

常用的两种数据分区方法(以Teradata为例)

海量数据性能优化的一个基本的原则就是“分区”(也有叫“分片”的)。分区思想其实就是日常工作生活中的抽屉原理:我们把自己的物品按照某种逻辑归置到多个小抽
海量数据性能优化的一个基本的原则就是“分区”(也有叫“分片”的)。分区思想其实就是日常工作生活中的抽屉原理:我们把自己的物品按照某种逻辑归置到多个小抽屉中,一般会比混在一个大抽屉中好找;但是小抽屉太多了、或者逻辑混乱了,也可能效果适得其反。
Teradata的分区语法较为简洁,其中常用的是按时间分区,如下例只要添加到create table语句末尾就可以实现2013年全年一天一个分区了
更进一步,香港空间,其中如下面的语法元素:
my_field='A'
可以修改为类似于这样的形式:
SUBSTR(my_field,1,1) IN ('E','F','G')
在现实中,美国空间,因为访问数据从全表扫描变成了分区扫描的原因,香港服务器,某些步骤可以达成10-100倍的性能提升。对于复杂的耗时较长的大作业,也总是能够缩短一半以上的运行时间。非常有意思的现象是,即使是经验丰富的开发人员,对数据分区的掌握也不一定很好。数据分区理念是超越具体数据库的,无论是Teradata还是别的什么数据库,在我过去将近十年的职业生涯中,大多数性能问题都可以通过数据分区得以妥善解决。
本文出自 “iData” 博客,请务必保留此出处

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7325
7325
 9
1625
14
1350
46
1262
25
1209
29
9
1625
14
1350
46
1262
25
1209
29

 win11 시스템에서 예약된 파티션을 업데이트할 수 없는 문제 해결
Dec 26, 2023 pm 12:41 PM
win11 시스템에서 예약된 파티션을 업데이트할 수 없는 문제 해결
Dec 26, 2023 pm 12:41 PM
win11을 업데이트한 후 일부 사용자는 시스템에서 예약한 파티션을 업데이트할 수 없어 더 많은 새 소프트웨어를 다운로드할 수 없는 문제에 직면했습니다. 그래서 오늘은 시스템에서 예약한 파티션을 win11에서 업데이트할 수 없는 문제에 대한 솔루션을 가져왔습니다. 와서 함께 다운로드해 보세요. win11이 시스템에 예약된 파티션을 업데이트할 수 없는 경우 수행할 작업: 1. 먼저 아래 시작 메뉴 버튼을 마우스 오른쪽 버튼으로 클릭합니다. 2. 그런 다음 메뉴를 마우스 오른쪽 버튼으로 클릭하고 실행을 클릭합니다. 3. 작업 중에 diskmgmt.msc를 입력하고 Enter를 누릅니다. 4. 그런 다음 시스템 디스크에 들어가서 EFI 시스템 파티션을 확인하여 공간이 300M 미만인지 확인할 수 있습니다. 5. 너무 작은 경우 도구를 다운로드하여 시스템 예약 파티션을 300MB 이상으로 변경하는 것이 좋습니다.
![[Linux 시스템] fdisk 관련 파티션 명령.](https://img.php.cn/upload/article/000/887/227/170833682614236.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) [Linux 시스템] fdisk 관련 파티션 명령.
Feb 19, 2024 pm 06:00 PM
[Linux 시스템] fdisk 관련 파티션 명령.
Feb 19, 2024 pm 06:00 PM
fdisk는 디스크 파티션을 생성, 관리 및 수정하는 데 일반적으로 사용되는 Linux 명령줄 도구입니다. 다음은 일반적으로 사용되는 fdisk 명령입니다. 디스크 파티션 정보 표시: fdisk-l 이 명령은 시스템에 있는 모든 디스크의 파티션 정보를 표시합니다. 작동하려는 디스크를 선택하십시오: fdisk/dev/sdX /dev/sdX를 작동하려는 실제 디스크 장치 이름(예: /dev/sda)으로 바꾸십시오. 새 파티션 만들기:n 새 파티션을 만드는 방법을 안내합니다. 프롬프트에 따라 파티션 유형, 시작 섹터, 크기 및 기타 정보를 입력하십시오. 파티션 삭제:d 삭제하려는 파티션을 선택하도록 안내합니다. 프롬프트에 따라 삭제할 파티션 번호를 선택하십시오. 파티션 유형 수정: 유형을 수정하려는 파티션을 선택하도록 안내합니다. 언급에 따르면
 win10 설치 후 파티션이 안되는 문제 해결 방법
Jan 02, 2024 am 09:17 AM
win10 설치 후 파티션이 안되는 문제 해결 방법
Jan 02, 2024 am 09:17 AM
win10 운영 체제를 다시 설치했을 때 디스크 파티셔닝 단계에서 시스템에서 새 파티션을 생성할 수 없으며 기존 파티션을 찾을 수 없다는 메시지를 표시하는 것을 발견했습니다. 이런 경우에는 하드디스크 전체를 다시 포맷하고 시스템을 파티션에 다시 설치하거나, 소프트웨어 등을 통해 시스템을 다시 설치해 보시는 것도 좋을 것 같습니다. 특정 콘텐츠에 대해 편집자가 어떻게 작업했는지 살펴보겠습니다~ 도움이 되었으면 좋겠습니다. win10을 설치한 후 새 파티션을 만들 수 없는 경우 방법 1: 전체 하드 디스크를 포맷하고 다시 파티션을 나누거나 USB 플래시 드라이브를 여러 번 연결 및 분리한 후 새로 고쳐 보십시오. , 파티션 나누기 단계에서는 하드 디스크의 모든 데이터를 삭제합니다. 파티션이 삭제되었습니다. 전체 하드 드라이브를 다시 포맷한 후 다시 파티션을 나눈 후 정상적으로 설치하세요. 방법 2: P
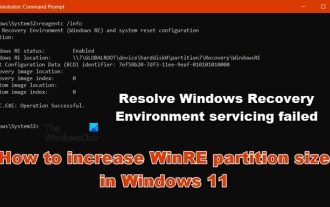 Windows 11에서 WinRE 파티션 크기를 늘리는 방법
Feb 19, 2024 pm 06:06 PM
Windows 11에서 WinRE 파티션 크기를 늘리는 방법
Feb 19, 2024 pm 06:06 PM
이 기사에서는 Windows 11/10에서 WinRE 파티션 크기를 변경하거나 늘리는 방법을 보여줍니다. Microsoft는 이제 Windows 11 버전 22H2부터 월별 누적 업데이트와 함께 Windows 복구 환경(WinRE)을 업데이트할 예정입니다. 그러나 모든 컴퓨터에 새 업데이트를 수용할 만큼 큰 복구 파티션이 있는 것은 아니며 이로 인해 오류 메시지가 나타날 수 있습니다. Windows 복구 환경 서비스가 실패했습니다. Windows 11에서 WinRE 파티션 크기를 늘리는 방법 컴퓨터에서 WinRE 파티션 크기를 수동으로 늘리려면 아래에 설명된 단계를 따르세요. WinRE 확인 및 비활성화 OS 파티션 축소 새 복구 파티션 생성 파티션 확인 및 WinRE 활성화
 Linux Opt 파티션 설정 방법에 대한 자세한 설명
Mar 20, 2024 am 11:30 AM
Linux Opt 파티션 설정 방법에 대한 자세한 설명
Mar 20, 2024 am 11:30 AM
Linux Opt 파티션 및 코드 예제를 설정하는 방법 Linux 시스템에서 Opt 파티션은 일반적으로 선택적 소프트웨어 패키지 및 응용 프로그램 데이터를 저장하는 데 사용됩니다. Opt 파티션을 올바르게 설정하면 시스템 리소스를 효과적으로 관리하고 디스크 공간 부족과 같은 문제를 피할 수 있습니다. 이 기사에서는 LinuxOpt 파티션을 설정하는 방법을 자세히 설명하고 특정 코드 예제를 제공합니다. 1. 파티션 공간 크기 결정 먼저 Opt 파티션에 필요한 공간 크기를 결정해야 합니다. 일반적으로 Opt 파티션의 크기를 전체 시스템 공간의 5%-1로 설정하는 것이 좋습니다.
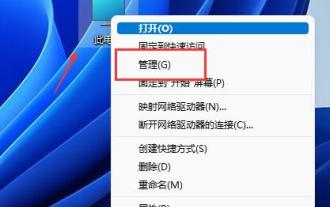 Win11에서 하드 디스크를 분할하는 방법은 무엇입니까? win11 디스크에서 하드 디스크를 파티션하는 방법에 대한 튜토리얼
Feb 19, 2024 pm 06:01 PM
Win11에서 하드 디스크를 분할하는 방법은 무엇입니까? win11 디스크에서 하드 디스크를 파티션하는 방법에 대한 튜토리얼
Feb 19, 2024 pm 06:01 PM
많은 사용자가 시스템의 기본 파티션 공간이 너무 작다고 생각하는데, Win11에서 하드 디스크를 파티션하는 방법은 무엇입니까? 사용자는 이 컴퓨터 아래의 관리를 직접 클릭한 다음 디스크 관리를 클릭하여 작업 설정을 수행할 수 있습니다. 이 사이트에서는 Win11에서 하드 드라이브를 분할하는 방법에 대한 자세한 튜토리얼을 사용자에게 제공합니다. win11에서 하드 디스크를 분할하는 방법에 대한 튜토리얼 1. 먼저 이 컴퓨터를 마우스 오른쪽 버튼으로 클릭하고 컴퓨터 관리를 엽니다. 3. 그런 다음 오른쪽의 디스크 상태를 확인하여 사용 가능한 공간이 있는지 확인합니다. (여유 공간이 있는 경우 6단계로 건너뜁니다.) 5. 그런 다음 확보해야 할 공간을 선택하고 압축을 클릭합니다. 7. 원하는 단순 볼륨 크기를 입력하고 다음을 클릭합니다. 9. 마지막으로 마침을 클릭하여 새 파티션을 만듭니다.
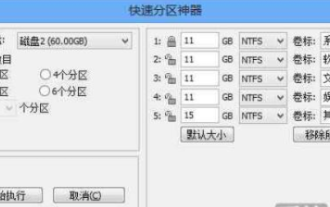 win10 파티션 조각 모음을 위한 정수 계산 솔루션
Dec 30, 2023 pm 07:41 PM
win10 파티션 조각 모음을 위한 정수 계산 솔루션
Dec 30, 2023 pm 07:41 PM
Windows에서 파티션을 나눌 때 계산된 값을 1GB=1024MB로 입력하면 항상 정수 대신 259.5GB/59.99GB/60.01GB와 같은 결과가 나타납니다. 그러면 win10 파티션 정수는 어떻게 계산됩니까? 아래 에디터와 함께 살펴보겠습니다. win10 파티션의 정수 계산 공식: 1. 공식은 (X-1)×4+1024×X=Y입니다. 2. Windows의 정수 파티션을 구하려면 공식을 알아야 합니다. 이 공식을 통해 계산된 값은 Windows에서 정수 GB 값으로 인식될 수 있습니다. 3. 그 중 X는 얻고자 하는 정수 파티션의 값, 단위는 GB, Y는 파티셔닝 시 입력해야 하는 숫자이다.
 Deepin Linux 하드 디스크 파티셔닝 및 설치 튜토리얼: 효율적인 시스템 배포를 위한 단계별
Feb 10, 2024 pm 07:06 PM
Deepin Linux 하드 디스크 파티셔닝 및 설치 튜토리얼: 효율적인 시스템 배포를 위한 단계별
Feb 10, 2024 pm 07:06 PM
Deepin Linux를 설치하기 전에 하드 디스크를 분할해야 합니다. 하드 디스크 분할은 물리적 하드 디스크를 여러 논리적 영역으로 나누는 프로세스입니다. 올바른 분할 방법은 성능과 성능을 향상시킬 수 있습니다. 안정성이 있으므로 이 단계는 매우 중요합니다. 이 문서에서는 자세하고 심층적인 Linux 하드 디스크 파티셔닝 및 설치 튜토리얼을 제공합니다. 준비 1. 파티션을 나누면 하드 드라이브의 모든 데이터가 지워지므로 중요한 데이터를 백업했는지 확인하십시오. 2. USB 플래시 드라이브, CD 등 Deepin Linux 설치 미디어를 준비합니다. 하드 디스크 파티션 1. BIOS 설정으로 부팅하고 부팅 미디어를 기본 부팅 장치로 설정합니다. 2. 컴퓨터를 다시 시작하고 부팅 미디어에서 부팅하여 시스템 설치 인터페이스로 들어갑니다. 3.선택
