

Ubuntu14.04安装Hadoop2.5.2(伪分布模式)

Hadoop也可以运行在一个伪分布模式,每个Hadoop守护进程运行在一个单独的Java程序的一个节点。 伪分布模式需要在单机模式基础上进行配置。 在/software/hadoop/etc/hadoop/ 目录下 core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml等文件。 下面
Hadoop也可以运行在一个伪分布模式,每个Hadoop守护进程运行在一个单独的Java程序的一个节点。
伪分布模式需要在单机模式基础上进行配置。
在/software/hadoop/etc/hadoop/ 目录下
core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml等文件。
下面对以上文件进行配置。
一、etc/hadoop/core-site.xml
包含了hadoop启动时的配置信息。
<code><span>configuration</span>>
<span>property</span>>
<span>name</span>>fs.defaultFS<span><span>name</span>></span>
<span>value</span>>hdfs://localhost:9000<span><span>value</span>></span>
<span><span>property</span>></span>
<span><span>configuration</span>></span></code>
二、etc/hadoop/hdfs-site.xml
用来配置集群中每台主机都可用,指定主机上作为namenode和datanode的目录。
<code><span>configuration</span>>
<span>property</span>>
<span>name</span>>dfs.replication<span><span>name</span>></span>
<span>value</span>>1<span><span>value</span>></span>
<span><span>property</span>></span>
<span><span>configuration</span>></span></code>
三、etc/hadoop/mapred-site.xml
默认情况下,/usr/local/hadoop/etc/hadoop/文件夹下有mapred.xml.template文件,我们要复制该文件,并命名为mapred.xml,该文件用于指定MapReduce使用的框架
<code><span>configuration</span>>
<span>property</span>>
<span>name</span>>mapreduce.framework.name<span><span>name</span>></span>
<span>value</span>>yarn<span><span>value</span>></span>
<span><span>property</span>></span>
<span><span>configuration</span>></span></code>
四、etc/hadoop/yarn-site.xml
包含了MapReduce启动时的配置信息。
<code><span>configuration</span>>
<span>property</span>>
<span>name</span>>yarn.nodemanager.aux-services<span><span>name</span>></span>
<span>value</span>>mapreduce_shuffle<span><span>value</span>></span>
<span><span>property</span>></span>
<span><span>configuration</span>></span></code>
五、格式化hdfs
<code> hdfs namenode -<span>format</span> </code>
只需要执行一次即可,如果在hadoop已经使用后再次执行,会清除掉hdfs上的所有数据。
六、启动Hadoop
经过上文所描述配置和操作后,下面就可以启动这个单节点的集群
执行启动命令:
<code> sbin/<span><span>start</span>-dfs.sh </span></code>
执行该命令时,如果有yes /no提示,输入yes,回车即可。
接下来,执行:
<code>sbin/<span><span>start</span>-yarn.sh </span></code>
执行完这两个命令后,Hadoop会启动并运行。
执行 jps命令,会看到Hadoop相关的进程。
浏览器打开 http://localhost:50070/,会看到hdfs管理页面。
浏览器打开 http://localhost:8088,会看到hadoop进程管理页面。
七、WordCount验证
dfs上创建input目录
<code>bin/hadoop fs <span>-mkdir</span> <span>-p</span> input</code>
把hadoop目录下的README.txt拷贝到dfs新建的input里
<code>hadoop fs -copyFromLocal README<span>.txt</span> input</code>
运行WordCount
<code>hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-<span>2.5</span><span>.2</span>-sources<span>.jar</span> org<span>.apache</span><span>.hadoop</span><span>.examples</span><span>.WordCount</span> input output</code>
执行过程:
运行完毕后,查看单词统计结果
<code>hadoop fs <span>-cat</span> output<span>/*</span></code>

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7667
7667
 15
1393
52
1205
24
91
11
73
19
15
1393
52
1205
24
91
11
73
19

 Win11 시스템에서 중국어 언어 팩을 설치할 수 없는 문제에 대한 해결 방법
Mar 09, 2024 am 09:48 AM
Win11 시스템에서 중국어 언어 팩을 설치할 수 없는 문제에 대한 해결 방법
Mar 09, 2024 am 09:48 AM
Win11 시스템에서 중국어 언어 팩을 설치할 수 없는 문제 해결 Windows 11 시스템이 출시되면서 많은 사용자들이 새로운 기능과 인터페이스를 경험하기 위해 운영 체제를 업그레이드하기 시작했습니다. 그러나 일부 사용자는 업그레이드 후 중국어 언어 팩을 설치할 수 없어 경험에 문제가 있다는 사실을 발견했습니다. 이 기사에서는 Win11 시스템이 중국어 언어 팩을 설치할 수 없는 이유에 대해 논의하고 사용자가 이 문제를 해결하는 데 도움이 되는 몇 가지 솔루션을 제공합니다. 원인 분석 먼저 Win11 시스템의 무능력을 분석해 보겠습니다.
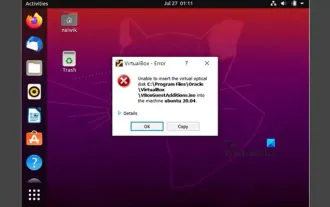 VirtualBox에 게스트 추가 기능을 설치할 수 없습니다
Mar 10, 2024 am 09:34 AM
VirtualBox에 게스트 추가 기능을 설치할 수 없습니다
Mar 10, 2024 am 09:34 AM
OracleVirtualBox의 가상 머신에 게스트 추가 기능을 설치하지 못할 수도 있습니다. Devices>InstallGuestAdditionsCDImage를 클릭하면 아래와 같이 오류가 발생합니다. VirtualBox - 오류: 가상 디스크를 삽입할 수 없습니다. C: 우분투 시스템에 FilesOracleVirtualBoxVBoxGuestAdditions.iso 프로그래밍 이 게시물에서는 어떤 일이 발생하는지 이해합니다. VirtualBox에 게스트 추가 기능을 설치할 수 없습니다. VirtualBox에 게스트 추가 기능을 설치할 수 없습니다. Virtua에 설치할 수 없는 경우
 Baidu Netdisk를 성공적으로 다운로드했지만 설치할 수 없는 경우 어떻게 해야 합니까?
Mar 13, 2024 pm 10:22 PM
Baidu Netdisk를 성공적으로 다운로드했지만 설치할 수 없는 경우 어떻게 해야 합니까?
Mar 13, 2024 pm 10:22 PM
바이두 넷디스크 설치 파일을 성공적으로 다운로드 받았으나 정상적으로 설치가 되지 않는 경우, 소프트웨어 파일의 무결성에 문제가 있거나, 잔여 파일 및 레지스트리 항목에 문제가 있을 수 있으므로, 본 사이트에서 사용자들이 주의깊게 확인해 보도록 하겠습니다. Baidu Netdisk가 성공적으로 다운로드되었으나 설치가 되지 않는 문제에 대한 분석입니다. 바이두 넷디스크 다운로드에 성공했지만 설치가 되지 않는 문제 분석 1. 설치 파일의 무결성 확인: 다운로드한 설치 파일이 완전하고 손상되지 않았는지 확인하세요. 다시 다운로드하거나 신뢰할 수 있는 다른 소스에서 설치 파일을 다운로드해 보세요. 2. 바이러스 백신 소프트웨어 및 방화벽 끄기: 일부 바이러스 백신 소프트웨어 또는 방화벽 프로그램은 설치 프로그램이 제대로 실행되지 않도록 할 수 있습니다. 바이러스 백신 소프트웨어와 방화벽을 비활성화하거나 종료한 후 설치를 다시 실행해 보세요.
 Linux에 Android 앱을 설치하는 방법은 무엇입니까?
Mar 19, 2024 am 11:15 AM
Linux에 Android 앱을 설치하는 방법은 무엇입니까?
Mar 19, 2024 am 11:15 AM
Linux에 Android 애플리케이션을 설치하는 것은 항상 많은 사용자의 관심사였습니다. 특히 Android 애플리케이션을 사용하려는 Linux 사용자의 경우 Linux 시스템에 Android 애플리케이션을 설치하는 방법을 익히는 것이 매우 중요합니다. Linux에서 직접 Android 애플리케이션을 실행하는 것은 Android 플랫폼에서만큼 간단하지는 않지만 에뮬레이터나 타사 도구를 사용하면 여전히 Linux에서 Android 애플리케이션을 즐겁게 즐길 수 있습니다. 다음은 Linux 시스템에 Android 애플리케이션을 설치하는 방법을 소개합니다.
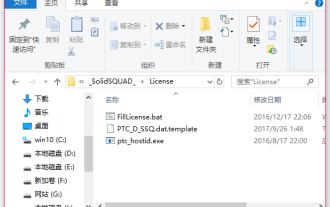 creo-creo 설치 튜토리얼 설치 방법
Mar 04, 2024 pm 10:30 PM
creo-creo 설치 튜토리얼 설치 방법
Mar 04, 2024 pm 10:30 PM
많은 초보 친구들은 아직 creo 설치 방법을 모르므로 아래 편집기에서 creo 설치에 대한 관련 튜토리얼을 가져오면 도움이 될 것입니다. 1. 다운로드한 설치 패키지를 열고 아래 그림과 같이 License 폴더를 찾습니다. 2. 그런 다음 아래 그림과 같이 C 드라이브의 디렉터리에 복사합니다. 3. 두 번 클릭하여 입력하고 라이센스가 있는지 확인합니다. 아래 그림과 같이 라이센스 파일이 있습니다. 그림과 같습니다. 4. 그런 다음 아래 그림과 같이 이 파일에 라이센스 파일을 복사합니다. 5. C 드라이브의 PROGRAMFILES 파일에 새 PLC 폴더를 생성합니다. 6. 라이센스 파일도 복사합니다. 아래 그림과 같이 클릭합니다. 7. 메인 프로그램의 설치 파일을 더블클릭합니다. 설치하려면 새 소프트웨어를 설치하는 확인란을 선택하세요.
 Ubuntu 24.04에 Podman을 설치하는 방법
Mar 22, 2024 am 11:26 AM
Ubuntu 24.04에 Podman을 설치하는 방법
Mar 22, 2024 am 11:26 AM
Docker를 사용해 본 적이 있다면 데몬, 컨테이너 및 해당 기능을 이해해야 합니다. 데몬은 컨테이너가 시스템에서 이미 사용 중일 때 백그라운드에서 실행되는 서비스입니다. Podman은 Docker와 같은 데몬에 의존하지 않고 컨테이너를 관리하고 생성하기 위한 무료 관리 도구입니다. 따라서 장기적인 백엔드 서비스 없이도 컨테이너를 관리할 수 있는 장점이 있습니다. 또한 Podman을 사용하려면 루트 수준 권한이 필요하지 않습니다. 이 가이드에서는 Ubuntu24에 Podman을 설치하는 방법을 자세히 설명합니다. 시스템을 업데이트하려면 먼저 시스템을 업데이트하고 Ubuntu24의 터미널 셸을 열어야 합니다. 설치 및 업그레이드 프로세스 중에 명령줄을 사용해야 합니다. 간단한
 Ubuntu 24.04에서 Ubuntu Notes 앱을 설치하고 실행하는 방법
Mar 22, 2024 pm 04:40 PM
Ubuntu 24.04에서 Ubuntu Notes 앱을 설치하고 실행하는 방법
Mar 22, 2024 pm 04:40 PM
고등학교에서 공부하는 동안 일부 학생들은 매우 명확하고 정확한 필기를 하며, 같은 수업을 받는 다른 학생들보다 더 많은 필기를 합니다. 어떤 사람들에게는 노트 필기가 취미인 반면, 어떤 사람들에게는 중요한 것에 대한 작은 정보를 쉽게 잊어버릴 때 필수입니다. Microsoft의 NTFS 응용 프로그램은 정규 강의 외에 중요한 메모를 저장하려는 학생들에게 특히 유용합니다. 이 기사에서는 Ubuntu24에 Ubuntu 애플리케이션을 설치하는 방법을 설명합니다. Ubuntu 시스템 업데이트 Ubuntu 설치 프로그램을 설치하기 전에 Ubuntu24에서 새로 구성된 시스템이 업데이트되었는지 확인해야 합니다. 우분투 시스템에서 가장 유명한 "a"를 사용할 수 있습니다
 Win7 컴퓨터에 Go 언어를 설치하는 자세한 단계
Mar 27, 2024 pm 02:00 PM
Win7 컴퓨터에 Go 언어를 설치하는 자세한 단계
Mar 27, 2024 pm 02:00 PM
Win7 컴퓨터에 Go 언어를 설치하는 세부 단계 Go(Golang이라고도 함)는 Google에서 개발한 오픈 소스 프로그래밍 언어로, 간단하고 효율적이며 뛰어난 동시성 성능을 갖추고 있으며 클라우드 서비스, 네트워크 애플리케이션 및 개발에 적합합니다. 백엔드 시스템. Win7 컴퓨터에 Go 언어를 설치하면 언어를 빠르게 시작하고 Go 프로그램 작성을 시작할 수 있습니다. 다음은 Win7 컴퓨터에 Go 언어를 설치하는 단계를 자세히 소개하고 특정 코드 예제를 첨부합니다. 1단계: Go 언어 설치 패키지를 다운로드하고 Go 공식 웹사이트를 방문하세요.
