

python实现汉诺塔递归算法经典案例

学到递归的时候有个汉诺塔的练习,汉诺塔应该是学习计算机递归算法的经典入门案例了,所以本人觉得可以写篇博客来表达一下自己的见解。这markdown编辑器还不怎么会用,可能写的有点格式有点丑啦,各位看官多多见谅.
网上找了一张汉诺塔的图片,汉诺塔就是利用用中间的柱子把最左边的柱子上的圆盘依次从大到小叠上去,说白了就是c要跟原来的a一样

废话少说,先亮代码
def move(n, a, buffer, c):
if(n == 1):
print(a,"->",c)
return
move(n-1, a, c, buffer)
move(1, a, buffer, c)
move(n-1, buffer, a, c)
move(3, "a", "b", "c")
首先是定义了一个移动的函数,四个参数分别代表,a柱上的盘子个数,buffer也就是b柱,命名为buffer便于理解,顾名思义就是一个a移动到c的缓冲区.然后c就是目标柱子
下面我们来读函数代码
递归的一般写法,肯定有个中止递归循环的条件,所以在判断a柱上的盘子个数为1的时候既可以中止递归并返回,a柱上面只有一个的时候肯定就是把a移动到c了,重点是下面的代码,递归其实是一种很抽象的算法,我们要利用抽象思维去想汉诺塔这个问题,把a柱上的盘子想成两份,就是上面的盘子和最底下的盘子,如果所示
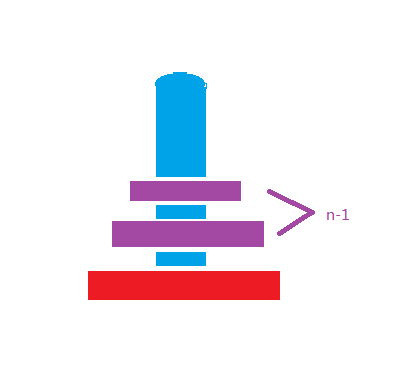
我们不关心上面的盘子到底有几个,我们每次的操作就是把最底下的盘子通过缓冲区 b柱 buffer 移动到c柱。
童鞋们肯定在想为啥要酱紫移动呢,其实这是一种总结归纳吧,你自己玩一下汉诺塔游戏就会发现规律,其实这个游戏就是不停的把上面的所有的想方设法的移到b上,然后把a最后最大的那个弄到c,然后再绞尽脑汁的把b上的移动到c,这时候你就发现,原来b上的也要先通过空的也就是a来存放当前b上面的n-1个,然后把b的最大最后的移动到c,这里规律就体现出来了,也可以抽象出移动的方法,并可以以此设计出程序算法.
以下我们来利用刚才的抽象思维解读剩余代码
move(n-1, a, c, buffer)
这段代码就是表示把刚才所说的a柱的上面的n-1个,通过c按照从小到大的规则先移动到缓冲区buffer。此函数进入递归。
move(1, a, buffer, c)
当上面的语句执行完成,也就是n-1个盘子的递归移动完成之后,执行此语句,就是把a柱上的一个盘子移动到c,也就是所谓的最底下的盘子
move(n-1, buffer , a, c)
最后一步,就是刚才把a上面的n-1个都移动到了buffer上面,肯定要通过a移动到c才能完成整个汉诺塔的移动啊,于是最后一步自然是把刚才的n-1个通过a当缓冲区移动到c柱上.
我来写下整个移动流程,以a柱上有3个为例子
/**
我把3个盘子的汉诺塔全部通过代码演示,按缩进原则,每一个缩进即进一个递归函数,每打印一次即中止当前递归,也就是每个print
说明:
1.n = 3, n = 2, n = 1是每次执行if(n == 1)的结果,这里就不写判断了,相信童鞋们也能看懂,也就是n不等与1时就减1进入递归
2.请注意a,b,c柱每次进入函数的顺序,不要被形参带错路了,看准每次函数参数的实参
**/
move(3, "a", "b", "c")
n=3:
//开始从a上移动n-1即2个盘子通过c移动到b,以腾出c供a最后一个盘子移动
move(2, "a","c","b")
n=2:
//开始进行n=2的一个递归,把当前a('a')柱上的n-1个盘子通过c('b')移动到b('c')
move(1, "a", "b", "c")
n=1:
//n=2的第一个递归完成,打印结果,执行当前子函数剩余代码
print("a", "->", "c")
move(1, "a", "c", "b")
n=1:
print("a", "->", "b")
move(1, "c", "a", "b")
n=1:
print("c", "->", "b")
//到这里完成了a柱上面的n-1即是2个盘子的移动
//开始把a柱上最后一个盘子移动到c柱上
move(1, "a", "b", "c")
n=1:
print("a", "->", "c")
//到这里完成移动a柱上的最后一个盘子到c柱上
move(2, "b", "a", "c")
n=2:
//开始进行n=2的第二个递归,即把当前b('b')的盘子(n-1个)通过a('a')移动到c('c')上
move(1, "b", "c", "a")
n=1:
//n=2 的第二个递归完成,打印结果并执行当前子函数的剩余代码
print("b", "->", "a")
move(1, "b", "a", "c")
n=1:
print("b", "->", "c")
move(1, "a", "b", "c")
n=1:
print("a", "->", "c")
//到这里把b上的盘子通过a移动到c,
//整个代码执行完毕,汉诺塔移动完成
最后的打印结果为:

童鞋们理解了汉诺塔的递归算法原理后,可以写个程序来试试,这里只是学到Python的递归所以用了Python,童鞋们可以用其他语言实现,汉诺塔确实能帮助理解递归原理,递归在程序设计中的重要性不言而喻啦!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7682
7682
 15
1639
14
1393
52
1286
25
1229
29
15
1639
14
1393
52
1286
25
1229
29

 Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 보려고 할 때 Linux 터미널에서 Python 버전을 볼 때 권한 문제에 대한 솔루션 ... Python을 입력하십시오 ...
 10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?
Apr 02, 2025 am 07:18 AM
10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?
Apr 02, 2025 am 07:18 AM
10 시간 이내에 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법은 무엇입니까? 컴퓨터 초보자에게 프로그래밍 지식을 가르치는 데 10 시간 밖에 걸리지 않는다면 무엇을 가르치기로 선택 하시겠습니까?
 중간 독서를 위해 Fiddler를 사용할 때 브라우저에서 감지되는 것을 피하는 방법은 무엇입니까?
Apr 02, 2025 am 07:15 AM
중간 독서를 위해 Fiddler를 사용할 때 브라우저에서 감지되는 것을 피하는 방법은 무엇입니까?
Apr 02, 2025 am 07:15 AM
Fiddlerevery Where를 사용할 때 Man-in-the-Middle Reading에 Fiddlereverywhere를 사용할 때 감지되는 방법 ...
 한 데이터 프레임의 전체 열을 Python의 다른 구조를 가진 다른 데이터 프레임에 효율적으로 복사하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:15 PM
한 데이터 프레임의 전체 열을 Python의 다른 구조를 가진 다른 데이터 프레임에 효율적으로 복사하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:15 PM
Python의 Pandas 라이브러리를 사용할 때는 구조가 다른 두 데이터 프레임 사이에서 전체 열을 복사하는 방법이 일반적인 문제입니다. 두 개의 dats가 있다고 가정 해
 Uvicorn은 Serving_forever ()없이 HTTP 요청을 어떻게 지속적으로 듣습니까?
Apr 01, 2025 pm 10:51 PM
Uvicorn은 Serving_forever ()없이 HTTP 요청을 어떻게 지속적으로 듣습니까?
Apr 01, 2025 pm 10:51 PM
Uvicorn은 HTTP 요청을 어떻게 지속적으로 듣습니까? Uvicorn은 ASGI를 기반으로 한 가벼운 웹 서버입니다. 핵심 기능 중 하나는 HTTP 요청을 듣고 진행하는 것입니다 ...
 문자열을 통해 객체를 동적으로 생성하고 방법을 파이썬으로 호출하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:18 PM
문자열을 통해 객체를 동적으로 생성하고 방법을 파이썬으로 호출하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:18 PM
파이썬에서 문자열을 통해 객체를 동적으로 생성하고 메소드를 호출하는 방법은 무엇입니까? 특히 구성 또는 실행 해야하는 경우 일반적인 프로그래밍 요구 사항입니다.
 Linux 터미널에서 Python (Version 명령)을 사용할 때 권한 문제를 해결하는 방법은 무엇입니까?
Apr 02, 2025 am 06:36 AM
Linux 터미널에서 Python (Version 명령)을 사용할 때 권한 문제를 해결하는 방법은 무엇입니까?
Apr 02, 2025 am 06:36 AM
Linux 터미널에서 Python 사용 ...
 Inversiting.com의 크롤링 메커니즘을 우회하는 방법은 무엇입니까?
Apr 02, 2025 am 07:03 AM
Inversiting.com의 크롤링 메커니즘을 우회하는 방법은 무엇입니까?
Apr 02, 2025 am 07:03 AM
Investing.com의 크롤링 전략 이해 많은 사람들이 종종 Investing.com (https://cn.investing.com/news/latest-news)에서 뉴스 데이터를 크롤링하려고합니다.
