

TI TPA2016D2 D类音频放大方案

欢迎进入IT技术社区论坛,与200万技术人员互动交流 >>进入 TI 公司的TPA2016D2 是立体声无滤波器的D类音频功率放大器,带有音量控制,动态范围压缩(DRC)和自动增益控制(AGC),5V工作时每路能向8欧姆负载1.7W的功率.器件具有独立的软件关断特性,并提供热保护和短
欢迎进入IT技术社区论坛,与200万技术人员互动交流 >>进入
TI 公司的TPA2016D2 是立体声无滤波器的D类音频功率放大器,带有音量控制,动态范围压缩(DRC)和自动增益控制(AGC),5V工作时每路能向8欧姆负载1.7W的功率.器件具有独立的软件关断特性,并提供热保护和短路保护,广泛应用在无线手机和PDA,手提导航设备,手提DVD播放器,笔记本电脑,收音机,游戏机以及智力玩具等.本文介绍了TPA2016D2的主要特性,功能方框图和应用电路以及TPA2016D2EVM评估板电路图和所用元件列表.The TPA2016D2 is a stereo, filter-free Class-D audio power amplifier with volume control, dynamic range compression (DRC) and automatic gain control (AGC). It is available in a 2.2 mm x 2.2 mm WCSP package.
The DRC/AGC function in the TPA2016D2 is programmable via a digital I2C interface. The DRC/AGC function can be configured to automatically prevent distortion of the audio signal and enhance quiet passages that are normally not heard. The DRC/AGC can also be configured to protect the speaker from damage at high power levels and compress the dynamic range of music to fit within the dynamic range of the speaker. The gain can be selected from -28 dB to +30 dB in 1-dB steps. The TPA2016D2 is capable of driving 1.7 W/Ch at 5 V or 750 mW/Ch at 3.6 V into 8 Ω load. The device features independent software shutdown controls for each channel and also provides thermal and short circuit protection.

图1. TPA2016D2外形图
TPA2016D2 主要特性:
Filter-Free Class-D Architecture
1.7 W/Ch Into 8 Ω at 5 V (10% THD+N)
750 mW/Ch Into 8 Ω at 3.6 V (10% THD+N)
Power Supply Range: 2.5 V to 5.5 V
Flexible Operation With/Without I2C
Programmable DRC/AGC Parameters
Digital I2C Volume Control
Selectable Gain from -28 dB to 30 dB in 1-dB Steps (when compression is used)
Selectable Attack, Release and Hold Times
4 Selectable Compression Ratios
Low Supply Current: 3.5 mA
Low Shutdown Current: 0.2 µA
High PSRR: 80 dB
Fast Start-up Time: 5 ms
AGC Enable/Disable Function
Limiter Enable/Disable Function
Short-Circuit and Thermal Protection
Space-Saving Package 2,2 mm × 2,2 mm Nano-Free WCSP (YZH)
应用范围:
Wireless or Cellular Handsets and PDAs
Portable Navigation Devices
Portable DVD Player
Notebook PCs
Portable Radio
Portable Games
Educational Toys
USB Speakers

图2. TPA2016D2功能方框图
图3. TPA2016D2简化应用电路
The TPA2016D2 evaluation module (EVM) is a complete, stand-alone audio board. It contains the TPA2016D2 WCSP (YZH) Class-D audio power amplifier.

图4. TPA2016D2EVM
[1] [2]


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7338
7338
 9
1627
14
1352
46
1265
25
1210
29
9
1627
14
1352
46
1265
25
1210
29

 자율주행과 궤도예측에 관한 글은 이 글이면 충분합니다!
Feb 28, 2024 pm 07:20 PM
자율주행과 궤도예측에 관한 글은 이 글이면 충분합니다!
Feb 28, 2024 pm 07:20 PM
자율주행 궤적 예측은 차량의 주행 과정에서 발생하는 다양한 데이터를 분석하여 차량의 향후 주행 궤적을 예측하는 것을 의미합니다. 자율주행의 핵심 모듈인 궤도 예측의 품질은 후속 계획 제어에 매우 중요합니다. 궤적 예측 작업은 풍부한 기술 스택을 보유하고 있으며 자율 주행 동적/정적 인식, 고정밀 지도, 차선, 신경망 아키텍처(CNN&GNN&Transformer) 기술 등에 대한 익숙함이 필요합니다. 시작하기가 매우 어렵습니다! 많은 팬들은 가능한 한 빨리 궤도 예측을 시작하여 함정을 피하기를 희망합니다. 오늘은 궤도 예측을 위한 몇 가지 일반적인 문제와 입문 학습 방법을 살펴보겠습니다. 관련 지식 입문 1. 미리보기 논문이 순서대로 되어 있나요? A: 먼저 설문조사를 보세요, p
 Stable Diffusion 3 논문이 드디어 공개되고, 아키텍처의 세부 사항이 공개되어 Sora를 재현하는 데 도움이 될까요?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 논문이 드디어 공개되고, 아키텍처의 세부 사항이 공개되어 Sora를 재현하는 데 도움이 될까요?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3의 논문이 드디어 나왔습니다! 이 모델은 2주 전에 출시되었으며 Sora와 동일한 DiT(DiffusionTransformer) 아키텍처를 사용합니다. 출시되자마자 큰 화제를 불러일으켰습니다. 이전 버전과 비교하여 StableDiffusion3에서 생성된 이미지의 품질이 크게 향상되었습니다. 이제 다중 테마 프롬프트를 지원하고 텍스트 쓰기 효과도 향상되었으며 더 이상 잘못된 문자가 표시되지 않습니다. StabilityAI는 StableDiffusion3이 800M에서 8B 범위의 매개변수 크기를 가진 일련의 모델임을 지적했습니다. 이 매개변수 범위는 모델이 많은 휴대용 장치에서 직접 실행될 수 있어 AI 사용이 크게 줄어든다는 것을 의미합니다.
 DualBEV: BEVFormer 및 BEVDet4D를 크게 능가하는 책을 펼치세요!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer 및 BEVDet4D를 크게 능가하는 책을 펼치세요!
Mar 21, 2024 pm 05:21 PM
본 논문에서는 자율 주행에서 다양한 시야각(예: 원근 및 조감도)에서 객체를 정확하게 감지하는 문제, 특히 원근(PV) 공간에서 조감(BEV) 공간으로 기능을 효과적으로 변환하는 방법을 탐구합니다. VT(Visual Transformation) 모듈을 통해 구현됩니다. 기존 방법은 크게 2D에서 3D로, 3D에서 2D로 변환하는 두 가지 전략으로 나뉩니다. 2D에서 3D로의 방법은 깊이 확률을 예측하여 조밀한 2D 특징을 개선하지만, 특히 먼 영역에서는 깊이 예측의 본질적인 불확실성으로 인해 부정확성이 발생할 수 있습니다. 3D에서 2D로의 방법은 일반적으로 3D 쿼리를 사용하여 2D 기능을 샘플링하고 Transformer를 통해 3D와 2D 기능 간의 대응에 대한 주의 가중치를 학습하므로 계산 및 배포 시간이 늘어납니다.
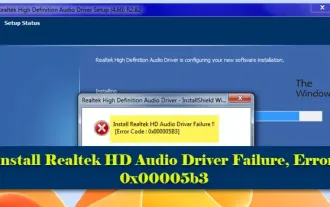 0x00005b3 오류로 인해 Realtek HD 오디오 드라이버 설치에 실패했습니다.
Feb 19, 2024 am 10:42 AM
0x00005b3 오류로 인해 Realtek HD 오디오 드라이버 설치에 실패했습니다.
Feb 19, 2024 am 10:42 AM
Windows 11/10 PC에서 RealtekHD 오디오 드라이버 오류 오류 코드 0x00005b3이 발생하는 경우 다음 단계를 참조하여 문제를 해결하세요. 문제 해결 및 오류 해결 과정을 안내해 드리겠습니다. 오류 코드 0x00005b3은 오디오 드라이버 설치 문제로 인해 발생할 수 있습니다. 현재 드라이버가 손상되었거나 부분적으로 제거되어 새 드라이버 설치에 영향을 줄 수 있습니다. 이 문제는 디스크 공간이 부족하거나 Windows 버전과 호환되지 않는 오디오 드라이버로 인해 발생할 수도 있습니다. RealtekHD 오디오 드라이버 설치에 실패했습니다! ! [오류 코드: 0x00005B3] Realtek 오디오 드라이버 설치 마법사에 문제가 있는 경우 계속해서 읽어보세요.
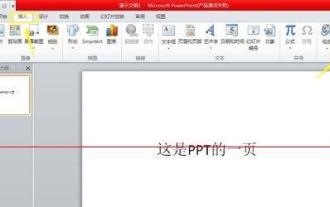 여러 오디오를 자동으로 재생하도록 PPT를 설정하는 방법
Mar 26, 2024 pm 06:21 PM
여러 오디오를 자동으로 재생하도록 PPT를 설정하는 방법
Mar 26, 2024 pm 06:21 PM
1. PPT를 열고 메뉴 바의 [삽입]을 클릭한 후, [오디오]를 클릭하세요. 2. 열리는 파일 선택 상자에서 삽입하려는 첫 번째 오디오 파일을 선택합니다. 3. 삽입이 성공하면 방금 삽입한 파일을 나타내는 스피커 아이콘이 PPT에 표시됩니다. PPT 심사 과정에서 파일을 재생하고 들을 수 있으며 볼륨을 조절하여 볼륨을 조절할 수 있습니다. 4. 동일한 방법으로 두 번째 오디오 파일을 삽입하면 PPT에 각각 두 개의 오디오 파일을 나타내는 두 개의 스피커 아이콘이 표시됩니다. 5. 첫 번째 오디오 파일 아이콘을 클릭하여 선택한 후 [재생] 메뉴를 클릭하세요. 6. 도구 모음의 시작에서 [슬라이드 전체 재생]을 선택하여 이 오디오가 사람의 개입 없이 모든 슬라이드에서 재생되도록 설정합니다. 7. 6단계의 단계를 따르세요.
 단순한 3D 가우스 그 이상입니다! 최첨단 3D 재구성 기술의 최신 개요
Jun 02, 2024 pm 06:57 PM
단순한 3D 가우스 그 이상입니다! 최첨단 3D 재구성 기술의 최신 개요
Jun 02, 2024 pm 06:57 PM
위에 작성됨 & 저자의 개인적인 이해는 이미지 기반 3D 재구성은 입력 이미지 세트에서 객체나 장면의 3D 모양을 추론하는 어려운 작업이라는 것입니다. 학습 기반 방법은 3차원 형상을 직접 추정할 수 있는 능력으로 주목을 받았습니다. 이 리뷰 논문은 새로운, 보이지 않는 뷰 생성을 포함한 최첨단 3D 재구성 기술에 중점을 두고 있습니다. 입력 유형, 모델 구조, 출력 표현 및 훈련 전략을 포함하여 가우스 스플래시 방법의 최근 개발에 대한 개요가 제공됩니다. 해결되지 않은 과제와 앞으로의 방향에 대해서도 논의한다. 해당 분야의 급속한 발전과 3D 재구성 방법을 향상할 수 있는 수많은 기회를 고려할 때 알고리즘을 철저히 조사하는 것이 중요해 보입니다. 따라서 이 연구는 가우스 산란의 최근 발전에 대한 포괄적인 개요를 제공합니다. (엄지손가락을 위로 스와이프하세요.
 검토! 심층 모델 융합(LLM/기본 모델/연합 학습/미세 조정 등)
Apr 18, 2024 pm 09:43 PM
검토! 심층 모델 융합(LLM/기본 모델/연합 학습/미세 조정 등)
Apr 18, 2024 pm 09:43 PM
9월 23일, 국립방위기술대학교, JD.com 및 베이징 공과대학이 "DeepModelFusion:ASurvey"라는 논문을 발표했습니다. 딥 모델 융합/병합은 여러 딥 러닝 모델의 매개변수나 예측을 단일 모델로 결합하는 새로운 기술입니다. 이는 더 나은 성능을 위해 개별 모델의 편향과 오류를 보상하기 위해 다양한 모델의 기능을 결합합니다. 대규모 딥 러닝 모델(예: LLM 및 기본 모델)에 대한 딥 모델 융합은 높은 계산 비용, 고차원 매개변수 공간, 서로 다른 이종 모델 간의 간섭 등을 포함한 몇 가지 문제에 직면합니다. 이 기사에서는 기존 심층 모델 융합 방법을 네 가지 범주로 나눕니다. (1) 더 나은 초기 모델 융합을 얻기 위해 손실 감소 경로를 통해 가중치 공간의 솔루션을 연결하는 "패턴 연결"
 혁신적인 GPT-4o: 인간-컴퓨터 상호 작용 경험 재편
Jun 07, 2024 pm 09:02 PM
혁신적인 GPT-4o: 인간-컴퓨터 상호 작용 경험 재편
Jun 07, 2024 pm 09:02 PM
OpenAI가 출시한 GPT-4o 모델은 특히 여러 입력 미디어(텍스트, 오디오, 이미지)를 처리하고 해당 출력을 생성하는 기능에서 의심할 여지 없이 큰 혁신입니다. 이 기능은 인간과 컴퓨터의 상호 작용을 더욱 자연스럽고 직관적으로 만들어 AI의 실용성과 유용성을 크게 향상시킵니다. GPT-4o의 주요 특징으로는 높은 확장성, 멀티미디어 입력 및 출력, 자연어 이해 기능의 추가 개선 등이 있습니다. 1. 교차 미디어 입력/출력: GPT-4o+는 텍스트, 오디오 및 이미지의 모든 조합을 입력으로 받아들이고 이러한 미디어에서 직접 출력을 생성할 수 있습니다. 이는 단일 입력 유형만 처리하는 기존 AI 모델의 한계를 깨뜨려 인간과 컴퓨터의 상호 작용을 더욱 유연하고 다양하게 만듭니다. 이 혁신은 스마트 어시스턴트를 강화하는 데 도움이 됩니다.
