

搭建Hadoop环境的详细过程

即上一篇《初步了解Hadoop》已经过去好多天了,今天继续hadoop学习之旅。大体了解hadoop原理,我们想先搭建hadoop环境,在这个过程中慢慢体会一下hadoop。 我在这里说的是hadoop伪分布式模式(Pseudo-Distributed Mode),其实网上已经有很多教程,在这里我
即上一篇《初步了解Hadoop》已经过去好多天了,今天继续hadoop学习之旅。大体了解hadoop原理,我们想先搭建hadoop环境,在这个过程中慢慢体会一下hadoop。
我在这里说的是hadoop伪分布式模式(Pseudo-Distributed Mode),其实网上已经有很多教程,在这里我详详细细的描述整个搭建过程,也算是自己重新回忆一下。
准备阶段(下载地址我这里就不给出了):
Win7旗舰版 Vmware-9.0.2
ubuntu-12.04 hadoop-0.20.2 jdk-8u5-linux-i586-demos
搭建流程:
1、装机阶段:
一、安装Ubuntu操作系统
二、在Ubuntu下创建hadoop用户组和用户
三、在Ubuntu下安装JDK
四、修改机器名
五、安装ssh服务
六、建立ssh无密码登录本机
七、安装hadoop
八、在单机上运行hadoop
一、安装Ubuntu操作系统
略……
二、在Ubuntu下创建hadoop用户组和用户
(1)安装Ubuntu时已经建立了一个用户,但是为了以后Hadoop操作,专门渐建立一个hadoop用户组和hadoop用户。

(2)给hadoop用户添加权限,打开/etc/sudoers文件。
sudo gedit /etc/sudoers
打开/etc/sudoers文件了,给hadoop用户赋予root用户同样的权限。在
root ALL=(ALL:ALL) ALL
下添加:
hadoop ALL=(ALL:ALL) ALL
三、在Ubuntu下安装JDK
1、创建JDK安装目录
(1)由于我使用的是VMware安装的Ubuntu系统,设置本地thisceshi文件夹共享到Ubuntu系统,指定的安装目录是:/usr/local/java。可是系统安装后在/usr/local下并没有java目录,这需要我们去创建一个java文件夹,
进入/usr/local文件夹
cd /usr/local
创建java文件夹,
sudo mkdir /usr/local/java
(2)解压JDK到目标目录
进入共享文件夹thisceshi,
cd /mnt/hgfs/thisceshi
然后进入到共享文件夹中,继续我们解压JDK到之前建好的java文件夹中,
sudo cp jdk-8u5-linux-i586-demos.tar.gz /usr/local/java
2、安装jdk
(1)切换到root用户下,
hadoop@s15:/mnt/hgfs/thisceshi$ su 密码:
(2)解压jdk-8u5-linux-i586-demos.tar.gz
sudo tar -zxf jdk-8u5-linux-i586-demos.tar.gz
此时java目录中多了一个jdk1.6.0_30文件夹。
3、配置环境变量
(1)打开/etc/profile文件,
sudo gedit /etc/profile
(2)添加变量,
#set java environment export JAVA_HOME=/usr/local/java/jdk1.6.0_30 export JRE_HOME=/usr/local/java/jdk1.6.0_30/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH
一般更改/etc/profile文件后,需要重启机器才能生效,在这里我们可以使用如下指令可使配置文件立即生效,
source /etc/profile
(3)查看java环境变量是否配置成功,
java -version
显示如下:
java version "1.6.0_30" Java(TM) SE Runtime Environment (build 1.6.0_30-b12) Java HotSpot(TM) Client VM (build 20.5-b03, mixed mode, sharing)
但是在root下一切正常,在hadoop用户下就出现了问题,
程序“java”已包含在下列软件包中: * gcj-4.4-jre-headless * openjdk-6-jre-headless * cacao * gij-4.3 * jamvm
在终端中我们分别运行下面指令,
sudo update-alternatives --install /usr/bin/java java /usr/local/java/jdk1.6.0_30/bin/java 300 sudo update-alternatives --install /usr/bin/javac javac /usr/local/java/jdk1.6.0_30/bin/javac 300
问题解决。
四、修改机器名
当ubuntu安装成功时,我们的机器名都默认为:ubuntu ,但为了以后集群中能够容易分辨各台服务器,需要给每台机器取个不同的名字。机器名由 /etc/hostname文件决定。这是我开始是根据网上教程也给修改了,其实伪分布式搭建的时候,可以省了,不然还造成一些不必要的麻烦。
1、打开/etc/hostname文件,运行指令,
sudo gedit /etc/hostname
2、然后hostname中添加s15五、安装ssh服务保存退出,即s15是当前用户别名。在这里需要重启系统后才会生效。
hadoop@s15:~$
五、安装ssh服务
1、安装openssh-server
sudo apt-get install openssh-server
2、等待安装,即可。



六、 建立ssh无密码登录本机
在这里,我自己还是模模糊糊的。
ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式。
1、创建ssh-key,,这里我们采用rsa方式,
ssh-keygen -t rsa -P ''
网上教程中后面是双引号,我在执行出现错误,换成单引号,则可以执行。

进入ssh,查看里面文件
hadoop@s15:~$ cd .ssh hadoop@s15:~/.ssh$ ls id_rsa id_rsa.pub
2、进入~/.ssh/目录下,将idrsa.pub追加到authorizedkeys授权文件中,开始是没有authorized_keys文件的,
cat id_rsa.pub >> authorized_keys
3、登录localhost,
hadoop@s15:~/.ssh$ ssh localhost Welcome to Ubuntu 12.04 LTS (GNU/Linux 3.2.0-61-generic-pae i686) * Documentation: https://help.ubuntu.com/ 663 packages can be updated. 266 updates are security updates. Last login: Sat May 10 13:08:03 2014 from localhost
4、执行退出命令,
hadoop@s15:~$ exit 登出 Connection to localhost closed.
七、安装hadoop
1、从共享文件夹thisceshi中将hadoop-0.20.2.tar.gz复制到安装目录 /usr/local/下
2、解压hadoop-0.20.203.tar.gz,
3、将解压出的文件夹改名为hadoop,
4、将该hadoop文件夹的属主用户设为hadoop,
sudo chown -R hadoop:hadoop hadoop
5、打开hadoop/conf/hadoop-env.sh文件,
6、配置conf/hadoop-env.sh(找到#export JAVA_HOME=…,去掉#,然后加上本机jdk的路径)
# The java implementation to use. Required. export JAVA_HOME=/usr/local/java/jdk1.6.0_30 export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:/usr/local/hadoop/bin
让环境立即生效,
source /usr/local/hadoop/conf/hadoop-env.sh
7、打开conf/core-site.xml文件,编辑如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://www.cndwzone.com/archives/configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> fs.default.name hdfs://localhost:9000
8、打开conf/mapred-site.xml文件,编辑如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://www.cndwzone.com/archives/configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> mapred.job.tracker localhost:9001
9、打开conf/hdfs-site.xml文件,编辑如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://www.cndwzone.com/archives/configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> dfs.name.dir /usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2 dfs.data.dir /usr/local/hadoop/data1,/usr/local/hadoop/data2 dfs.replication 2
10、打开conf/masters文件,添加作为secondarynamenode的主机名,因为是伪分布式,只有一个节点,这里只需填写localhost就可以。
11、打开conf/slaves文件,添加作为slave的主机名,一行一个。因为是伪分布式,只有一个节点,这里也只需填写localhost就可以。
八、在单机上运行hadoop
1、进入hadoop目录下,格式化hdfs文件系统,初次运行hadoop时一定要有该操作,当你看到下图时,就说明你的hdfs文件系统格式化成功了。

3、进入bin目录启动start-all.sh,
4、检测hadoop是否启动成功,

到此,hadoop伪分布式环境搭建完成。
在搭建过程中可能会遇到各种问题,到时大家不用着急,可以谷歌,百度一下。解决问题的过程就是加深学习的过程。我当时都忘了花了多久才将环境搭建好,最初的时候,连最基本的指令也不懂,也不知道怎么运行。我在这里说出来就是想说,开始的一无所知不要害怕,慢慢来就好,在那么一刻你就会有所知,有所明白。之后的文章中会介绍在hadoop环境下运行WordCount,hadoop中的HelloWorld。
 即上一篇《初步了解Hadoop》已经过去好多天了,今天继续hadoop学习之旅。大体了解hadoop原理,我们 […]
即上一篇《初步了解Hadoop》已经过去好多天了,今天继续hadoop学习之旅。大体了解hadoop原理,我们 […]

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7566
7566
 15
1386
52
87
11
61
19
28
105
15
1386
52
87
11
61
19
28
105

 Windows 복구 환경으로 부팅할 수 없습니다
Feb 19, 2024 pm 11:12 PM
Windows 복구 환경으로 부팅할 수 없습니다
Feb 19, 2024 pm 11:12 PM
WinRE(Windows 복구 환경)는 Windows 운영 체제 오류를 복구하는 데 사용되는 환경입니다. WinRE에 들어간 후 시스템 복원, 공장 초기화, 업데이트 제거 등을 수행할 수 있습니다. WinRE로 부팅할 수 없는 경우 이 문서에서는 문제 해결을 위한 수정 사항을 안내합니다. Windows 복구 환경으로 부팅할 수 없습니다. Windows 복구 환경으로 부팅할 수 없는 경우 아래 제공된 수정 사항을 사용하십시오. Windows 복구 환경 상태 확인 다른 방법을 사용하여 Windows 복구 환경으로 들어가십시오. 실수로 Windows 복구 파티션을 삭제하셨습니까? 아래에서 전체 업그레이드 또는 Windows 새로 설치를 수행하십시오. 이러한 모든 수정 사항에 대해 자세히 설명했습니다. 1] Wi-Fi 확인
 Python과 Anaconda의 차이점은 무엇입니까?
Sep 06, 2023 pm 08:37 PM
Python과 Anaconda의 차이점은 무엇입니까?
Sep 06, 2023 pm 08:37 PM
이번 포스팅에서는 Python과 Anaconda의 차이점에 대해 알아보겠습니다. 파이썬이란 무엇입니까? Python은 줄을 들여쓰고 공백을 제공하여 코드를 읽고 이해하기 쉽게 만드는 데 중점을 둔 오픈 소스 언어입니다. Python의 유연성과 사용 용이성은 과학 컴퓨팅, 인공 지능, 데이터 과학은 물론 온라인 애플리케이션 생성 및 개발을 포함하되 이에 국한되지 않는 다양한 애플리케이션에 이상적입니다. Python은 해석된 언어이기 때문에 테스트를 하면 즉시 기계어로 번역됩니다. C++와 같은 일부 언어를 이해하려면 컴파일이 필요합니다. Python에 대한 능숙도는 이해, 개발, 실행 및 읽기가 매우 쉽기 때문에 중요한 이점입니다. 이는 파이썬을
 Java 오류: Hadoop 오류, 처리 및 방지 방법
Jun 24, 2023 pm 01:06 PM
Java 오류: Hadoop 오류, 처리 및 방지 방법
Jun 24, 2023 pm 01:06 PM
Java 오류: Hadoop 오류, 처리 및 방지 방법 Hadoop을 사용하여 빅 데이터를 처리할 때 작업 실행에 영향을 미치고 데이터 처리 실패를 유발할 수 있는 Java 예외 오류가 자주 발생합니다. 이 기사에서는 몇 가지 일반적인 Hadoop 오류를 소개하고 이를 처리하고 방지하는 방법을 제공합니다. Java.lang.OutOfMemoryErrorOutOfMemoryError는 Java 가상 머신의 메모리 부족으로 인해 발생하는 오류입니다. 하둡이 있을 때
 Vue 프레임워크에서 통계 차트 시스템을 빠르게 구축하는 방법
Aug 21, 2023 pm 05:48 PM
Vue 프레임워크에서 통계 차트 시스템을 빠르게 구축하는 방법
Aug 21, 2023 pm 05:48 PM
Vue 프레임워크에서 통계 차트 시스템을 빠르게 구축하는 방법 최신 웹 애플리케이션에서 통계 차트는 필수 구성 요소입니다. 널리 사용되는 프런트엔드 프레임워크인 Vue.js는 통계 차트 시스템을 신속하게 구축하는 데 도움이 되는 많은 편리한 도구와 구성 요소를 제공합니다. 이 기사에서는 Vue 프레임워크와 일부 플러그인을 사용하여 간단한 통계 차트 시스템을 구축하는 방법을 소개합니다. 먼저 Vue 스캐폴딩 및 일부 관련 플러그인 설치를 포함하여 Vue.js 개발 환경을 준비해야 합니다. 명령줄에서 다음 명령을 실행합니다.
 Mistlock Kingdom의 야생에서도 건물을 지을 수 있나요?
Mar 07, 2024 pm 08:28 PM
Mistlock Kingdom의 야생에서도 건물을 지을 수 있나요?
Mar 07, 2024 pm 08:28 PM
플레이어는 Mistlock 왕국에서 플레이할 때 건물을 짓기 위해 다양한 재료를 수집할 수 있습니다. 많은 플레이어가 야생에서 건물을 지을 수 있는지 알고 싶어합니다. Mistlock 왕국에서는 건물이 제단 범위 내에 있어야 합니다. . Mistlock Kingdom에서는 야생에 건물을 지을 수 있나요? 답변: 아니요. 1. 미스트락 왕국의 야생 지역에는 건물을 지을 수 없습니다. 2. 건물은 제단의 범위 내에서 건축되어야 한다. 3. 플레이어 스스로 Spirit Fire Altar를 설치할 수 있지만, 범위를 벗어나면 건물을 지을 수 없습니다. 4. 산에 직접 구멍을 파서 집으로 삼을 수도 있어 건축자재를 소모할 필요가 없습니다. 5. 플레이어가 직접 지은 건물에는 편안함 메커니즘이 있습니다. 즉, 인테리어가 좋을수록 편안함이 높아집니다. 6. 높은 편안함은 플레이어에게 다음과 같은 속성 보너스를 제공합니다.
 빅 데이터 저장 및 쿼리를 위해 Beego에서 Hadoop 및 HBase 사용
Jun 22, 2023 am 10:21 AM
빅 데이터 저장 및 쿼리를 위해 Beego에서 Hadoop 및 HBase 사용
Jun 22, 2023 am 10:21 AM
빅데이터 시대가 도래하면서 데이터의 처리와 저장이 더욱 중요해지고 있으며, 대용량 데이터를 어떻게 효율적으로 관리하고 분석할 것인가가 기업의 과제가 되었습니다. Apache Foundation의 두 가지 프로젝트인 Hadoop과 HBase는 빅데이터 저장 및 분석을 위한 솔루션을 제공합니다. 이 기사에서는 빅데이터 저장 및 쿼리를 위해 Beego에서 Hadoop 및 HBase를 사용하는 방법을 소개합니다. 1. Hadoop 및 HBase 소개 Hadoop은 오픈 소스 분산 스토리지 및 컴퓨팅 시스템입니다.
 CentOS 7에서 웹 서버를 구축하기 위한 모범 사례 및 예방 조치
Aug 25, 2023 pm 11:33 PM
CentOS 7에서 웹 서버를 구축하기 위한 모범 사례 및 예방 조치
Aug 25, 2023 pm 11:33 PM
CentOS7에서 웹 서버 구축을 위한 모범 사례 및 예방 조치 소개: 오늘날 인터넷 시대에 웹 서버는 웹 사이트 구축 및 호스팅을 위한 핵심 구성 요소 중 하나입니다. CentOS7은 서버 환경에서 널리 사용되는 강력한 Linux 배포판입니다. 이 문서에서는 CentOS7에서 웹 서버를 구축하기 위한 모범 사례와 고려 사항을 살펴보고 이해를 돕기 위한 몇 가지 코드 예제를 제공합니다. 1. Apache HTTP 서버 설치 Apache는 가장 널리 사용되는 서버입니다.
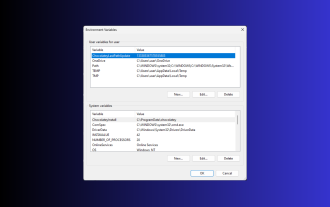 Windows 3에서 환경 변수를 설정하는 11가지 방법
Sep 15, 2023 pm 12:21 PM
Windows 3에서 환경 변수를 설정하는 11가지 방법
Sep 15, 2023 pm 12:21 PM
Windows 11에서 환경 변수를 설정하면 시스템을 사용자 지정하고, 스크립트를 실행하고, 애플리케이션을 구성하는 데 도움이 될 수 있습니다. 이 가이드에서는 시스템을 원하는 대로 구성할 수 있도록 단계별 지침과 함께 세 가지 방법을 설명합니다. 환경 변수에는 세 가지 유형이 있습니다. 시스템 환경 변수 - 전역 변수는 우선 순위가 가장 낮고 Windows의 모든 사용자 및 응용 프로그램에 액세스할 수 있으며 일반적으로 시스템 전체 설정을 정의하는 데 사용됩니다. 사용자 환경 변수 – 우선 순위가 더 높은 이러한 변수는 현재 사용자 및 해당 계정에서 실행되는 프로세스에만 적용되며 해당 계정에서 실행되는 사용자 또는 응용 프로그램에 의해 설정됩니다. 프로세스 환경 변수 – 우선 순위가 가장 높고 임시적이며 현재 프로세스와 해당 하위 프로세스에 적용되어 프로그램을 제공합니다.
