

hive分区(partition)简介

网上有篇关于hive的partition的使用讲解的比较好,转载了: 一、背景 1、在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。 2、分区表指的是在创建表时指定
网上有篇关于hive的partition的使用讲解的比较好,转载了:
一、背景
1、在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。
2、分区表指的是在创建表时指定的partition的分区空间。
3、如果需要创建有分区的表,需要在create表的时候调用可选参数partitioned by,详见表创建的语法结构。
二、技术细节
1、一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
2、表和列名不区分大小写。
3、分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
4、建表的语法(建分区可参见PARTITIONED BY参数):
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]
5、分区建表分为2种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现多文件夹嵌套模式。
a、单分区建表语句:create table day_table (id int, content string) partitioned by (dt string);单分区表,按天分区,在表结构中存在id,content,dt三列。
b、双分区建表语句:create table day_hour_table (id int, content string) partitioned by (dt string, hour string);双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。
表文件夹目录示意图(多分区表):
6、添加分区表语法(表已创建,在此基础上添加分区):
ALTER TABLE table_name ADD partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ] ... partition_spec: : PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
用户可以用 ALTER TABLE ADD PARTITION 来向一个表中增加分区。当分区名是字符串时加引号。例:
ALTER TABLE day_table ADD PARTITION (dt='2008-08-08', hour='08') location '/path/pv1.txt' PARTITION (dt='2008-08-08', hour='09') location '/path/pv2.txt';
7、删除分区语法:
ALTER TABLE table_name DROP partition_spec, partition_spec,...
用户可以用 ALTER TABLE DROP PARTITION 来删除分区。分区的元数据和数据将被一并删除。例:
ALTER TABLE day_hour_table DROP PARTITION (dt='2008-08-08', hour='09');
8、数据加载进分区表中语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
例:
LOAD DATA INPATH '/user/pv.txt' INTO TABLE day_hour_table PARTITION(dt='2008-08- 08', hour='08'); LOAD DATA local INPATH '/user/hua/*' INTO TABLE day_hour partition(dt='2010-07- 07');
当数据被加载至表中时,不会对数据进行任何转换。Load操作只是将数据复制至Hive表对应的位置。数据加载时在表下自动创建一个目录,文件存放在该分区下。
9、基于分区的查询的语句:
SELECT day_table.* FROM day_table WHERE day_table.dt>= '2008-08-08';
10、查看分区语句:
hive> show partitions day_hour_table; OK dt=2008-08-08/hour=08 dt=2008-08-08/hour=09 dt=2008-08-09/hour=09
三、总结
1、在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在最字集的目录中。
2、总的说来partition就是辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
——————————————————————————————————————
hive中关于partition的操作:
hive> create table mp (a string) partitioned by (b string, c string);
OK
Time taken: 0.044 seconds
hive> alter table mp add partition (b='1', c='1');
OK
Time taken: 0.079 seconds
hive> alter table mp add partition (b='1', c='2');
OK
Time taken: 0.052 seconds
hive> alter table mp add partition (b='2', c='2');
OK
Time taken: 0.056 seconds
hive> show partitions mp ;
OK
b=1/c=1
b=1/c=2
b=2/c=2
Time taken: 0.046 seconds
hive> explain extended alter table mp drop partition (b='1');
OK
ABSTRACT SYNTAX TREE:
(TOK_ALTERTABLE_DROPPARTS mp (TOK_PARTSPEC (TOK_PARTVAL b '1')))
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Drop Table Operator:
Drop Table
table: mp
Time taken: 0.048 seconds
hive> alter table mp drop partition (b='1');
FAILED: Error in metadata: table is partitioned but partition spec is not specified or tab: {b=1}
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask
hive> show partitions mp ;
OK
b=1/c=1
b=1/c=2
b=2/c=2
Time taken: 0.044 seconds
hive> alter table mp add partition ( b='1', c = '3') partition ( b='1' , c='4');
OK
Time taken: 0.168 seconds
hive> show partitions mp ;
OK
b=1/c=1
b=1/c=2
b=1/c=3
b=1/c=4
b=2/c=2
b=2/c=3
Time taken: 0.066 seconds
hive>insert overwrite table mp partition (b='1', c='1') select cnt from tmp_et3 ;
hive>alter table mp add columns (newcol string);
location指定目录结构
hive> alter table alter2 add partition (insertdate='2008-01-01') location '2008/01/01';
hive> alter table alter2 add partition (insertdate='2008-01-02') location '2008/01/02';

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!
인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7802
7802
 15
1645
14
1402
52
1300
25
1236
29
15
1645
14
1402
52
1300
25
1236
29

![[Linux 시스템] fdisk 관련 파티션 명령.](https://img.php.cn/upload/article/000/887/227/170833682614236.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) [Linux 시스템] fdisk 관련 파티션 명령.
Feb 19, 2024 pm 06:00 PM
[Linux 시스템] fdisk 관련 파티션 명령.
Feb 19, 2024 pm 06:00 PM
fdisk는 디스크 파티션을 생성, 관리 및 수정하는 데 일반적으로 사용되는 Linux 명령줄 도구입니다. 다음은 일반적으로 사용되는 fdisk 명령입니다. 디스크 파티션 정보 표시: fdisk-l 이 명령은 시스템에 있는 모든 디스크의 파티션 정보를 표시합니다. 작동하려는 디스크를 선택하십시오: fdisk/dev/sdX /dev/sdX를 작동하려는 실제 디스크 장치 이름(예: /dev/sda)으로 바꾸십시오. 새 파티션 만들기:n 새 파티션을 만드는 방법을 안내합니다. 프롬프트에 따라 파티션 유형, 시작 섹터, 크기 및 기타 정보를 입력하십시오. 파티션 삭제:d 삭제하려는 파티션을 선택하도록 안내합니다. 프롬프트에 따라 삭제할 파티션 번호를 선택하십시오. 파티션 유형 수정: 유형을 수정하려는 파티션을 선택하도록 안내합니다. 언급에 따르면
 win10 설치 후 파티션이 안되는 문제 해결 방법
Jan 02, 2024 am 09:17 AM
win10 설치 후 파티션이 안되는 문제 해결 방법
Jan 02, 2024 am 09:17 AM
win10 운영 체제를 다시 설치했을 때 디스크 파티셔닝 단계에서 시스템에서 새 파티션을 생성할 수 없으며 기존 파티션을 찾을 수 없다는 메시지를 표시하는 것을 발견했습니다. 이런 경우에는 하드디스크 전체를 다시 포맷하고 시스템을 파티션에 다시 설치하거나, 소프트웨어 등을 통해 시스템을 다시 설치해 보시는 것도 좋을 것 같습니다. 특정 콘텐츠에 대해 편집자가 어떻게 작업했는지 살펴보겠습니다~ 도움이 되었으면 좋겠습니다. win10을 설치한 후 새 파티션을 만들 수 없는 경우 방법 1: 전체 하드 디스크를 포맷하고 다시 파티션을 나누거나 USB 플래시 드라이브를 여러 번 연결 및 분리한 후 새로 고쳐 보십시오. , 파티션 나누기 단계에서는 하드 디스크의 모든 데이터를 삭제합니다. 파티션이 삭제되었습니다. 전체 하드 드라이브를 다시 포맷한 후 다시 파티션을 나눈 후 정상적으로 설치하세요. 방법 2: P
 Python ORM 성능 벤치마크: 다양한 ORM 프레임워크 비교
Mar 18, 2024 am 09:10 AM
Python ORM 성능 벤치마크: 다양한 ORM 프레임워크 비교
Mar 18, 2024 am 09:10 AM
ORM(객체 관계형 매핑) 프레임워크는 Python 개발에서 중요한 역할을 하며, 객체와 관계형 데이터베이스 사이에 브리지를 구축하여 데이터 액세스 및 관리를 단순화합니다. 다양한 ORM 프레임워크의 성능을 평가하기 위해 이 기사에서는 다음과 같은 널리 사용되는 프레임워크를 벤치마킹합니다. sqlAlchemyPeeweeDjangoORMPonyORMTortoiseORM 테스트 방법 벤치마크에서는 100만 개의 레코드가 포함된 SQLite 데이터베이스를 사용합니다. 테스트는 데이터베이스에서 다음 작업을 수행했습니다. 삽입: 테이블에 10,000개의 새 레코드를 삽입합니다. 읽기: 테이블의 모든 레코드를 읽습니다. 업데이트: 테이블의 모든 레코드에 대해 단일 필드를 업데이트합니다. 삭제: 테이블의 모든 레코드를 삭제합니다. 각 작업
 Linux Opt 파티션 설정 방법에 대한 자세한 설명
Mar 20, 2024 am 11:30 AM
Linux Opt 파티션 설정 방법에 대한 자세한 설명
Mar 20, 2024 am 11:30 AM
Linux Opt 파티션 및 코드 예제를 설정하는 방법 Linux 시스템에서 Opt 파티션은 일반적으로 선택적 소프트웨어 패키지 및 응용 프로그램 데이터를 저장하는 데 사용됩니다. Opt 파티션을 올바르게 설정하면 시스템 리소스를 효과적으로 관리하고 디스크 공간 부족과 같은 문제를 피할 수 있습니다. 이 기사에서는 LinuxOpt 파티션을 설정하는 방법을 자세히 설명하고 특정 코드 예제를 제공합니다. 1. 파티션 공간 크기 결정 먼저 Opt 파티션에 필요한 공간 크기를 결정해야 합니다. 일반적으로 Opt 파티션의 크기를 전체 시스템 공간의 5%-1로 설정하는 것이 좋습니다.
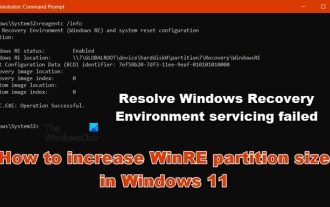 Windows 11에서 WinRE 파티션 크기를 늘리는 방법
Feb 19, 2024 pm 06:06 PM
Windows 11에서 WinRE 파티션 크기를 늘리는 방법
Feb 19, 2024 pm 06:06 PM
이 기사에서는 Windows 11/10에서 WinRE 파티션 크기를 변경하거나 늘리는 방법을 보여줍니다. Microsoft는 이제 Windows 11 버전 22H2부터 월별 누적 업데이트와 함께 Windows 복구 환경(WinRE)을 업데이트할 예정입니다. 그러나 모든 컴퓨터에 새 업데이트를 수용할 만큼 큰 복구 파티션이 있는 것은 아니며 이로 인해 오류 메시지가 나타날 수 있습니다. Windows 복구 환경 서비스가 실패했습니다. Windows 11에서 WinRE 파티션 크기를 늘리는 방법 컴퓨터에서 WinRE 파티션 크기를 수동으로 늘리려면 아래에 설명된 단계를 따르세요. WinRE 확인 및 비활성화 OS 파티션 축소 새 복구 파티션 생성 파티션 확인 및 WinRE 활성화
 Deepin Linux 하드 디스크 파티셔닝 및 설치 튜토리얼: 효율적인 시스템 배포를 위한 단계별
Feb 10, 2024 pm 07:06 PM
Deepin Linux 하드 디스크 파티셔닝 및 설치 튜토리얼: 효율적인 시스템 배포를 위한 단계별
Feb 10, 2024 pm 07:06 PM
Deepin Linux를 설치하기 전에 하드 디스크를 분할해야 합니다. 하드 디스크 분할은 물리적 하드 디스크를 여러 논리적 영역으로 나누는 프로세스입니다. 올바른 분할 방법은 성능과 성능을 향상시킬 수 있습니다. 안정성이 있으므로 이 단계는 매우 중요합니다. 이 문서에서는 자세하고 심층적인 Linux 하드 디스크 파티셔닝 및 설치 튜토리얼을 제공합니다. 준비 1. 파티션을 나누면 하드 드라이브의 모든 데이터가 지워지므로 중요한 데이터를 백업했는지 확인하십시오. 2. USB 플래시 드라이브, CD 등 Deepin Linux 설치 미디어를 준비합니다. 하드 디스크 파티션 1. BIOS 설정으로 부팅하고 부팅 미디어를 기본 부팅 장치로 설정합니다. 2. 컴퓨터를 다시 시작하고 부팅 미디어에서 부팅하여 시스템 설치 인터페이스로 들어갑니다. 3.선택
 빅데이터 프로젝트에 Python ORM 적용
Mar 18, 2024 am 09:19 AM
빅데이터 프로젝트에 Python ORM 적용
Mar 18, 2024 am 09:19 AM
ORM(객체 관계형 매핑)은 개발자가 SQL 쿼리를 직접 작성하지 않고도 객체 프로그래밍 언어를 사용하여 데이터베이스를 조작할 수 있도록 하는 프로그래밍 기술입니다. Python의 ORM 도구(예: SQLAlchemy, Peewee 및 DjangoORM)는 빅 데이터 프로젝트의 데이터베이스 상호 작용을 단순화합니다. 장점 코드 단순성: ORM을 사용하면 긴 SQL 쿼리를 작성할 필요가 없으므로 코드 단순성과 가독성이 향상됩니다. 데이터 추상화: ORM은 데이터베이스 구현 세부 사항에서 애플리케이션 코드를 분리하여 유연성을 향상시키는 추상화 계층을 제공합니다. 성능 최적화: ORM은 캐싱 및 일괄 작업을 사용하여 데이터베이스 쿼리를 최적화함으로써 성능을 향상시키는 경우가 많습니다. 이식성: ORM을 통해 개발자는 다음을 수행할 수 있습니다.
 Win11에서 하드 디스크를 분할하는 방법은 무엇입니까? win11 디스크에서 하드 디스크를 파티션하는 방법에 대한 튜토리얼
Feb 19, 2024 pm 06:01 PM
Win11에서 하드 디스크를 분할하는 방법은 무엇입니까? win11 디스크에서 하드 디스크를 파티션하는 방법에 대한 튜토리얼
Feb 19, 2024 pm 06:01 PM
많은 사용자가 시스템의 기본 파티션 공간이 너무 작다고 생각하는데, Win11에서 하드 디스크를 파티션하는 방법은 무엇입니까? 사용자는 이 컴퓨터 아래의 관리를 직접 클릭한 다음 디스크 관리를 클릭하여 작업 설정을 수행할 수 있습니다. 이 사이트에서는 Win11에서 하드 드라이브를 분할하는 방법에 대한 자세한 튜토리얼을 사용자에게 제공합니다. win11에서 하드 디스크를 분할하는 방법에 대한 튜토리얼 1. 먼저 이 컴퓨터를 마우스 오른쪽 버튼으로 클릭하고 컴퓨터 관리를 엽니다. 3. 그런 다음 오른쪽의 디스크 상태를 확인하여 사용 가능한 공간이 있는지 확인합니다. (여유 공간이 있는 경우 6단계로 건너뜁니다.) 5. 그런 다음 확보해야 할 공간을 선택하고 압축을 클릭합니다. 7. 원하는 단순 볼륨 크기를 입력하고 다음을 클릭합니다. 9. 마지막으로 마침을 클릭하여 새 파티션을 만듭니다.
