

Hadoop作业调优参数整理及原理

原文 ? http://www.blogjava.net/wangxinsh55/archive/2014/11/19/420297.html http://www.linuxidc.com/Linux/2012-01/51615.htm 1 Map side tuning 参数 1.1 MapTask 运行内部原理 当map task 开始运算,并产生中间数据时,其产生的中间结果并非直接就简单
http://www.linuxidc.com/Linux/2012-01/51615.htm
1 Map side tuning 参数
1.1 MapTask 运行内部原理

当map task 开始运算,并产生中间数据时,其产生的中间结果并非直接就简单的写入磁盘。这中间的过程比较复杂,并且利用到了内存buffer 来进行已经产生的部分结果的缓存,并在内存buffer 中进行一些预排序来优化整个map 的性能。如上图所示,每一个map 都会对应存在一个内存buffer (MapOutputBuffer ,即上图的buffer in memory ),map 会将已经产生的部分结果先写入到该buffer 中,这个buffer 默认是100MB 大小,但是这个大小是可以根据job 提交时的参数设定来调整的,该参数即为:io.sort.mb 。当map 的产生数据非常大时,并且把io.sort.mb 调大,那么map 在整个计算过程中spill 的次数就势必会降低,map task 对磁盘的操作就会变少,如果map tasks 的瓶颈在磁盘上,这样调整就会大大提高map 的计算性能。map 做sort 和spill 的内存结构如下如所示:

map 在运行过程中,不停的向该buffer 中写入已有的计算结果,但是该buffer 并不一定能将全部的map 输出缓存下来,当map 输出超出一定阈值(比如100M ),那么map 就必须将该buffer 中的数据写入到磁盘中去,这个过程在mapreduce 中叫做spill 。map 并不是要等到将该buffer 全部写满时才进行spill ,因为如果全部写满了再去写spill ,势必会造成map 的计算部分等待buffer 释放空间的情况。所以,map 其实是当buffer 被写满到一定程度(比如80% )时,就开始进行spill 。这个阈值也是由一个job 的配置参数来控制,即 io.sort.spill.percent ,默认为0.80 或80% 。这个参数同样也是影响spill 频繁程度,进而影响map task 运行周期对磁盘的读写频率的。但非特殊情况下,通常不需要人为的调整。调整io.sort.mb 对用户来说更加方便。
当map task 的计算部分全部完成后,如果map 有输出,就会生成一个或者多个spill 文件,这些文件就是map 的输出结果。map 在正常退出之前,需要将这些spill 合并(merge )成一个,所以map 在结束之前还有一个merge 的过程。merge 的过程中,有一个参数可以调整这个过程的行为,该参数为: io.sort.factor 。该参数默认为10 。它表示当merge spill 文件时,最多能有多少并行的stream 向merge 文件中写入。比如如果map 产生的数据非常的大,产生的spill 文件大于10 ,而io.sort.factor 使用的是默认的10 ,那么当map 计算完成做merge 时,就没有办法一次将所有的spill 文件merge 成一个,而是会分多次,每次最多10 个stream 。这也就是说,当map 的中间结果非常大,调大io.sort.factor ,有利于减少merge 次数,进而减少map 对磁盘的读写频率,有可能达到优化作业的目的。
当job 指定了combiner 的时候,我们都知道map 介绍后会在map 端根据combiner 定义的函数将map 结果进行合并。运行combiner 函数的时机有可能会是merge 完成之前,或者之后,这个时机可以由一个参数控制,即 min.num.spill.for.combine(default 3 ),当job 中设定了combiner ,并且spill 数最少有3 个的时候,那么combiner 函数就会在merge 产生结果文件之前运行。通过这样的方式,就可以在spill 非常多需要merge ,并且很多数据需要做conbine 的时候,减少写入到磁盘文件的数据数量,同样是为了减少对磁盘的读写频率,有可能达到优化作业的目的。
减少中间结果读写进出磁盘的方法不止这些,还有就是压缩。也就是说map 的中间,无论是spill 的时候,还是最后merge 产生的结果文件,都是可以压缩的。压缩的好处在于,通过压缩减少写入读出磁盘的数据量。对中间结果非常大,磁盘速度成为map 执行瓶颈的job ,尤其有用。控制map 中间结果是否使用压缩的参数为:mapred.compress.map.output (true/false) 。将这个参数设置为true 时,那么map 在写中间结果时,就会将数据压缩后再写入磁盘,读结果时也会采用先解压后读取数据。这样做的后果就是:写入磁盘的中间结果数据量会变少,但是cpu 会消耗一些用来压缩和解压。所以这种方式通常适合job 中间结果非常大,瓶颈不在cpu ,而是在磁盘的读写的情况。说的直白一些就是用cpu 换IO 。根据观察,通常大部分的作业cpu 都不是瓶颈,除非运算逻辑异常复杂。所以对中间结果采用压缩通常来说是有收益的。以下是一个wordcount 中间结果采用压缩和不采用压缩产生的map 中间结果本地磁盘读写的数据量对比:
map 中间结果不压缩:

map 中间结果压缩:

可以看出,同样的job ,同样的数据,在采用压缩的情况下,map 中间结果能缩小将近10 倍,如果map 的瓶颈在磁盘,那么job 的性能提升将会非常可观。
当采用map 中间结果压缩的情况下,用户还可以选择压缩时???用哪种压缩格式进行压缩,现在 Hadoop 支持的压缩格式有: GzipCodec , LzoCodec ,BZip2Codec , LzmaCodec 等压缩格式。通常来说,想要达到比较平衡的 cpu 和磁盘压缩比, LzoCodec 比较适合。但也要取决于 job 的具体情况。用户若想要自行选择中间结果的压缩算法,可以设置配置参数: mapred.map.output.compression.codec=org.apache.hadoop.io.compress.DefaultCodec 或者其他用户自行选择的压缩方式。
1.2 Map side 相关参数调优
选项 |
类型 |
默认值 |
描述 |
| io.sort.mb | int | 100 | 缓存 map中间结果的buffer 大小(in MB) |
| io.sort.record.percent | float | 0.05 | io.sort.mb中用来保存map output记录边界的百分比,其他缓存用来保存数据 |
| io.sort.spill.percent | float | 0.80 | map 开始做 spill 操作的阈值 |
| io.sort.factor | int | 10 | 做 merge操作时同时操作的stream 数上限。 |
| min.num.spill.for.combine | int | 3 | combiner函数运行的最小 spill 数 |
| mapred.compress.map.output | boolean | false | map 中间结果是否采用压缩 |
| mapred.map.output.compression.codec | class name | org.apache. Hadoop.io.
compress.DefaultCodec |
map 中间结果的压缩格式 |
2 Reduce side tuning 参数
2.1 ReduceTask 运行内部原理

reduce 的运行是分成三个阶段的。分别为 copy->sort->reduce 。由于 job 的每一个map 都会根据 reduce(n) 数将数据分成 map 输出结果分成 n 个 partition ,所以 map 的中间结果中是有可能包含每一个 reduce 需要处理的部分数据的。所以,为了优化reduce 的执行时间, hadoop 中是等 job 的第一个 map 结束后,所有的 reduce 就开始尝试从完成的 map 中下载该 reduce 对应的 partition 部分数据。这个过程就是通常所说的 shuffle ,也就是 copy 过程。
Reduce task 在做 shuffle 时,实际上就是从不同的已经完成的 map 上去下载属于自己这个 reduce 的部分数据,由于 map 通常有许多个,所以对一个 reduce 来说,下载也可以是并行的从多个 map 下载,这个并行度是可以调整的,调整参数为:mapred.reduce.parallel.copies ( default 5 )。默认情况下,每个只会有 5 个并行的下载线程在从 map 下数据,如果一个时间段内 job 完成的 map 有 100 个或者更多,那么 reduce 也最多只能同时下载 5 个 map 的数据,所以这个参数比较适合 map 很多并且完成的比较快的 job 的情况下调大,有利于 reduce 更快的获取属于自己部分的数据。
reduce 的每一个下载线程在下载某个 map 数据的时候,有可能因为那个 map 中间结果所在机器发生错误,或者中间结果的文件丢失,或者网络瞬断等等情况,这样reduce 的下载就有可能失败,所以 reduce 的下载线程并不会无休止的等待下去,当一定时间后下载仍然失败,那么下载线程就会放弃这次下载,并在随后尝试从另外的地方下载(因为这段时间 map 可能重跑)。所以 reduce 下载线程的这个最大的下载时间段是可以调整的,调整参数为: mapred.reduce.copy.backoff ( default 300秒)。如果集群环境的网络本身是瓶颈,那么用户可以通过调大这个参数来避免reduce 下载线程被误判为失败的情况。不过在网络环境比较好的情况下,没有必要调整。通常来说专业的集群网络不应该有太大问题,所以这个参数需要调整的情况不多。
Reduce 将 map 结果下载到本地时,同样也是需要进行 merge 的,所以io.sort.factor 的配置选项同样会影响 reduce 进行 merge 时的行为,该参数的详细介绍上文已经提到,当发现 reduce 在 shuffle 阶段 iowait 非常的高的时候,就有可能通过调大这个参数来加大一次 merge 时的并发吞吐,优化 reduce 效率。
Reduce 在 shuffle 阶段对下载来的 map 数据,并不是立刻就写入磁盘的,而是会先缓存在内存中,然后当使用内存达到一定量的时候才刷入磁盘。这个内存大小的控制就不像 map 一样可以通过 io.sort.mb 来设定了,而是通过另外一个参数来设置:mapred.job.shuffle.input.buffer.percent ( default 0.7 ),这个参数其实是一个百分比,意思是说, shuffile 在 reduce 内存中的数据最多使用内存量为: 0.7 × maxHeap of reduce task 。也就是说,如果该 reduce task 的最大 heap 使用量(通常通过mapred.child.java.opts 来设置,比如设置为 -Xmx1024m )的一定比例用来缓存数据。默认情况下, reduce 会使用其 heapsize 的 70% 来在内存中缓存数据。如果 reduce的 heap 由于业务原因调整的比较大,相应的缓存大小也会变大,这也是为什么reduce 用来做缓存的参数是一个百分比,而不是一个固定的值了。
假设 mapred.job.shuffle.input.buffer.percent 为 0.7 , reduce task 的 max heapsize 为1G ,那么用来做下载数据缓存的内存就为大概 700MB 左右,这 700M 的内存,跟map 端一样,也不是要等到全部写满才会往磁盘刷的,而是当这 700M 中被使用到了一定的限度(通常是一个百分比),就会开始往磁盘刷。这个限度阈值也是可以通过job 参数来设定的,设定参数为: mapred.job.shuffle.merge.percent ( default 0.66)。如果下载速度很快,很容易就把内存缓存撑大,那么调整一下这个参数有可能会对 reduce 的性能有所帮助。
当 reduce 将所有的 map 上对应自己 partition 的数据下载完成后,就会开始真正的reduce 计算阶段(中间有个 sort 阶段通常时间非常短,几秒钟就完成了,因为整个下载阶段就已经是边下载边 sort ,然后边 merge 的)。当 reduce task 真正进入 reduce函数的计算阶段的时候,有一个参数也是可以调整 reduce 的计算行为。也就是:mapred.job.reduce.input.buffer.percent ( default 0.0 )。由于 reduce 计算时肯定也是需要消耗内存的,而在读取 reduce 需要的数据时,同样是需要内存作为 buffer ,这个参数是控制,需要多少的内存百分比来作为 reduce 读已经 sort 好的数据的 buffer百分比。默认情况下为 0 ,也就是说,默认情况下, reduce 是全部从磁盘开始读处理数据。如果这个参数大于 0 ,那么就会有一定量的数据被缓存在内存并输送给 reduce,当 reduce 计算逻辑消耗内存很小时,可以分一部分内存用来缓存数据,反正 reduce的内存闲着也是闲着。
2.2 Reduce side 相关参数调优
选项 |
类型 |
默认值 |
描述 |
| mapred.reduce.parallel.copies | int | 5 | 每个 reduce 并行下载map 结果的最大线程数 |
| mapred.reduce.copy.backoff | int | 300 | reduce 下载线程最大等待时间( in sec ) |
| io.sort.factor | int | 10 | 同上 |
| mapred.job.shuffle.input.buffer.percent | float | 0.7 | 用来缓存 shuffle 数据的reduce task heap 百分比 |
| mapred.job.shuffle.merge.percent | float | 0.66 | 缓存的内存中多少百分比后开始做 merge 操作 |
| mapred.job.reduce.input.buffer.percent | float | 0.0 | sort 完成后 reduce 计算阶段用来缓存数据的百分比 |
本文出自:http://blog.chedushi.com, 原文地址:http://blog.chedushi.com/archives/9496, 感谢原作者分享。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7517
7517
 15
1378
52
79
11
53
19
21
66
15
1378
52
79
11
53
19
21
66

 노흡의 기능 및 원리 분석
Mar 25, 2024 pm 03:24 PM
노흡의 기능 및 원리 분석
Mar 25, 2024 pm 03:24 PM
nohup의 역할과 원리 분석 nohup은 유닉스 및 유닉스 계열 운영체제에서 사용자가 현재 세션을 종료하거나 터미널 창을 닫아도 백그라운드에서 명령을 실행하는 데 일반적으로 사용되는 명령입니다. 아직도 계속 처형되고 있다. 이번 글에서는 nohup 명령의 기능과 원리를 자세히 분석해보겠습니다. 1. nohup의 역할: 백그라운드에서 명령 실행: nohup 명령을 통해 사용자가 터미널 세션을 종료해도 영향을 받지 않고 장기 실행 명령이 백그라운드에서 계속 실행되도록 할 수 있습니다. 이건 실행해야 해
 C++ 함수 매개변수 유형 안전성 확인
Apr 19, 2024 pm 12:00 PM
C++ 함수 매개변수 유형 안전성 확인
Apr 19, 2024 pm 12:00 PM
C++ 매개변수 유형 안전성 검사는 함수가 컴파일 시간 검사, 런타임 검사 및 정적 어설션을 통해 예상된 유형의 값만 허용하도록 보장하여 예기치 않은 동작 및 프로그램 충돌을 방지합니다. 컴파일 시간 유형 검사: 컴파일러가 유형 호환성을 검사합니다. 런타임 유형 검사: 동적_캐스트를 사용하여 유형 호환성을 확인하고 일치하는 항목이 없으면 예외를 발생시킵니다. 정적 어설션: 컴파일 타임에 유형 조건을 어설션합니다.
 Linux chage 명령의 기능 및 작동 원리에 대한 심층 분석
Feb 24, 2024 pm 03:48 PM
Linux chage 명령의 기능 및 작동 원리에 대한 심층 분석
Feb 24, 2024 pm 03:48 PM
Linux 시스템의 chage 명령은 사용자 계정의 비밀번호 만료일을 수정하는 데 사용되는 명령이며, 계정의 사용 가능한 가장 긴 날짜와 가장 짧은 날짜를 수정하는 데에도 사용할 수 있습니다. 이 명령은 사용자 계정 보안 관리에 매우 중요한 역할을 하며 사용자 비밀번호의 사용 기간을 효과적으로 제어하고 시스템 보안을 강화할 수 있습니다. chage 명령 사용 방법: chage 명령의 기본 구문은 다음과 같습니다: chage [옵션] 사용자 이름 예를 들어, 사용자 "testuser"의 비밀번호 만료 날짜를 수정하려면 다음 명령을 사용할 수 있습니다.
 C++를 사용하여 HTTP 스트리밍을 구현하는 방법은 무엇입니까?
May 31, 2024 am 11:06 AM
C++를 사용하여 HTTP 스트리밍을 구현하는 방법은 무엇입니까?
May 31, 2024 am 11:06 AM
C++에서 HTTP 스트리밍을 구현하는 방법은 무엇입니까? Boost.Asio 및 asiohttps 클라이언트 라이브러리를 사용하여 SSL 스트림 소켓을 생성합니다. 서버에 연결하고 HTTP 요청을 보냅니다. HTTP 응답 헤더를 수신하고 인쇄합니다. HTTP 응답 본문을 수신하여 인쇄합니다.
 C++ 함수에서 참조 매개변수 및 포인터 매개변수의 고급 사용
Apr 21, 2024 am 09:39 AM
C++ 함수에서 참조 매개변수 및 포인터 매개변수의 고급 사용
Apr 21, 2024 am 09:39 AM
C++ 함수의 참조 매개변수(기본적으로 변수 별칭, 참조를 수정하면 원래 변수가 수정됨)와 포인터 매개변수(원래 변수의 메모리 주소 저장, 포인터 역참조를 통해 변수 수정)는 변수를 전달하고 수정할 때 사용법이 다릅니다. 참조 매개변수는 생성자나 할당 연산자에 전달될 때 복사 오버헤드를 피하기 위해 원래 변수(특히 대규모 구조)를 수정하는 데 자주 사용됩니다. 포인터 매개변수는 메모리 위치를 유연하게 가리키거나, 동적 데이터 구조를 구현하거나, 선택적 매개변수를 나타내기 위해 널 포인터를 전달하는 데 사용됩니다.
 LLM을 미세 조정하는 방법 혁신: PyTorch의 기본 라이브러리 토치튠의 혁신적인 기능과 애플리케이션 가치에 대한 포괄적인 해석
Apr 26, 2024 am 09:20 AM
LLM을 미세 조정하는 방법 혁신: PyTorch의 기본 라이브러리 토치튠의 혁신적인 기능과 애플리케이션 가치에 대한 포괄적인 해석
Apr 26, 2024 am 09:20 AM
인공 지능 분야에서 LLM(대형 언어 모델)은 연구 및 응용 분야에서 점점 더 새로운 핫스팟이 되고 있습니다. 그러나 이러한 거대 기업을 효율적이고 정확하게 조정하는 방법은 업계와 학계가 항상 직면한 중요한 과제였습니다. 최근 PyTorch 공식 블로그에는 TorchTune에 대한 기사가 게재되어 큰 관심을 끌었습니다. LLM 튜닝 및 설계에 초점을 맞춘 도구인 TorchTune은 과학적 특성과 실용성으로 높은 평가를 받고 있습니다. 이 기사에서는 독자들에게 포괄적이고 심층적인 이해를 제공하기 위해 LLM 튜닝에서 TorchTune의 기능, 특징 및 적용을 자세히 소개합니다. 1. TorchTune의 탄생 배경과 의의, 딥러닝 기술과 딥러닝 모델(LLM)의 발전
 Astar 스테이킹 원칙, 수입 해체, 에어드랍 프로젝트 및 전략 및 운영 보모 수준 전략
Jun 25, 2024 pm 07:09 PM
Astar 스테이킹 원칙, 수입 해체, 에어드랍 프로젝트 및 전략 및 운영 보모 수준 전략
Jun 25, 2024 pm 07:09 PM
목차 Astar Dapp 스테이킹 원리 스테이킹 수익 잠재적 에어드랍 프로젝트 해체: AlgemNeurolancheHealThreeAstar Degens DAOVeryLongSwap 스테이킹 전략 및 운영 "AstarDapp 스테이킹"이 올해 초 V3 버전으로 업그레이드되었으며 스테이킹 수익에 많은 조정이 이루어졌습니다. 규칙. 현재 첫 번째 스테이킹 주기는 종료되었으며 두 번째 스테이킹 주기의 "투표" 하위 주기가 막 시작되었습니다. '추가 보상' 혜택을 받으려면 이 중요한 단계(6월 26일까지 지속 예정, 5일 미만 남았음)를 파악해야 합니다. 아스타 스테이킹 수익을 자세하게 분석해보겠습니다.
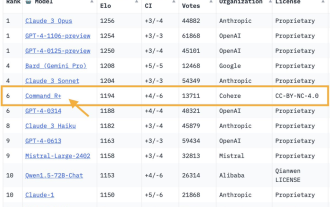 오픈 소스 모델이 처음으로 GPT-4를 획득했습니다! Arena의 최신 전투 보고서는 열띤 논쟁을 불러일으켰습니다. Karpathy: 이것이 제가 신뢰하는 유일한 목록입니다.
Apr 10, 2024 pm 03:16 PM
오픈 소스 모델이 처음으로 GPT-4를 획득했습니다! Arena의 최신 전투 보고서는 열띤 논쟁을 불러일으켰습니다. Karpathy: 이것이 제가 신뢰하는 유일한 목록입니다.
Apr 10, 2024 pm 03:16 PM
GPT-4를 이길 수 있는 오픈소스 모델이 등장했습니다! 대형 모델 경기장의 최신 전투 보고서: 1040억 매개변수 오픈 소스 모델 CommandR+가 GPT-4-0314와 동점을 이루고 GPT-4-0613을 능가하여 6위로 올랐습니다. Image 이것은 또한 대형 모델 분야에서 GPT-4를 능가한 최초의 개방형 모델이기도 합니다. 대형 모델 경기장은 마스터 Karpathy가 신뢰하는 유일한 테스트 벤치마크 중 하나입니다. AI 유니콘 Cohere의 이미지 CommandR+. 이 대형 모델 스타트업의 공동 창업자이자 CEO는 바로 트랜스포머(일명 밀 수확자)의 최연소 작가인 에이든 고메즈다. 이 배틀 리포트가 나오자마자 또 다른 빅 모델 클럽들의 물결이 시작됐다.
