

Adding Filter in Hadoop Mapper Class

There is my solutions to tackle the disk spaces shortage problem I described in the previous post. The core principle of the solution is to reduce the number of output records at Mapper stage; the method I used is Filter , adding a filter,
There is my solutions to tackle the disk spaces shortage problem I described in the previous post. The core principle of the solution is to reduce the number of output records at Mapper stage; the method I used is Filter, adding a filter, which I will explain later, to decrease the output records of Mapper, which in turn significantly decrease the Mapper’s Spill records, and fundamentally decrease the disk space usages. After applying the filter, with 30,661 records. some 200MB data set as inputs, the total Spill Records is 25,471,725, and it only takes about 509MB disk spaces!
Followed Filter
And now I’m going to reveal what’s kinda Filter it looks like, and how did I accomplish that filter. The true face of the FILTER is called Followed Filter, it filters users from computing co-followed combinations if their followed number does not satisfy a certain number, called Followed Threshold.
Followed Filter is used to reduce the co-followed combinations at Mapper stage. Say we set the followed threshold to 100, meaning users who doesn’t own 100 fans(be followed by 100 other users) will be ignored during co-followed combinations computing stage(to get the actual number of the threshold we need analyze statistics of user’s followed number of our data set).
Reason
Choosing followed filter is reasonable because how many user follows is a metric of user’s popularity/famousness.
HOW
In order to accomplish it, we need:
First, counting user’s followed number among our data set, which needs a new MapReduce Job;
Second, choosing a followed threshold after analyze the statistics perspective of followed number data set got in first step;
Third, using DistrbutedCache of Hadoop to cache users who satisfy the filter to all Mappers;
Forth, adding followed filter to Mapper class, only users satisfy filter condition will be passed into co-followed combination computing phrase;
Fifth, adding co-followed filter/threshold in Reducer side if necessary.
Outcomes
Here is the Hadoop Job Summary, after applying the followed filter with followed threshold of 1000, that means only users who are followed by 1000 users will have the opportunity to co-followed combinations, compared with the Job Summary in my previous post, most all metrics have significant improvements:
| Counter | Map | Reduce | Total |
| Bytes Written | 0 | 1,798,185 | 1,798,185 |
| Bytes Read | 203,401,876 | 0 | 203,401,876 |
| FILE_BYTES_READ | 405,219,906 | 52,107,486 | 457,327,392 |
| HDFS_BYTES_READ | 203,402,751 | 0 | 203,402,751 |
| FILE_BYTES_WRITTEN | 457,707,759 | 52,161,704 | 509,869,463 |
| HDFS_BYTES_WRITTEN | 0 | 1,798,185 | 1,798,185 |
| Reduce input groups | 0 | 373,680 | 373,680 |
| Map output materialized bytes | 52,107,522 | 0 | 52,107,522 |
| Combine output records | 22,202,756 | 0 | 22,202,756 |
| Map input records | 30,661 | 0 | 30,661 |
| Reduce shuffle bytes | 0 | 52,107,522 | 52,107,522 |
| Physical memory (bytes) snapshot | 2,646,589,440 | 116,408,320 | 2,762,997,760 |
| Reduce output records | 0 | 373,680 | 373,680 |
| Spilled Records | 22,866,351 | 2,605,374 | 25,471,725 |
| Map output bytes | 2,115,139,050 | 0 | 2,115,139,050 |
| Total committed heap usage (bytes) | 2,813,853,696 | 84,738,048 | 2,898,591,744 |
| CPU time spent (ms) | 5,766,680 | 11,210 | 5,777,890 |
| Virtual memory (bytes) snapshot | 9,600,737,280 | 1,375,002,624 | 10,975,739,904 |
| SPLIT_RAW_BYTES | 875 | 0 | 875 |
| Map output records | 117,507,725 | 0 | 117,507,725 |
| Combine input records | 137,105,107 | 0 | 137,105,107 |
| Reduce input records | 0 | 2,605,374 | 2,605,374 |
P.S.
Frankly Speaking, chances are I am on the wrong way to Hadoop Programming, since I’m palying Pesudo Distribution Hadoop with my personal computer, which has 4 CUPs and 4G RAM, in real Hadoop Cluster disk spaces might never be a trouble, and all the tuning work I have done may turn into meaningless efforts. Before the Followed Filter, I also did some Hadoop tuning like customed Writable class, RawComparator, block size and io.sort.mb, etc.
---EOF---
原文地址:Adding Filter in Hadoop Mapper Class, 感谢原作者分享。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7926
7926
 15
1652
14
1411
52
1303
25
1250
29
15
1652
14
1411
52
1303
25
1250
29

 Java 오류: Hadoop 오류, 처리 및 방지 방법
Jun 24, 2023 pm 01:06 PM
Java 오류: Hadoop 오류, 처리 및 방지 방법
Jun 24, 2023 pm 01:06 PM
Java 오류: Hadoop 오류, 처리 및 방지 방법 Hadoop을 사용하여 빅 데이터를 처리할 때 작업 실행에 영향을 미치고 데이터 처리 실패를 유발할 수 있는 Java 예외 오류가 자주 발생합니다. 이 기사에서는 몇 가지 일반적인 Hadoop 오류를 소개하고 이를 처리하고 방지하는 방법을 제공합니다. Java.lang.OutOfMemoryErrorOutOfMemoryError는 Java 가상 머신의 메모리 부족으로 인해 발생하는 오류입니다. 하둡이 있을 때
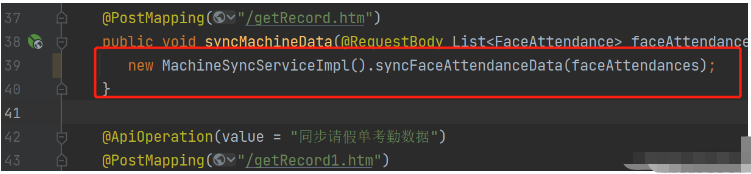 idea springBoot 프로젝트에 자동으로 주입되는 빈 매퍼 문제를 해결하는 방법
May 17, 2023 pm 06:49 PM
idea springBoot 프로젝트에 자동으로 주입되는 빈 매퍼 문제를 해결하는 방법
May 17, 2023 pm 06:49 PM
SpringBoot 프로젝트에서 MyBatis가 지속성 계층 프레임워크로 사용되는 경우 자동 주입을 사용할 때 매퍼가 널 포인터 예외를 보고하는 문제에 직면할 수 있습니다. 이는 SpringBoot가 자동 주입 중에 MyBatis의 Mapper 인터페이스를 올바르게 식별할 수 없고 몇 가지 추가 구성이 필요하기 때문입니다. 이 문제를 해결하는 방법에는 두 가지가 있습니다. 1. Mapper 인터페이스에 주석을 추가합니다. @Mapper 주석을 Mapper 인터페이스에 추가하여 이 인터페이스가 Mapper 인터페이스이고 프록시되어야 함을 SpringBoot에 알립니다. 예는 다음과 같습니다. @MapperpublicinterfaceUserMapper{//...}2
!['[Vue 경고]: 필터를 확인하지 못했습니다' 오류 해결 방법](https://img.php.cn/upload/article/000/887/227/169243040583797.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) '[Vue 경고]: 필터를 확인하지 못했습니다' 오류 해결 방법
Aug 19, 2023 pm 03:33 PM
'[Vue 경고]: 필터를 확인하지 못했습니다' 오류 해결 방법
Aug 19, 2023 pm 03:33 PM
"[Vuewarn]:Failedtoresolvefilter" 오류를 해결하는 방법 Vue를 사용하여 개발 프로세스를 진행하는 동안 "[Vuewarn]:Failedtoresolvefilter"라는 오류 메시지가 나타나는 경우가 있습니다. 이 오류 메시지는 일반적으로 템플릿에서 정의되지 않은 필터를 사용할 때 발생합니다. 이 문서에서는 이 오류를 해결하는 방법을 설명하고 해당 코드 예제를 제공합니다. 우리가 Vue에 있을 때
 빅 데이터 저장 및 쿼리를 위해 Beego에서 Hadoop 및 HBase 사용
Jun 22, 2023 am 10:21 AM
빅 데이터 저장 및 쿼리를 위해 Beego에서 Hadoop 및 HBase 사용
Jun 22, 2023 am 10:21 AM
빅데이터 시대가 도래하면서 데이터의 처리와 저장이 더욱 중요해지고 있으며, 대용량 데이터를 어떻게 효율적으로 관리하고 분석할 것인가가 기업의 과제가 되었습니다. Apache Foundation의 두 가지 프로젝트인 Hadoop과 HBase는 빅데이터 저장 및 분석을 위한 솔루션을 제공합니다. 이 기사에서는 빅데이터 저장 및 쿼리를 위해 Beego에서 Hadoop 및 HBase를 사용하는 방법을 소개합니다. 1. Hadoop 및 HBase 소개 Hadoop은 오픈 소스 분산 스토리지 및 컴퓨팅 시스템입니다.
 빅데이터 처리에 PHP와 Hadoop을 사용하는 방법
Jun 19, 2023 pm 02:24 PM
빅데이터 처리에 PHP와 Hadoop을 사용하는 방법
Jun 19, 2023 pm 02:24 PM
데이터의 양이 지속적으로 증가함에 따라 기존의 데이터 처리 방식으로는 더 이상 빅데이터 시대가 가져온 과제를 처리할 수 없습니다. 하둡(Hadoop)은 빅데이터 처리 시 단일 노드 서버로 인해 발생하는 성능 병목 현상을 분산 저장 및 대용량 데이터 처리를 통해 해결하는 오픈소스 분산 컴퓨팅 프레임워크이다. PHP는 웹 개발에 널리 사용되는 스크립팅 언어로 개발 속도가 빠르고 유지 관리가 쉽다는 장점이 있습니다. 이 글에서는 빅데이터 처리를 위해 PHP와 Hadoop을 사용하는 방법을 소개합니다. 하둡이란 무엇인가Hadoop이란
 빅 데이터 분야에서 Java 적용 살펴보기: Hadoop, Spark, Kafka 및 기타 기술 스택에 대한 이해
Dec 26, 2023 pm 02:57 PM
빅 데이터 분야에서 Java 적용 살펴보기: Hadoop, Spark, Kafka 및 기타 기술 스택에 대한 이해
Dec 26, 2023 pm 02:57 PM
Java 빅데이터 기술 스택: Hadoop, Spark, Kafka 등 빅데이터 분야에서 Java의 응용을 이해합니다. 데이터의 양이 지속적으로 증가함에 따라 오늘날 인터넷 시대에 빅데이터 기술이 화두가 되고 있습니다. 빅데이터 분야에서 우리는 하둡(Hadoop), 스파크(Spark), 카프카(Kafka) 등의 기술 이름을 자주 듣습니다. 이러한 기술은 매우 중요한 역할을 하며, 널리 사용되는 프로그래밍 언어인 Java는 빅데이터 분야에서도 큰 역할을 합니다. 이 기사에서는 Java의 대규모 애플리케이션에 중점을 둘 것입니다.
 springboot는 mybatis에서 매퍼 파일 검색 경로를 어떻게 지정합니까?
May 17, 2023 pm 10:25 PM
springboot는 mybatis에서 매퍼 파일 검색 경로를 어떻게 지정합니까?
May 17, 2023 pm 10:25 PM
mybatis mybatis.mapper-locations=classpath*:com/springboot/mapper/*.xml의 매퍼 파일 스캔 경로에 모든 매퍼 매핑 파일을 지정하거나 mybatis.mapper-locations=classpath*:mapper/** 리소스 아래의 매퍼 매핑 파일을 지정하세요. /*.xmlmybatis는 여러 스캔 경로를 구성합니다. 작성 방법은 Baidu에서 얻었지만 매우 지저분합니다. 조금 정리하겠습니다. 최근에 프로젝트를 해체하고 약간의 문제가 발생했습니다.
 리눅스에 하둡을 설치하는 방법
May 18, 2023 pm 08:19 PM
리눅스에 하둡을 설치하는 방법
May 18, 2023 pm 08:19 PM
1: JDK1을 설치합니다. 다음 명령을 실행하여 JDK1.8 설치 패키지를 다운로드합니다. wget--no-check-certificatehttps://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz2 다음 명령을 실행하여 다운로드한 JDK1.8 설치 패키지의 압축을 풉니다. . tar-zxvfjdk-8u151-linux-x64.tar.gz3. JDK 패키지를 이동하고 이름을 바꿉니다. mvjdk1.8.0_151//usr/java84. Java 환경 변수를 구성합니다. 에코'
