

简析三层架构

三层架构3-tier architecture 通过几个问题,来初步的学习一下三层架构。 1、什么是三层架构 2、应用场景为什么要用三层架构? 3、三层作用 4、各个层之间的关系 5、三层联系引用 6、各层是如何调用的 7、三层和二层的对比 这几个都是学习三层中最基本的问题
三层架构——3-tier architecture
通过几个问题,来初步的学习一下三层架构。1、什么是三层架构 2、应用场景——为什么要用三层架构? 3、三层作用 4、各个层之间的关系 5、三层联系——引用 6、各层是如何调用的 7、三层和二层的对比 这几个都是学习三层中最基本的问题,只有把这些问题搞清楚,才算是打开了三层的门。
1、什么是三层架构
在软件体系架构设计中,分层式结构是最常见,也是最重要的一种结构。三层从下至上分别为:数据访问层(DAL)、业务逻辑层(BLL)、表示层(UI)。

表现层(UI):展现给用户的界面,即用户在使用一个系统的时候他的所见所得。
业务逻辑层(BLL):对数据层的操作,对数据业务逻辑处理。
数据访问层(DAL):对数据库的操作,数据的增添、删除、修改、查找等。
2、应用场景——为什么要用三层架构?
为什么要用三层架构?
解耦!
不是所有的程序都需要使用三层架构,没必要把简单的问题复杂化。
先来说一下解耦,举例:修电脑
电脑硬盘坏了?我们要做的就是换掉电脑硬盘
内存条坏了?只要换内存条就好
这些部件出现问题,都不会影响别的部件的正常使用,这个就是让他们之间解耦。而和电脑不同的收音机,任何部件坏了,都会影响别的部件,这个体现的就是他们之间的耦合比较高。从这个例子里面就可以看出解耦的好处,在三层中就是用的解耦的思想。
3、三层作用
数据访问层:从数据源加载(Select),写入(Insert/Update),删除(Delete)数据。仅限于和数据源打交道,让程序简单明了。
显示层(UI):向用户展现特定业务数据,采集用户的输入信息和操作。
原则:用户至上,兼顾简洁。
业务逻辑层(BLL):从DAL中获取数据,以供UI显示用,从UI中获取用户指令和数据,执行业务逻辑、从UI中获取用户指令和数据,通过DAL写入数据源。
4、各个层之间的关系:
UI->BLL->UI:UI提供数据指令到业务逻辑,若自己可以搞定,则直接反馈到UI
UI->BLL->DAL->BLL->DAL:UI提供用户指令和数据,提出请求并搜集一定的数据BLL,BLL处理不了时,要访问数据源,则转给DAL

5、三层联系——引用
以登陆为例子,说明三层之间的引用关系:
实体层(entity):定义的用户名和密码。
U层:向对应的文本框中输入账号和密码
B层:判断U层输入的账号和密码是否存在。
D层:连接数据库的语句,查询数据库。
他们之间的联系是通过实体传递来进行的,。
DAL所在程序集不引用BLL和UI
BLL需要引用DAL
UI直接引用DAL,可能引用BLL
非常忌讳互相引用,为了避免这个问题所有出现了实体层(业务数据模型,里面的数据和数据库的有所差异)
应用原则:
DAL只提供基本的数据访问,不包含任何业务相关的逻辑处理。UI只负责显示和采集用户操作,不包含任何的业务相关的逻辑处理,BLL负责处理业务逻辑,通过获取UI传来的操作指令,决定执行业务逻辑,在需要访问数据源的时候直接交给DAL处理。处理完成后,返回必要数据给UI。
6、各层是如何调用的
表示层(UI)是用户需要的界面,用户有什么需求都是在这个上面进行的改动,一旦有改动,首先U层向B层发送用户请求的说明,到达B层,B层再将U层的用户请求发送到D层,D层接受到用户请求的指令后,对它进行处理,发送数据反馈到B层,B层再发给U层,将这一变化反应出来。
举例:
小菜和大鸟吃羊肉串的例子,小菜和大鸟就是用户,服务员为表示层(U层),烤肉师父为业务逻辑层(U层引用B层的方法或者参数),老板娘为数据访问层(D层),负责给烤肉师父从库房拿烤串。大鸟点了羊肉串5串(参数),服务员把羊肉串5串(参数传递)传递给烤肉师父(数据请求),烤肉师父再传递给老板娘(对参数进行处理),老板娘得到请求后,拿羊肉串给烤肉师父(数据反馈),烤肉师父将烤好的羊肉串给服务员(数据反馈),服务员再将5串羊肉串给大鸟(U层展现出来),他们之间通过调用来实现联系。
7、三层PK二层
二层架构:
业务逻辑简单,没有真正的数据存储层
三层架构:
抽象出业务逻辑层,当业务复杂到一定程度,当数据存储到相应的存储介质,数据存储脱离开业务逻辑,把业务逻辑脱离开UI单独存在,UI只需要呼叫业务访问层,就可以实现跟用户的交互。
三层的好处:
1、开发人员可以只关注整个结构中的其中某一层;
2、可以很容易的用新的实现来替换原有层次的实现;
3、可以降低层与层之间的依赖;
4、有利于标准化;
5、利于各层逻辑的复用。
6、结构更加的明确
7、在后期维护的时候,极大地降低了维护成本和维护时间。
这几点的中心思想就是“高内聚,低耦合”,类之间的耦合越弱,越有利于复用,一个处在弱耦合的类被修改,不会对有关系的类造成波及。
以上是对三层的简单认识,有的地方可能写的不对,欢迎指出!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7461
7461
 15
1376
52
77
11
44
19
17
17
15
1376
52
77
11
44
19
17
17

 딥러닝 아키텍처의 비교 분석
May 17, 2023 pm 04:34 PM
딥러닝 아키텍처의 비교 분석
May 17, 2023 pm 04:34 PM
딥러닝의 개념은 인공 신경망 연구에서 유래되었습니다. 여러 개의 은닉층을 포함하는 다층 퍼셉트론이 딥러닝 구조입니다. 딥 러닝은 하위 수준 기능을 결합하여 보다 추상적인 상위 수준 표현을 형성하여 데이터의 범주나 특성을 나타냅니다. 데이터의 분산된 특징 표현을 발견할 수 있습니다. 딥러닝은 머신러닝의 일종으로, 머신러닝은 인공지능을 달성하는 유일한 방법이다. 그렇다면 다양한 딥러닝 시스템 아키텍처의 차이점은 무엇입니까? 1. 완전 연결 네트워크(FCN) 완전 연결 네트워크(FCN)는 일련의 완전히 연결된 계층으로 구성되며, 각 계층의 모든 뉴런은 다른 계층의 모든 뉴런에 연결됩니다. 주요 장점은 "구조에 구애받지 않는다"는 것입니다. 즉, 입력에 대한 특별한 가정이 필요하지 않습니다. 비록 이러한 구조적 불가지론이 완전한
 이 '실수'는 실제로는 실수가 아닙니다. Transformer 아키텍처 다이어그램의 '잘못'이 무엇인지 이해하려면 4개의 고전 논문으로 시작하세요.
Jun 14, 2023 pm 01:43 PM
이 '실수'는 실제로는 실수가 아닙니다. Transformer 아키텍처 다이어그램의 '잘못'이 무엇인지 이해하려면 4개의 고전 논문으로 시작하세요.
Jun 14, 2023 pm 01:43 PM
얼마 전 Transformer 아키텍처 다이어그램과 Google Brain 팀의 논문 "AttentionIsAllYouNeed" 코드 간의 불일치를 지적하는 트윗이 많은 논의를 촉발했습니다. 어떤 사람들은 세바스찬의 발견이 의도하지 않은 실수였다고 생각하지만, 그 역시 놀라운 일이다. 결국 Transformer 논문의 인기를 고려하면 이러한 불일치는 수천 번 언급되어야 합니다. Sebastian Raschka는 네티즌 댓글에 대해 "가장 독창적인" 코드가 아키텍처 다이어그램과 실제로 일치하지만 2017년에 제출된 코드 버전은 수정되었지만 아키텍처 다이어그램은 동시에 업데이트되지 않았다고 말했습니다. 이는 '일관되지 않은' 논의의 근본 원인이기도 합니다.
 다중 경로, 다중 도메인, 모든 것을 포함합니다! Google AI, 다중 도메인 학습 일반 모델 MDL 출시
May 28, 2023 pm 02:12 PM
다중 경로, 다중 도메인, 모든 것을 포함합니다! Google AI, 다중 도메인 학습 일반 모델 MDL 출시
May 28, 2023 pm 02:12 PM
비전 작업(예: 이미지 분류)을 위한 딥 러닝 모델은 일반적으로 단일 시각적 영역(예: 자연 이미지 또는 컴퓨터 생성 이미지)의 데이터를 사용하여 엔드투엔드 학습됩니다. 일반적으로 여러 도메인에 대한 비전 작업을 완료하는 애플리케이션은 각 개별 도메인에 대해 여러 모델을 구축하고 이를 독립적으로 교육해야 합니다. 추론 중에는 각 모델이 특정 도메인 입력 데이터를 처리합니다. 서로 다른 분야를 지향하더라도 이러한 모델 간 초기 레이어의 일부 기능은 유사하므로 이러한 모델의 공동 학습이 더 효율적입니다. 이렇게 하면 대기 시간과 전력 소비가 줄어들고, 각 모델 매개변수를 저장하는 데 드는 메모리 비용이 줄어듭니다. 이러한 접근 방식을 다중 도메인 학습(MDL)이라고 합니다. 또한 MDL 모델은 단일 모델보다 성능이 뛰어날 수도 있습니다.
 Spring Data JPA의 아키텍처와 작동 원리는 무엇입니까?
Apr 17, 2024 pm 02:48 PM
Spring Data JPA의 아키텍처와 작동 원리는 무엇입니까?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA는 JPA 아키텍처를 기반으로 하며 매핑, ORM 및 트랜잭션 관리를 통해 데이터베이스와 상호 작용합니다. 해당 리포지토리는 CRUD 작업을 제공하고 파생 쿼리는 데이터베이스 액세스를 단순화합니다. 또한 지연 로딩을 사용하여 필요한 경우에만 데이터를 검색하므로 성능이 향상됩니다.
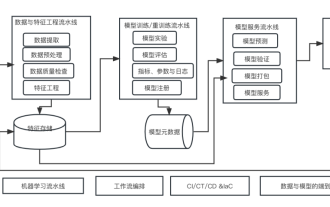 머신러닝 시스템 아키텍처의 10가지 요소
Apr 13, 2023 pm 11:37 PM
머신러닝 시스템 아키텍처의 10가지 요소
Apr 13, 2023 pm 11:37 PM
지금은 AI 역량 강화 시대이며, 머신러닝은 AI를 달성하기 위한 중요한 기술적 수단입니다. 그렇다면 보편적인 머신러닝 시스템 아키텍처가 존재하는 걸까요? 숙련된 프로그래머의 인지 범위 내에서는 특히 시스템 아키텍처의 경우 아무것도 아닙니다. 그러나 대부분의 기계 학습 기반 시스템이나 사용 사례에 적용할 수 있는 경우 확장 가능하고 안정적인 기계 학습 시스템 아키텍처를 구축하는 것이 가능합니다. 기계 학습 수명 주기 관점에서 볼 때 이 소위 범용 아키텍처는 기계 학습 모델 개발부터 교육 시스템 및 서비스 시스템을 프로덕션 환경에 배포하는 것까지 주요 기계 학습 단계를 다룹니다. 우리는 이러한 머신러닝 시스템 아키텍처를 10가지 요소의 차원에서 설명할 수 있습니다. 1.
 1.3ms는 1.3ms가 걸립니다! Tsinghua의 최신 오픈 소스 모바일 신경망 아키텍처 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms는 1.3ms가 걸립니다! Tsinghua의 최신 오픈 소스 모바일 신경망 아키텍처 RepViT
Mar 11, 2024 pm 12:07 PM
논문 주소: https://arxiv.org/abs/2307.09283 코드 주소: https://github.com/THU-MIG/RepViTRepViT는 모바일 ViT 아키텍처에서 잘 작동하며 상당한 이점을 보여줍니다. 다음으로, 본 연구의 기여를 살펴보겠습니다. 기사에서는 경량 ViT가 일반적으로 시각적 작업에서 경량 CNN보다 더 나은 성능을 발휘한다고 언급했는데, 그 이유는 주로 모델이 전역 표현을 학습할 수 있는 MSHA(Multi-Head Self-Attention 모듈) 때문입니다. 그러나 경량 ViT와 경량 CNN 간의 아키텍처 차이점은 완전히 연구되지 않았습니다. 본 연구에서 저자는 경량 ViT를 효과적인
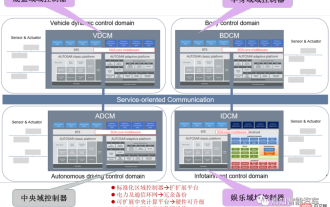 SOA의 소프트웨어 아키텍처 설계와 소프트웨어 및 하드웨어 분리 방법론
Apr 08, 2023 pm 11:21 PM
SOA의 소프트웨어 아키텍처 설계와 소프트웨어 및 하드웨어 분리 방법론
Apr 08, 2023 pm 11:21 PM
차세대 중앙 집중식 전자 및 전기 아키텍처를 위해 중앙+영역 중앙 컴퓨팅 장치 및 지역 컨트롤러 레이아웃의 사용은 다양한 OEM 또는 Tier1 플레이어에게 필수 옵션이 되었습니다. 중앙 컴퓨팅 장치의 아키텍처에는 세 가지가 있습니다. 방법: 분리 SOC, 하드웨어 격리, 소프트웨어 가상화. 중앙 집중식 중앙 컴퓨팅 장치는 자율 주행, 스마트 조종석 및 차량 제어의 세 가지 주요 영역의 핵심 비즈니스 기능을 통합합니다. 표준화된 지역 컨트롤러에는 전력 분배, 데이터 서비스 및 지역 게이트웨이라는 세 가지 주요 책임이 있습니다. 따라서 중앙 컴퓨팅 장치에는 처리량이 높은 이더넷 스위치가 통합됩니다. 전체 차량의 통합 정도가 점점 높아짐에 따라 점점 더 많은 ECU 기능이 지역 컨트롤러에 흡수될 것입니다. 그리고 플랫폼화
 golang 프레임워크 아키텍처의 학습 곡선은 얼마나 가파르나요?
Jun 05, 2024 pm 06:59 PM
golang 프레임워크 아키텍처의 학습 곡선은 얼마나 가파르나요?
Jun 05, 2024 pm 06:59 PM
Go 프레임워크 아키텍처의 학습 곡선은 Go 언어 및 백엔드 개발에 대한 친숙도와 선택한 프레임워크의 복잡성, 즉 Go 언어의 기본 사항에 대한 올바른 이해에 따라 달라집니다. 백엔드 개발 경험이 있으면 도움이 됩니다. 다양한 복잡성의 프레임워크는 다양한 학습 곡선으로 이어집니다.
