

Libbson

Libbson is a new shared library written in C for developers wanting to work with the BSON serialization format. Its API will feel natural to C programmers but can also be used as the base of a C extension in higher-level MongoDB drivers. T
Libbson is a new shared library written in C for developers wanting to work with the BSON serialization format.
Its API will feel natural to C programmers but can also be used as the base of a C extension in higher-level MongoDB drivers.
The library contains everything you would expect from a BSON implementation. It has the ability to work with documents in their serialized form, iterating elements within a document, overwriting fields in place, Object Id generation, JSON conversion, data validation, and more. Some lessons were learned along the way that are beneficial for those choosing to implement BSON themselves.
Improving small document performance
A common use case of BSON is for relatively small documents. This has a profound impact on the memory allocator in userspace, causing what is commonly known as “memory fragmentation”. Memory fragmentation can make it more difficult for your allocator to locate a contiguous region of memory.
In addition to increasing allocation latency, it increases the memory requirements of your application to overcome that fragmentation.
To help with this issue, the bson_t structure contains 120 bytes of inline space that allows BSON documents to be built directly on the stack as opposed to the heap.
When the document size grows past 120 bytes it will automatically migrate to a heap allocation.
Additionally, bson_t will grow it’s buffers in powers of two. This is standard when working with buffers and arrays as it amortizes the overhead of growing the buffer versus calling realloc() every time data is appended. 120 bytes was chosen to align bson_t to the size of two sequential cachelines on x86_64 (each 64 bytes).
This may change based on future research, but not before a stable ABI has been reached.
Single allocation for nested documents
One strength of BSON is it’s ability to nest objects and arrays. Often times when serializing these nested documents, each sub-document is serialized independently and then appended to the parents buffer.
As you might imagine, this takes quite the toll on the allocator. It can generate many small allocations which were only created to have been immediately discarded after appending to the parents buffer. Libbson allows for building sub-documents directly into the parent documents buffer.
Doing so helps avoid this costly fragmentation. The topmost document will grow its underlying buffers in powers of two each time the allocation would overflow.
Parsing BSON documents from network buffers
Another common area for allocator fragmentation is during BSON document parsing. Libbson allows parsing and iteration of BSON documents directly from your incoming network buffer.
This means the only allocations created are those needed for your higher level language such as a PyDict if writing a Python extension.
Developers writing C extensions for their driver may choose to implement a “generator” style parsing of documents to help keep memory fragmentation low.
A technique we’re yet to explore is implementing a hashtable-esque structure backed by BSON, only deserializing the entire buffer after a threshold of keys have been accessed.
Generating BSON documents into network buffers
Much like parsing BSON documents, generating documents and placing them into your network buffers can be hard on your memory allocator. To help keep this fragmentation down, Libbson provides support for serializing your document to BSON directly within a buffer of your choosing.
This is ideal for situations such as writing a sequence of BSON documents into a MongoDB message.
Generating Object Ids without Synchronization
Applications are often doing ObjectId generation, especially in high insert environments. The uniqueness of generated ObjectIds is critical to avoiding duplicate key errors across multiple nodes.
Highly threaded environments create a local contention point slowing the rate of generation. This is because the threads must synchronize on the increment counter of each sequential ObjectId. Failure to do so could cause collisions that would not be detected until after a network round-trip. Most drivers implement the synchronization with an atomic increment or a mutex if atomics are not available.
Libbson will use atomic increments and in some cases avoid synchronization altogether if possible. One such case is a non-threaded environment.
Another is when running on Linux as both threads and processes are in the same namespace.
This allows the use of the thread identifier as the pid within the ObjectId.
You can find Libbson at https://github.com/mongodb/libbson and discuss design choices with its author, Christian Hergert, who can be found on twitter as @hergertme.
原文地址:Libbson, 感谢原作者分享。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7328
7328
 9
1626
14
1350
46
1262
25
1209
29
9
1626
14
1350
46
1262
25
1209
29

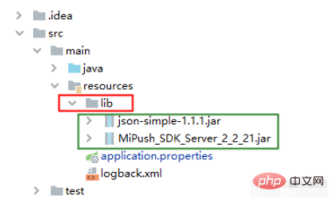 springboot 프로젝트에 로컬 종속성 jar 패키지를 도입하고 lib 폴더에 패키지하는 방법
May 11, 2023 am 11:37 AM
springboot 프로젝트에 로컬 종속성 jar 패키지를 도입하고 lib 폴더에 패키지하는 방법
May 11, 2023 am 11:37 AM
서문: 직장에서 타사 푸시 기능을 통합해야 하는 springboot 프레임워크로 구축된 Javaweb 프로젝트를 접하게 되었고, 그래서 Xiaomi 푸시 서비스를 사용하고 관련 jar 패키지를 다운로드했습니다. 프로젝트에 로컬 jar를 도입하는 것은 큰 문제가 아닙니다. 코드를 작성한 후에는 테스트 클래스 테스트를 통과하는 데 문제가 없습니다. 그런 다음 패키징하고 개발 서버에 배포할 준비를 합니다. 프로젝트는 tomcat을 통해 배포되기 때문에 패키징 방식은 war 패키지로 되어 있습니다. 패키징한 후 개발 서버에 업로드하고, 작성된 푸시 인터페이스를 테스트해 보았는데 실패했습니다. 분석 결과, 프로젝트의 종속 jar가 저장되어 있는 packaged war의 lib 디렉터리에 로컬로 도입된 push 관련 jar 패키지가 포함되어 있지 않은 것으로 나타났습니다. 30분 동안 고민한 끝에 문제가 해결되었습니다. 해결하다
 리눅스에서 lib는 무엇을 의미하나요?
May 23, 2023 pm 07:20 PM
리눅스에서 lib는 무엇을 의미하나요?
May 23, 2023 pm 07:20 PM
Linux에서 lib는 시스템에 유용한 모든 라이브러리 파일이 포함된 라이브러리 파일 디렉터리입니다. 라이브러리 파일은 응용 프로그램, 명령 또는 프로세스를 올바르게 실행하는 데 필요한 파일입니다. lib의 역할은 Windows의 DLL 파일과 유사합니다. 거의 모든 응용 프로그램은 lib 디렉터리에 있는 공유 라이브러리 파일을 사용해야 합니다. lib는 Library(라이브러리)의 약자로 시스템의 가장 기본적인 동적링크 공유 라이브러리를 저장하는 디렉터리로, 그 기능은 Windows의 DLL 파일과 유사하다. 거의 모든 애플리케이션에는 이러한 공유 라이브러리가 필요합니다. /lib 폴더는 라이브러리 파일 디렉터리이며 시스템에 유용한 모든 라이브러리 파일을 포함합니다. 간단히 말해서 응용 프로그램, 명령 또는 프로세스를 올바르게 실행하는 데 필요한 파일입니다. in/bi
 Java에서 new 키워드를 사용하는 방법
May 03, 2023 pm 10:16 PM
Java에서 new 키워드를 사용하는 방법
May 03, 2023 pm 10:16 PM
1. 개념 Java 언어에서 "new" 표현식은 인스턴스를 생성하는 역할을 하며 생성자가 인스턴스를 초기화하기 위해 호출됩니다. 생성자 자체의 반환 값 유형은 "생성자가 새로 생성된 값을 반환합니다." 개체 참조"이지만 새 표현식의 값은 새로 생성된 개체에 대한 참조입니다. 2. 목적: 새 클래스의 객체를 생성합니다. 3. 작동 메커니즘: 객체 멤버에 대한 메모리 공간을 할당하고, 멤버 변수를 명시적으로 초기화하고, 생성 방법 계산을 수행하고, 참조 값을 자주 반환합니다. 메모리에서 새로운 메모리를 여는 것을 의미합니다. 메모리 공간은 메모리의 힙 영역에 할당되며 jvm에 의해 제어되며 자동으로 메모리를 관리합니다. 여기서는 String 클래스를 예로 사용합니다. 푸

 new 연산자는 js에서 어떻게 작동하나요?
Feb 19, 2024 am 11:17 AM
new 연산자는 js에서 어떻게 작동하나요?
Feb 19, 2024 am 11:17 AM
js의 new 연산자는 어떻게 작동하나요? 구체적인 코드 예제가 필요합니다. js의 new 연산자는 객체를 생성하는 데 사용되는 키워드입니다. 그 기능은 지정된 생성자를 기반으로 새 인스턴스 개체를 만들고 개체에 대한 참조를 반환하는 것입니다. new 연산자를 사용할 때 실제로 다음 단계가 수행됩니다. 빈 개체의 프로토타입을 생성자의 프로토타입 개체에 지정하고 생성자의 범위를 새 개체에 할당합니다. 객체) 생성자에서 코드를 실행하고 새 객체를 제공합니다.
 리눅스가 lib를 찾을 수 없다면 어떻게 해야 할까요?
Feb 28, 2023 am 09:59 AM
리눅스가 lib를 찾을 수 없다면 어떻게 해야 할까요?
Feb 28, 2023 am 09:59 AM
Linux에서 lib를 찾을 수 없는 경우 해결 방법: 1. 프로그램의 lib 라이브러리를 "/lib" 또는 "/usr/local/lib" 디렉터리에 복사한 다음 "ldconfig"를 실행합니다. 2. "ld.so.conf"에서; 라이브러리 파일이 있는 디렉터리를 추가한 후 "ld.so.cache" 파일을 업데이트합니다.
 Go 언어에서 make와 new의 차이점은 무엇입니까
Jan 09, 2023 am 11:44 AM
Go 언어에서 make와 new의 차이점은 무엇입니까
Jan 09, 2023 am 11:44 AM
차이점: 1. Make는 Slice, Map 및 chan 유형의 데이터를 할당하고 초기화하는 데만 사용할 수 있는 반면 new는 모든 유형의 데이터를 할당할 수 있습니다. 2. 새 할당은 "*Type" 유형인 포인터를 반환하고 make는 유형인 참조를 반환합니다. 3. new에 의해 할당된 공간은 지워집니다. make가 공간을 할당한 후에는 초기화됩니다.
 새로운 후지필름 고정 렌즈 GFX 카메라, 새로운 중형 포맷 센서 선보이며 완전히 새로운 시리즈 시작 가능
Sep 27, 2024 am 06:03 AM
새로운 후지필름 고정 렌즈 GFX 카메라, 새로운 중형 포맷 센서 선보이며 완전히 새로운 시리즈 시작 가능
Sep 27, 2024 am 06:03 AM
Fujifilm은 필름 시뮬레이션과 소셜 미디어에서의 소형 레인지핑거 스타일 카메라의 인기 덕분에 최근 몇 년 동안 많은 성공을 거두었습니다. 그러나 Fujirumors에 따르면, 현재의 성공에 안주하지 않는 것 같습니다. 당신
