CVE-2023-31315"가 포함된 "Sinkclose"라는 새로운 취약점이 있음을 공식 확인했습니다. 그렇다면 싱크클로즈란 무엇일까요? WIRED의 보고서에 따르면 이 취약점으로 인해 침입자는 "시스템 관리 모드(SMM)"에서 악성 코드를 실행할 수 있습니다. 침입자는 부트킷이라는 일종의 악성코드를 이용해 상대방의 시스템을 제어할 수 있으며, 이 악성코드는 안티바이러스 소프트웨어로 탐지할 수 없는 것으로 알려졌다. 이 사이트의 참고 사항: 시스템 관리 모드(SMM)는 고급 전원 관리 및 운영 체제 독립적 기능을 달성하도록 설계된 특수 CPU 작업 모드입니다.
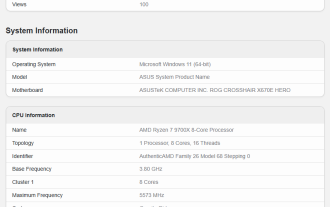 AMD Ryzen 7 9700X 프로세서가 Geekbench에 등장: 단일 코어 실행 점수가 R7 7700X보다 14% 더 높습니다.
Jul 12, 2024 pm 01:59 PM
AMD Ryzen 7 9700X 프로세서가 Geekbench에 등장: 단일 코어 실행 점수가 R7 7700X보다 14% 더 높습니다.
Jul 12, 2024 pm 01:59 PM
7월 9일 이 웹사이트의 소식에 따르면 AMD Ryzen 79700X 프로세서를 탑재한 ASUS 테스트 머신이 Geekbench 데이터베이스에 등장했으며 ROG CROSSHAIRX670EHERO 마더보드와 32GBDDR56000 메모리를 탑재했습니다. AMD Ryzen 79700X는 8코어 16스레드, 3.8GHz 기본 주파수, 5.5GHz 가속 주파수, 40MB 캐시(이 사이트 참고: 32MBL3+8MBL2) 및 65W TDP 설계를 갖추고 있지만 AMD가 TDP를 120W로 늘렸다는 소식도 있습니다. . 그림에서 볼 수 있듯이 테스트 플랫폼은 Geekbench6.3.0에서 싱글 및 멀티 코어 점수 3312점, 16431점을 실행했는데, 이는 R77700보다 뛰어납니다.
 Kirin 8000 프로세서는 Snapdragon 시리즈와 경쟁합니다. 누가 왕이 될 수 있습니까?
Mar 25, 2024 am 09:03 AM
Kirin 8000 프로세서는 Snapdragon 시리즈와 경쟁합니다. 누가 왕이 될 수 있습니까?
Mar 25, 2024 am 09:03 AM
모바일 인터넷 시대를 맞아 스마트폰은 국민의 일상생활에서 없어서는 안 될 존재가 되었습니다. 스마트폰의 성능은 사용자 경험의 질을 직접적으로 결정하는 경우가 많습니다. 스마트폰의 '두뇌'인 프로세서의 성능은 특히 중요합니다. 시장에서 Qualcomm Snapdragon 시리즈는 항상 강력한 성능, 안정성 및 신뢰성을 대표해 왔으며 최근 Huawei는 뛰어난 성능을 갖춘 것으로 알려진 자체 Kirin 8000 프로세서도 출시했습니다. 일반 사용자들에게는 강력한 성능의 휴대폰을 어떻게 선택하느냐가 중요한 이슈가 되었다. 오늘 우리는
