

hadoop重启Namenode时,appTokens报FileNotFoundException

现象 报错如下 Application application_1405852606905_0014 failed 3 times due to AM Container for appattempt_1405852606905_0014_000003 exited with exitCode: -1000 due to: RemoteTrace: java.io.FileNotFoundException: File does not exist: hdfs:
现象
报错如下
Application application_1405852606905_0014 failed 3 times due to AM Container for appattempt_1405852606905_0014_000003 exited with exitCode: -1000 due to: RemoteTrace: java.io.FileNotFoundException: File does not exist: hdfs://mycluster:8020/user/kpi/.staging/job_1405852606905_0014/appTokens at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:809)
同时注意到是因为每次重启nodemanager才发生。
首先用关键词“apptokens FileNotFoundException”在google和issue搜索没找到相关的问题。
猜测原因
可能找不到的原因:1.客户端没上传成功 2.上传成功了,但后面不知道给谁删了
重现
既然在网上找不到,尝试在测试环境重现这个问题,运行一个sleep job
cd /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce; hadoop jar hadoop-mapreduce-client-*-tests.jar sleep -Dmapred.job.queue.name=sleep -m5 -r5 -mt 60000 -rt 30000 -recordt 1000
重启nodemanage后会发现报错。
分析日志
但发现找不到AM的日志,哪里去了?我们的hadoop环境都配置了“日志聚集”(yarn.log-aggregation-enable),失败的任务就把日志删了(可能是bug),尝试关掉后,从crontainer日志找到AM日志。
同时还可以看ResourceManager,NameNode,HDFS审计日志(hdfs-audit.log)
从AM日志可以看到第一次尝试好像是成功的,从HDFS审计日志发现了删除staging的目录
cmd=delete src="http://fatkun.com/user/kpi/.staging/job_1405852606905_0013
到此可以确认目录是被删除了,导致后面的job失败,但谁删了这个目录?
继续搜索
代码很多,需要定位一下那里操作.staging这个目录,确定谁删了这个目录。在issue搜索“staging delete”,看有没有相关的操作代码。 同时阅读代码发现了org.apache.hadoop.mapreduce.v2.app.MRAppMaster.cleanupStagingDir()方法,对照日志,可以确定是这个方法删除了staging目录。
public synchronized void stop() {
...
//这里判断了是不是AM的最后一次尝试,如果是才清理
if(isLastAMRetry) {
cleanupStagingDir();
}
...
}这个逻辑还算正常, 继续找isLastAMRetry是怎么来的
public void shutDownJob() {
...
//We are finishing cleanly so this is the last retry
isLastAMRetry = true;
// Stop all services
// This will also send the final report to the ResourceManager
LOG.info("Calling stop for all the services");
MRAppMaster.this.stop();
...
}发现调用了shutDownJob,会把isLastAMRetry设置为true,调用shutDownJob是因为接收到JobFinishEvent事件。
我们多了一些信息,偷懒在issue继续搜索一下,看有没有人解决了。
这次找到issue了,https://issues.apache.org/jira/browse/MAPREDUCE-5086
阅读patch,发现之前忽略了RM报的一个错误。
org.apache.hadoop.yarn.exceptions.impl.pb.YarnRemoteExceptionPBImpl: Application doesn't exist in cache appattempt_1405852606905_0014_000001
结果
重启nodemanager导致RM的appattempt cache数组删除,JobImpl返回了InternalError,AM认为出错了就没必要重试了,直接置isLastRetry=true。
修改方式是加了一个状态,表明这是“RM重启”了(注意这里不是nodemanager重启,有一些关联),还可以继续重试。具体修改阅读patch https://issues.apache.org/jira/browse/MAPREDUCE-5086
最后,由于patch修改的版本和我们用的版本不一致,还得需要用我们使用的版本依照它的思路改一遍。
原文地址:hadoop重启Namenode时,appTokens报FileNotFoundException, 感谢原作者分享。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7488
7488
 15
1377
52
77
11
52
19
19
40
15
1377
52
77
11
52
19
19
40

 Samsung s24Ultra 전화를 다시 시작하는 방법은 무엇입니까?
Feb 09, 2024 pm 09:54 PM
Samsung s24Ultra 전화를 다시 시작하는 방법은 무엇입니까?
Feb 09, 2024 pm 09:54 PM
Samsung S24 Ultra 휴대폰을 사용할 때 가끔 문제가 발생하거나 장치를 재설정해야 할 수 있습니다. 이 경우 전화를 다시 시작하는 것이 일반적인 해결 방법입니다. 그러나 단계에 대해 잘 모르면 혼란스러울 수 있습니다. 하지만 걱정하지 마세요. Samsung S24 Ultra 휴대폰을 올바르게 다시 시작하는 방법을 알려 드리겠습니다. Samsung s24 Ultra를 다시 시작하는 방법 1. 제어 메뉴를 불러와 종료: 삼성 화면 상단에서 아래로 밀어 바로가기 도구 메뉴를 불러오고, 전원 아이콘(호와 수직선의 조합)을 클릭하여 종료합니다. 종료 및 다시 시작 선택 인터페이스를 실행하려면 그냥 다시 시작을 클릭합니다. 2. 종료하려면 키 조합을 사용합니다. 볼륨 키와 전원 키를 길게 눌러 종료 및 다시 시작 선택 메뉴를 불러오고 클릭하여 종료를 선택합니다. 길게 누르면
 Windows 11에서 F5 새로 고침 키가 작동하지 않습니다.
Mar 14, 2024 pm 01:01 PM
Windows 11에서 F5 새로 고침 키가 작동하지 않습니다.
Mar 14, 2024 pm 01:01 PM
Windows 11/10 PC에서 F5 키가 제대로 작동하지 않나요? F5 키는 일반적으로 데스크탑이나 탐색기를 새로 고치거나 웹 페이지를 다시 로드하는 데 사용됩니다. 그러나 일부 독자들은 F5 키가 컴퓨터를 새로 고치고 제대로 작동하지 않는다고 보고했습니다. Windows 11에서 F5 새로 고침을 활성화하는 방법은 무엇입니까? Windows PC를 새로 고치려면 F5 키를 누르십시오. 일부 노트북이나 데스크탑에서는 새로 고침 작업을 완료하려면 Fn+F5 키 조합을 눌러야 할 수도 있습니다. F5 새로 고침이 작동하지 않는 이유는 무엇입니까? F5 키를 눌러도 컴퓨터가 새로 고쳐지지 않거나 Windows 11/10에서 문제가 발생하는 경우 기능 키가 잠겨 있기 때문일 수 있습니다. 다른 잠재적인 원인으로는 키보드 또는 F5 키가 있습니다.
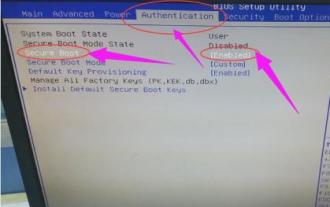 컴퓨터 프롬프트 '재부팅 및 적절한 부팅 장치 선택'을 해결하는 방법
Jan 15, 2024 pm 02:00 PM
컴퓨터 프롬프트 '재부팅 및 적절한 부팅 장치 선택'을 해결하는 방법
Jan 15, 2024 pm 02:00 PM
시스템을 다시 설치하는 것이 완벽한 해결책은 아닐 수 있지만 다시 설치한 후 컴퓨터를 켜면 검은색 배경에 흰색 텍스트가 표시되고 재부팅하고 적절한 부팅 장치를 선택하라는 메시지가 표시됩니다. 무슨 일이 일어나고 있는 걸까요? 이러한 프롬프트는 일반적으로 부팅 오류로 인해 발생합니다. 모두를 돕기 위해 편집자가 해결책을 제시했습니다. 컴퓨터 사용이 점점 더 대중화되고 컴퓨터 오류가 점점 더 흔해지고 있습니다. 아니요, 최근 일부 사용자에게 컴퓨터를 켤 때 검은색 화면이 나타나고 재부팅하고 적절한 부팅 장치를 선택하라는 메시지가 표시되어 컴퓨터 시스템을 시작할 수 없습니다. 보통. 무슨 일이야? 어떻게 해결하나요? 사용자는 혼란스러워하고 다음으로 편집자가 따릅니다.
 nginx를 다시 시작하는 방법
Jul 27, 2023 pm 05:21 PM
nginx를 다시 시작하는 방법
Jul 27, 2023 pm 05:21 PM
nginx를 다시 시작하는 방법: 1. Linux에서 Nginx를 다시 시작하고 systemd를 사용하여 Nginx를 다시 시작하고 새 구성 변경 사항을 읽습니다. 2. Windows에서 Nginx를 다시 시작하면 구성 변경 사항이 적용됩니다. , 서버를 완전히 중지하고 시작하지 않고도 3. Mac에서 Nginx를 다시 시작합니다. 그러면 Nginx가 다시 시작되고 새로운 구성 변경 사항 등이 적용됩니다.
 컴퓨터를 다시 시작하는 Python 스크립트
Sep 08, 2023 pm 05:21 PM
컴퓨터를 다시 시작하는 Python 스크립트
Sep 08, 2023 pm 05:21 PM
컴퓨터를 다시 시작하는 것은 문제 해결, 업데이트 설치 또는 시스템 변경 사항 적용을 위해 자주 수행하는 일반적인 작업입니다. 컴퓨터를 다시 시작하는 방법에는 여러 가지가 있지만 Python 스크립트를 사용하면 자동화와 편의성이 제공됩니다. 이 기사에서는 간단한 실행으로 컴퓨터를 다시 시작할 수 있는 Python 스크립트를 만드는 방법을 살펴보겠습니다. 먼저 컴퓨터를 다시 시작하는 것의 중요성과 이로 인해 얻을 수 있는 이점에 대해 논의하겠습니다. 그런 다음 Python 스크립트의 구현 세부 사항을 살펴보고 관련된 필수 모듈과 기능을 설명합니다. 이 기사 전체에서 명확한 이해를 돕기 위해 자세한 설명과 코드 조각을 제공할 것입니다. 컴퓨터 다시 시작의 중요성 컴퓨터를 다시 시작하는 것은 다음을 수행할 수 있는 기본적인 문제 해결 단계입니다.
 Java 오류: Hadoop 오류, 처리 및 방지 방법
Jun 24, 2023 pm 01:06 PM
Java 오류: Hadoop 오류, 처리 및 방지 방법
Jun 24, 2023 pm 01:06 PM
Java 오류: Hadoop 오류, 처리 및 방지 방법 Hadoop을 사용하여 빅 데이터를 처리할 때 작업 실행에 영향을 미치고 데이터 처리 실패를 유발할 수 있는 Java 예외 오류가 자주 발생합니다. 이 기사에서는 몇 가지 일반적인 Hadoop 오류를 소개하고 이를 처리하고 방지하는 방법을 제공합니다. Java.lang.OutOfMemoryErrorOutOfMemoryError는 Java 가상 머신의 메모리 부족으로 인해 발생하는 오류입니다. 하둡이 있을 때
 Linux에서 서비스를 다시 시작하는 올바른 방법은 무엇입니까?
Mar 15, 2024 am 09:09 AM
Linux에서 서비스를 다시 시작하는 올바른 방법은 무엇입니까?
Mar 15, 2024 am 09:09 AM
Linux에서 서비스를 다시 시작하는 올바른 방법은 무엇입니까? Linux 시스템을 사용하다 보면 서비스를 다시 시작해야 하는 상황이 자주 발생하지만, 서비스를 다시 시작할 때 서비스가 실제로 중지되지 않거나 시작되지 않는 등의 문제가 발생할 수도 있습니다. 따라서 서비스를 다시 시작하는 올바른 방법을 익히는 것이 매우 중요합니다. Linux에서는 일반적으로 systemctl 명령을 사용하여 시스템 서비스를 관리할 수 있습니다. systemctl 명령은 systemd 시스템 관리자의 일부입니다.
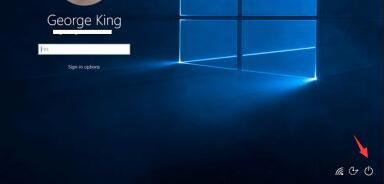 win10에서 비밀번호 입력 후 루프에서 다시 시작되는 문제 해결
Dec 29, 2023 pm 09:53 PM
win10에서 비밀번호 입력 후 루프에서 다시 시작되는 문제 해결
Dec 29, 2023 pm 09:53 PM
실수로 잘못된 작업을 수행하거나 시스템 자체에 특정 오류가 있는 경우 비밀번호를 입력하고 계속 다시 시작한 후 데스크탑에 들어가지 못할 수 있습니다. 이때는 안전 모드에서 복구할 수 있습니다. 아래에서 구체적인 방법을 살펴보겠습니다. 암호를 입력한 후 Win10이 바탕 화면에 들어갈 수 없고 계속 다시 시작됩니다. 해결 방법 1. 먼저 키보드의 "Shift"를 길게 누르고 오른쪽 하단에 있는 전원 버튼을 클릭한 다음 복구 인터페이스가 나타날 때까지 컴퓨터를 다시 시작하도록 선택합니다. 그런 다음 "shift" 키를 놓습니다. 2. 오른쪽 하단에 전원 버튼이 없는 경우 컴퓨터 호스트의 전원 버튼을 사용할 수도 있지만 세 번 이상 연속으로 다시 시작해야 합니다. 3. 복구 인터페이스가 나타나면 "고급 복구 옵션 보기"를 클릭합니다. 4. "문제 해결"을 선택하십시오. 5
