

Kafka原理和集群测试

Kafka是一个消息系统,由LinkedIn贡献给Apache基金会,称为Apache的一个顶级项目。Kafka最初用作LinkedIn的活动流(activity stream)和运营数据处理管道(pipeline)的基
Kafka是一个消息系统,由LinkedIn贡献给Apache基金会,称为Apache的一个顶级项目。Kafka最初用作LinkedIn的活动流(activity stream)和运营数据处理管道(pipeline)的基础。它具有可扩展、吞吐量大和可持久化等特征,以及非常好的分区、复制和容错特征。
Kafka的关键设计决策
1). Kafka在设计之时为就将持久化消息作为通常的使用情况进行了考虑。
2). Kafka主要的设计约束是吞吐量,而不是功能。
3). Kafka有关哪些数据已经被使用了的状态信息保存为数据使用者(consumer)的一部分,而不是保存在服务器之上。
4). Kafka是一种显式的分布式系统。它假设,数据生产者(producer)、代理(brokers)和数据使用者(consumer)分散于多台机器之上。
而相比而言,传统的消息队列不能很好的支持(如超长的未处理数据、不能有效持久化)。对于数据的可用性,Kafka提供了两个保证:
(1). 生产者发送到Topic的分区上消息将会按照它们发送的顺序,而消费者收到的消息也是此顺序
(2). 如果一个Topic配置了复制因子( replication facto)为N, 那么可以允许N-1服务器当掉而不丢失任何已经增加的消息
Kafka中几个关键术语
Topic:Kafka将消息种子(Feed)分门别类, 每一类的消息称之为话题(Topic).
Producer:发布消息的对象称之为话题生产者(Kafka topic producer)
Consumer:订阅消息并处理发布的消息的种子的对象称之为话题消费者(consumers)
Broker:已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
Kafka中的Topic

Topic是发布的消息的类别或者种子Feed名。对于每一个Topic, Kafka集群维护这一个分区的log,就像下图中的示例:Kafka集群
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分配了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
Kafka集群保持所有的消息,直到它们过期,无论消息是否被消费了。
实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。 这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。
可以看到这种设计对消费者来说操作自如, 一个消费者的操作不会影响其它消费者对此log的处理。
再说说分区。Kafka中采用分区的设计有几个目的。
一、可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以进行扩展,并处理更多的数据。
二、分区可以作为并行处理的单元。
Topic的分区Log被分布到集群中的多个服务器上。每个服务器处理它持有的分区。 根据配置每个分区还可以复制到其它服务器作为备份容错。
每个分区有一个leader,零或多个replica。Leader处理此分区的所有的读写请求而replica被动的复制数据。如果leader当机,其它的一个replica会被推举为新的leader。
一台服务器可能同时是一个分区的leader,另一个分区的replica。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
关于复制原理,参考下面官档翻译:
Kafka 的集群复制设计
Kafka的集群部署
Kafka中主要有三种模式,
单机broker模式
单机多broker模式(伪分布式)
多机多broker模式(集群)
和hadoop一样,前两种多用于开发测试。第三种才是实际生产中可用的部署模式,下面介绍一下三节点kafka集群的部署流程
软件的安装直接解压缩即可:
tar xzvf kafka_2.10-0.8.1.1.tgz mkdir /var/kafka && mkdir /var/zookeeper
关键参数的解释,可以参考http://debugo.com/kafka-params/
vim kafka_2.10-0.8.1.1/config/server.properties
#在默认的配置上,我只修改了3个地方。三个主机debugo01,debugo02,debugo03分别对应id为1,2,3 broker.id=3 log.dirs=/var/kafka zookeeper.connect=debugo01:2181,debugo02:2181,debugo03:2181 配置zookeeper,修改DataDir并加入集群参数 vim kafka_2.10-0.8.1.1/config/zookeeper.properties initLimit=5 syncLimit=2 server.1=debugo01:2888:3888 server.2=debugo02:2888:3888 server.3=debugo03:2888:3888 dataDir=/var/zookeeper #分别将1,2,3写入三个主机的myid文件 echo "1" >> /var/zookeeper/myid
在debugo01,debugo02,debugo03上分别启动zookeeper和kafka Server
bin/zookeeper-server-start.sh config/zookeeper.properties # 启动kafka Server bin/kafka-server-start.sh config/server.properties
这时可以在log中找到,新的broker已经将数据注册到znode中。
#####debugo01#####
[2014-12-07 20:54:20,506] INFO Awaiting socket connections on debugo01:9092. (kafka.network.Acceptor)
[2014-12-07 20:54:20,521] INFO [Socket Server on Broker 1], Started (kafka.network.SocketServer)
[2014-12-07 20:54:20,649] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-12-07 20:54:20,725] INFO 1 successfully elected as leader (kafka.server.ZookeeperLeaderElector)
[2014-12-07 20:54:20,876] INFO Registered broker 1 at path /brokers/ids/1 with address debugo01:9092. (kafka.utils.ZkUtils$)
[2014-12-07 20:54:20,907] INFO [Kafka Server 1], started (kafka.server.KafkaServer)
[2014-12-07 20:54:20,993] INFO New leader is 1 (kafka.server.ZookeeperLeaderElector$LeaderChangeListener)
#####debugo02#####
[2014-12-07 20:54:35,896] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2014-12-07 20:54:35,913] INFO [Socket Server on Broker 2], Started (kafka.network.SocketServer)
[2014-12-07 20:54:36,073] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-12-07 20:54:36,179] INFO conflict in /controller data: {"version":1,"brokerid":2,"timestamp":"1417956876081"} stored data: {"version":1,"brokerid":1,"timestamp":"1417956860689"} (kafka.utils.ZkUtils$)
[2014-12-07 20:54:36,398] INFO Registered broker 2 at path /brokers/ids/2 with address debugo02:9092. (kafka.utils.ZkUtils$)
[2014-12-07 20:54:36,420] INFO [Kafka Server 2], started (kafka.server.KafkaServer)
#####debugo03#####
[2014-12-07 20:54:43,535] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2014-12-07 20:54:43,549] INFO [Socket Server on Broker 3], Started (kafka.network.SocketServer)
[2014-12-07 20:54:43,728] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-12-07 20:54:43,783] INFO conflict in /controller data: {"version":1,"brokerid":3,"timestamp":"1417956883737"} stored data: {"version":1,"brokerid":1,"timestamp":"1417956860689"} (kafka.utils.ZkUtils$)
[2014-12-07 20:54:43,999] INFO Registered broker 3 at path /brokers/ids/3 with address debugo03:9092. (kafka.utils.ZkUtils$)
[2014-12-07 20:54:44,018] INFO [Kafka Server 3], started (kafka.server.KafkaServer)Topic的分区和复制
1. 创建debugo01,这个topic分区数为3,复制为1(不复制)。该topic跨越全部broker。下面管理命令在任意kafka节点上执行即可
bin/kafka-topics.sh --create --zookeeper debugo01,debugo02,debugo03 --replication-factor 1 --partitions 3 --topic debugo01 Created topic "debugo01".
2. 创建debugo02,这个topic分区数为1,复制为3(每个主机都有一份)。该topic跨越全部broker。下面管理命令在任意kafka节点上执行即可
bin/kafka-topics.sh --create --zookeeper debugo01,debugo02,debugo03 --replication-factor 3 --partitions 1 --topic debugo02
3. 列出topic信息
[root@debugo01 kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --list --zookeeper localhost:2181 debugo01 debugo02
4. 列出topic描述信息
[root@debugo01 kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic debugo01 Topic:debugo01 PartitionCount:3 ReplicationFactor:1 Configs: Topic: debugo01 Partition: 0 Leader: 1 Replicas: 1 Isr: 1 Topic: debugo01 Partition: 1 Leader: 2 Replicas: 2 Isr: 2 Topic: debugo01 Partition: 2 Leader: 3 Replicas: 3 Isr: 3
5. 检查log目录,对于topic debugo01,debugo01为0号分区,debugo02为1号分区。而topic debugo02则复制了3份,都为0号分区
[root@debugo01 kafka]# ll total 24 drwxr-xr-x 2 root root 4096 Dec 7 21:15 debugo01-0 drwxr-xr-x 2 root root 4096 Dec 7 21:16 debugo02-0 [root@debugo02 kafka]# ll total 24 drwxr-xr-x 2 root root 4096 Dec 7 21:15 debugo01-1 drwxr-xr-x 2 root root 4096 Dec 7 21:16 debugo02-0 #而每个分区下面都生成了index和log文件 [root@debugo01 debugo01-0]# ls 00000000000000000000.index 00000000000000000000.log
6. 下面topic debugo03,replication-factor为2,partition为3.那么broker id为1的debugo01会如下面describe所示,保存0号分区和1号分区。
而0号分区的repica leader为broker id = 3,包含3和1两个replicas。
bin/kafka-topics.sh --create --zookeeper debugo01,debugo02,debugo03 --replication-factor 2 --partitions 3 --topic debugo03 Created topic "debugo03". bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic debugo03 [root@debugo01 kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic debugo03 Topic:debugo03 PartitionCount:3 ReplicationFactor:2 Configs: Topic: debugo03 Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1 Topic: debugo03 Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2 Topic: debugo03 Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3 [root@debugo01 kafka_2.10-0.8.1.1]# ll /var/kafka/debugo03* /var/kafka/debugo03-0: total 0 -rw-r--r-- 1 root root 10485760 Dec 7 21:34 00000000000000000000.index -rw-r--r-- 1 root root 0 Dec 7 21:34 00000000000000000000.log /var/kafka/debugo03-1: total 0 -rw-r--r-- 1 root root 10485760 Dec 7 21:34 00000000000000000000.index -rw-r--r-- 1 root root 0 Dec 7 21:34 00000000000000000000.log
消息的产生和消费
两个终端分别打开producer和consumer进行测试
<terminal> bin/kafka-console-producer.sh --broker-list debugo01:9092 --topic debugo03 hello kafka hello debugo <terminal> bin/kafka-console-consumer.sh --zookeeper debugo01:2181 --from-beginning --topic debugo03 hello kafka hello debugo</terminal></terminal>
下面使用perf命令来测试几个topic的性能,需要先下载kafka-perf_2.10-0.8.1.1.jar,并拷贝到kafka/libs下面。
50W条消息,每条1000字节,batch大小1000,topic为debugo01,4个线程(message size设置太大需要调整相关参数,否则容易OOM)。只用了13秒完成,kafka在多分区支持下吞吐量是非常给力的。
bin/kafka-producer-perf-test.sh --messages 500000 --message-size 1000 --batch-size 1000 --topics debugo01 --threads 4 --broker-list debugo01:9092,debugo02:9092,debugo03:9092 start.time, end.time, compression, message.size, batch.size, total.data.sent.in.MB, MB.sec, total.data.sent.in.nMsg, nMsg.sec 2014-12-07 22:07:56:038, 2014-12-07 22:08:09:413, 0, 1000, 1000, 476.84, 35.6514, 500000, 37383.1776
同样的参数测试debugo02, 由于但分区加复制(replicas-factor=3),用时39秒。所以,适当加大partition数量和broker相关线程数量会极大的提高性能。
bin/kafka-producer-perf-test.sh --messages 500000 --message-size 1000 --batch-size 1000 --topics debugo02 --threads 4 --broker-list debugo01:9092,debugo02:9092,debugo03:9092 start.time, end.time, compression, message.size, batch.size, total.data.sent.in.MB, MB.sec, total.data.sent.in.nMsg, nMsg.sec 2014-12-07 22:13:28:840, 2014-12-07 22:14:07:819, 0, 1000, 1000, 476.84, 12.2332, 500000, 12827.4199
同样的参数测试debugo03,用时30秒。
bin/kafka-producer-perf-test.sh --messages 500000 --message-size 1000 --batch-size 1000 --topics debugo03 --threads 4 --broker-list debugo01:9092,debugo02:9092,debugo03:9092 start.time, end.time, compression, message.size, batch.size, total.data.sent.in.MB, MB.sec, total.data.sent.in.nMsg, nMsg.sec 2014-12-07 22:16:04:895, 2014-12-07 22:16:34:715, 0, 1000, 1000, 476.84, 15.9905, 500000, 16767.2703
同理,测试comsumer的性能。
bin/kafka-consumer-perf-test.sh --zookeeper debugo01,debugo02,debugo03 --messages 500000 --topic debugo01 --threads 3 start.time, end.time, fetch.size, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec 2014-12-07 22:19:04:527, 2014-12-07 22:19:17:184, 1048576, 476.8372, 62.2747, 500000, 65299.7257 bin/kafka-consumer-perf-test.sh --zookeeper debugo01,debugo02,debugo03 --messages 500000 --topic debugo02 --threads 3 start.time, end.time, fetch.size, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec [2014-12-07 22:19:59,938] WARN [perf-consumer-78853_debugo01-1417961999315-4a5941ef], No broker partitions consumed by consumer thread perf-consumer-78853_debugo01-1417961999315-4a5941ef-1 for topic debugo02 (kafka.consumer.ZookeeperConsumerConnector) [2014-12-07 22:19:59,938] WARN [perf-consumer-78853_debugo01-1417961999315-4a5941ef], No broker partitions consumed by consumer thread perf-consumer-78853_debugo01-1417961999315-4a5941ef-2 for topic debugo02 (kafka.consumer.ZookeeperConsumerConnector) 2014-12-07 22:20:01:008, 2014-12-07 22:20:08:971, 1048576, 476.8372, 160.9305, 500000, 168747.8907 bin/kafka-consumer-perf-test.sh --zookeeper debugo01,debugo02,debugo03 --messages 500000 --topic debugo03 --threads 3 start.time, end.time, fetch.size, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec ?2014-12-07 22:21:27:421, 2014-12-07 22:21:39:918, 1048576, 476.8372, 63.6037, 500002, 66693.6108
^^
参考
http://blog.csdn.net/smallnest/article/details/38491483
http://www.350351.com/jiagoucunchu/xiaoxixitong/46720.html
http://kafka.apache.org/documentation.html
http://backend.blog.163.com/blog/static/202294126201431723734212/
http://www.inter12.org/archives/842
原文地址:Kafka原理和集群测试, 感谢原作者分享。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7476
7476
 15
1377
52
77
11
49
19
19
31
15
1377
52
77
11
49
19
19
31

 CUDA의 보편적인 행렬 곱셈: 입문부터 숙련까지!
Mar 25, 2024 pm 12:30 PM
CUDA의 보편적인 행렬 곱셈: 입문부터 숙련까지!
Mar 25, 2024 pm 12:30 PM
GEMM(일반 행렬 곱셈)은 많은 응용 프로그램과 알고리즘의 중요한 부분이며 컴퓨터 하드웨어 성능을 평가하는 중요한 지표 중 하나이기도 합니다. GEMM 구현에 대한 심층적인 연구와 최적화는 고성능 컴퓨팅과 소프트웨어와 하드웨어 시스템 간의 관계를 더 잘 이해하는 데 도움이 될 수 있습니다. 컴퓨터 과학에서 GEMM의 효과적인 최적화는 컴퓨팅 속도를 높이고 리소스를 절약할 수 있으며, 이는 컴퓨터 시스템의 전반적인 성능을 향상시키는 데 중요합니다. GEMM의 작동 원리와 최적화 방법에 대한 심층적인 이해는 현대 컴퓨팅 하드웨어의 잠재력을 더 잘 활용하고 다양하고 복잡한 컴퓨팅 작업에 대한 보다 효율적인 솔루션을 제공하는 데 도움이 될 것입니다. GEMM의 성능을 최적화하여
 화웨이의 Qiankun ADS3.0 지능형 운전 시스템은 8월에 출시될 예정이며 처음으로 Xiangjie S9에 출시될 예정입니다.
Jul 30, 2024 pm 02:17 PM
화웨이의 Qiankun ADS3.0 지능형 운전 시스템은 8월에 출시될 예정이며 처음으로 Xiangjie S9에 출시될 예정입니다.
Jul 30, 2024 pm 02:17 PM
7월 29일, AITO Wenjie의 400,000번째 신차 출시 행사에 Huawei 전무이사이자 Terminal BG 회장이자 Smart Car Solutions BU 회장인 Yu Chengdong이 참석하여 연설을 했으며 Wenjie 시리즈 모델이 출시될 것이라고 발표했습니다. 올해 출시 예정 지난 8월 Huawei Qiankun ADS 3.0 버전이 출시되었으며, 8월부터 9월까지 순차적으로 업그레이드를 추진할 계획입니다. 8월 6일 출시되는 Xiangjie S9에는 화웨이의 ADS3.0 지능형 운전 시스템이 최초로 탑재됩니다. LiDAR의 도움으로 Huawei Qiankun ADS3.0 버전은 지능형 주행 기능을 크게 향상시키고, 엔드투엔드 통합 기능을 갖추고, GOD(일반 장애물 식별)/PDP(예측)의 새로운 엔드투엔드 아키텍처를 채택합니다. 의사결정 및 제어), 주차공간부터 주차공간까지 스마트 드라이빙의 NCA 기능 제공, CAS3.0 업그레이드
 메시지를 보냈지만 상대방이 거부했다는 것은 무엇을 의미하나요?
Mar 07, 2024 pm 03:59 PM
메시지를 보냈지만 상대방이 거부했다는 것은 무엇을 의미하나요?
Mar 07, 2024 pm 03:59 PM
메시지가 전송되었지만 상대방이 거부했습니다. 이는 보낸 정보가 장치에서 성공적으로 전송되었지만 어떤 이유로 상대방이 메시지를 받지 못했음을 의미합니다. 보다 구체적으로 말하면, 이는 일반적으로 상대방이 특정 권한을 설정하거나 특정 조치를 취함으로써 귀하의 정보가 정상적으로 수신되지 않는 경우가 많습니다.
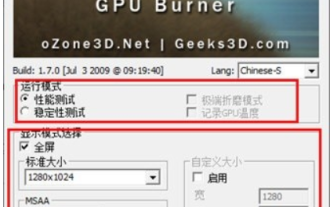 Furmark에 대해 어떻게 생각하시나요? - Furmark는 어떻게 자격을 갖춘 것으로 간주됩니까?
Mar 19, 2024 am 09:25 AM
Furmark에 대해 어떻게 생각하시나요? - Furmark는 어떻게 자격을 갖춘 것으로 간주됩니까?
Mar 19, 2024 am 09:25 AM
Furmark에 대해 어떻게 생각하시나요? 1. 메인 인터페이스에서 "실행 모드"와 "디스플레이 모드"를 설정하고 "테스트 모드"도 조정한 후 "시작" 버튼을 클릭하세요. 2. 잠시 기다리면 그래픽 카드의 다양한 매개변수를 포함한 테스트 결과가 표시됩니다. Furmark는 어떻게 자격을 갖추었나요? 1. 푸르마크 베이킹 머신을 사용하여 약 30분 동안 결과를 확인합니다. 기본적으로 85도 정도, 최고 온도는 87도, 실내 온도는 19도입니다. 대형 섀시에 섀시 팬 포트 5개 전면 2개, 상단 2개, 후면 1개로 구성됐으나 팬은 1개만 설치됐다. 모든 액세서리는 오버클럭되지 않습니다. 2. 정상적인 상황에서 그래픽 카드의 정상 온도는 "30-85℃" 사이여야 합니다. 3. 주변온도가 너무 높은 여름에도 정상온도는 "50~85℃"
 노흡의 기능 및 원리 분석
Mar 25, 2024 pm 03:24 PM
노흡의 기능 및 원리 분석
Mar 25, 2024 pm 03:24 PM
nohup의 역할과 원리 분석 nohup은 유닉스 및 유닉스 계열 운영체제에서 사용자가 현재 세션을 종료하거나 터미널 창을 닫아도 백그라운드에서 명령을 실행하는 데 일반적으로 사용되는 명령입니다. 아직도 계속 처형되고 있다. 이번 글에서는 nohup 명령의 기능과 원리를 자세히 분석해보겠습니다. 1. nohup의 역할: 백그라운드에서 명령 실행: nohup 명령을 통해 사용자가 터미널 세션을 종료해도 영향을 받지 않고 장기 실행 명령이 백그라운드에서 계속 실행되도록 할 수 있습니다. 이건 실행해야 해
 Apple 16 시스템의 어떤 버전이 가장 좋나요?
Mar 08, 2024 pm 05:16 PM
Apple 16 시스템의 어떤 버전이 가장 좋나요?
Mar 08, 2024 pm 05:16 PM
Apple 16 시스템의 최고 버전은 iOS16.1.4입니다. iOS16 시스템의 최고 버전은 사람마다 다를 수 있으며 일상적인 사용 경험의 추가 및 개선도 많은 사용자로부터 호평을 받았습니다. Apple 16 시스템의 가장 좋은 버전은 무엇입니까? 답변: iOS16.1.4 iOS 16 시스템의 가장 좋은 버전은 사람마다 다를 수 있습니다. 공개 정보에 따르면 2022년에 출시된 iOS16은 매우 안정적이고 성능이 뛰어난 버전으로 평가되며, 사용자들은 전반적인 경험에 상당히 만족하고 있습니다. 또한, iOS16에서는 새로운 기능 추가와 일상 사용 경험 개선도 많은 사용자들에게 호평을 받고 있습니다. 특히 업데이트된 배터리 수명, 신호 성능 및 발열 제어 측면에서 사용자 피드백은 비교적 긍정적이었습니다. 그러나 iPhone14를 고려하면
 항상 새로운! Huawei Mate60 시리즈가 HarmonyOS 4.2로 업그레이드: AI 클라우드 향상, Xiaoyi Dialect는 사용하기 매우 쉽습니다.
Jun 02, 2024 pm 02:58 PM
항상 새로운! Huawei Mate60 시리즈가 HarmonyOS 4.2로 업그레이드: AI 클라우드 향상, Xiaoyi Dialect는 사용하기 매우 쉽습니다.
Jun 02, 2024 pm 02:58 PM
4월 11일, 화웨이는 처음으로 HarmonyOS 4.2 100개 시스템 업그레이드 계획을 공식 발표했습니다. 이번에는 휴대폰, 태블릿, 시계, 헤드폰, 스마트 스크린 및 기타 장치를 포함하여 180개 이상의 장치가 업그레이드에 참여할 것입니다. 지난달 HarmonyOS4.2 100대 업그레이드 계획이 꾸준히 진행됨에 따라 Huawei Pocket2, Huawei MateX5 시리즈, nova12 시리즈, Huawei Pura 시리즈 등을 포함한 많은 인기 모델도 업그레이드 및 적응을 시작했습니다. 더 많은 Huawei 모델 사용자가 HarmonyOS가 제공하는 일반적이고 종종 새로운 경험을 즐길 수 있을 것입니다. 사용자 피드백에 따르면 HarmonyOS4.2를 업그레이드한 후 Huawei Mate60 시리즈 모델의 경험이 모든 측면에서 개선되었습니다. 특히 화웨이 M
 새로운 Xianxia 모험에 참여하세요! 'Zhu Xian 2' 'Wuwei Test' 사전 다운로드가 가능합니다
Apr 22, 2024 pm 12:50 PM
새로운 Xianxia 모험에 참여하세요! 'Zhu Xian 2' 'Wuwei Test' 사전 다운로드가 가능합니다
Apr 22, 2024 pm 12:50 PM
새로운 판타지 요정 MMORPG '주선2'의 '무작용 테스트'가 4월 23일 출시된다. 원작으로부터 수천 년이 지난 주선 대륙에서는 어떤 새로운 요정 모험 이야기가 펼쳐질 것인가? 육계선불세계, 불멸수련을 위한 전임 학원, 불멸수련의 자유로운 삶, 불멸세계의 온갖 즐거움이 불멸친구들이 직접 탐험하는 것을 기다리고 있습니다! 이제 'Wuwei 테스트' 사전 다운로드가 공개되었습니다. 요정 친구들은 공식 웹사이트에 접속하여 다운로드할 수 있습니다. 서버가 출시되기 전에는 게임 서버에 로그인할 수 없습니다. 사전 다운로드 및 설치 후에는 활성화 코드를 사용할 수 있습니다. 완성 됐습니다. "Zhu Xian 2" "Inaction Test" 개장 시간: 4월 23일 10:00 - 5월 6일 23:59 Zhu Xian의 정통 속편 "Zhu Xian 2"의 새로운 요정 모험 장은 "Zhu Xian" 소설을 기반으로 합니다. 원작의 세계관을 바탕으로 게임 배경이 설정되었습니다.
