

使用Python编写基于DHT协议的BT资源爬虫

关于DHT协议
DHT协议作为BT协议的一个辅助,是非常好玩的。它主要是为了在BT正式下载时得到种子或者BT资源。传统的网络,需要一台中央服务器存放种子或者BT资源,不仅浪费服务器资源,还容易出现单点的各种问题,而DHT网络则是为了去中心化,也就是说任意时刻,这个网络总有节点是亮的,你可以去询问问这些亮的节点,从而将自己加入DHT网络。
要实现DHT协议的网络爬虫,主要分3步,第一步是得到资源信息(infohash,160bit,20字节,可以编码为40字节的十六进制字符串),第二步是确认这些infohash是有效的,第三步是通过有效的infohash下载到BT的种子文件,从而得到对这个资源的完整描述。
其中第一步是其他节点用DHT协议中的get_peers方法向爬虫发送请求得到的,第二步是其他节点用DHT协议中的announce_peer向爬虫发送请求得到的,第三步可以有几种方式得到,比如可以去一些保存种子的网站根据infohash直接下载到,或者通过announce_peer的节点来下载到,具体如何实现,可以取决于你自己的爬虫。
DHT协议中的主要几个操作:
主要负责通过UDP与外部节点交互,封装4种基本操作的请求以及相应。
ping:检查一个节点是否“存活”
在一个爬虫里主要有两个地方用到ping,第一是初始路由表时,第二是验证节点是否存活时
find_node:向一个节点发送查找节点的请求
在一个爬虫中主要也是两个地方用到find_node,第一是初始路由表时,第二是验证桶是否存活时
get_peers:向一个节点发送查找资源的请求
在爬虫中有节点向自己请求时不仅像个正常节点一样做出回应,还需要以此资源的info_hash为机会尽可能多的去认识更多的节点。如图,get_peers实际上最后一步是announce_peer,但是因为爬虫不能announce_peer,所以实际上get_peers退化成了find_node操作。

announce_peer:向一个节点发送自己已经开始下载某个资源的通知
爬虫中不能用announce_peer,因为这就相当于通报虚假资源,对方很容易从上下文中判断你是否通报了虚假资源从而把你禁掉。
基于Python的DHT爬虫
修改自github开源爬虫,原作者名字有些。。,这里直接将项目地址列出:https://github.com/Fuck-You-GFW/simDHT,有github帐号的请给原作者star,后续我将结果放入db,外加用tornado做一个简单的查询界面出来放在github上,先备份一下代码
#!/usr/bin/env python
# encoding: utf-8
import socket
from hashlib import sha1
from random import randint
from struct import unpack
from socket import inet_ntoa
from threading import Timer, Thread
from time import sleep
from collections import deque
from bencode import bencode, bdecode
BOOTSTRAP_NODES = (
("router.bittorrent.com", 6881),
("dht.transmissionbt.com", 6881),
("router.utorrent.com", 6881)
)
TID_LENGTH = 2
RE_JOIN_DHT_INTERVAL = 3
TOKEN_LENGTH = 2
def entropy(length):
return "".join(chr(randint(0, 255)) for _ in xrange(length))
def random_id():
h = sha1()
h.update(entropy(20))
return h.digest()
def decode_nodes(nodes):
n = []
length = len(nodes)
if (length % 26) != 0:
return n
for i in range(0, length, 26):
nid = nodes[i:i+20]
ip = inet_ntoa(nodes[i+20:i+24])
port = unpack("!H", nodes[i+24:i+26])[0]
n.append((nid, ip, port))
return n
def timer(t, f):
Timer(t, f).start()
def get_neighbor(target, nid, end=10):
return target[:end]+nid[end:]
class KNode(object):
def __init__(self, nid, ip, port):
self.nid = nid
self.ip = ip
self.port = port
class DHTClient(Thread):
def __init__(self, max_node_qsize):
Thread.__init__(self)
self.setDaemon(True)
self.max_node_qsize = max_node_qsize
self.nid = random_id()
self.nodes = deque(maxlen=max_node_qsize)
def send_krpc(self, msg, address):
try:
self.ufd.sendto(bencode(msg), address)
except Exception:
pass
def send_find_node(self, address, nid=None):
nid = get_neighbor(nid, self.nid) if nid else self.nid
tid = entropy(TID_LENGTH)
msg = {
"t": tid,
"y": "q",
"q": "find_node",
"a": {
"id": nid,
"target": random_id()
}
}
self.send_krpc(msg, address)
def join_DHT(self):
for address in BOOTSTRAP_NODES:
self.send_find_node(address)
def re_join_DHT(self):
if len(self.nodes) == 0:
self.join_DHT()
timer(RE_JOIN_DHT_INTERVAL, self.re_join_DHT)
def auto_send_find_node(self):
wait = 1.0 / self.max_node_qsize
while True:
try:
node = self.nodes.popleft()
self.send_find_node((node.ip, node.port), node.nid)
except IndexError:
pass
sleep(wait)
def process_find_node_response(self, msg, address):
nodes = decode_nodes(msg["r"]["nodes"])
for node in nodes:
(nid, ip, port) = node
if len(nid) != 20: continue
if ip == self.bind_ip: continue
if port < 1 or port > 65535: continue
n = KNode(nid, ip, port)
self.nodes.append(n)
class DHTServer(DHTClient):
def __init__(self, master, bind_ip, bind_port, max_node_qsize):
DHTClient.__init__(self, max_node_qsize)
self.master = master
self.bind_ip = bind_ip
self.bind_port = bind_port
self.process_request_actions = {
"get_peers": self.on_get_peers_request,
"announce_peer": self.on_announce_peer_request,
}
self.ufd = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, socket.IPPROTO_UDP)
self.ufd.bind((self.bind_ip, self.bind_port))
timer(RE_JOIN_DHT_INTERVAL, self.re_join_DHT)
def run(self):
self.re_join_DHT()
while True:
try:
(data, address) = self.ufd.recvfrom(65536)
msg = bdecode(data)
self.on_message(msg, address)
except Exception:
pass
def on_message(self, msg, address):
try:
if msg["y"] == "r":
if msg["r"].has_key("nodes"):
self.process_find_node_response(msg, address)
elif msg["y"] == "q":
try:
self.process_request_actions[msg["q"]](msg, address)
except KeyError:
self.play_dead(msg, address)
except KeyError:
pass
def on_get_peers_request(self, msg, address):
try:
infohash = msg["a"]["info_hash"]
tid = msg["t"]
nid = msg["a"]["id"]
token = infohash[:TOKEN_LENGTH]
msg = {
"t": tid,
"y": "r",
"r": {
"id": get_neighbor(infohash, self.nid),
"nodes": "",
"token": token
}
}
self.send_krpc(msg, address)
except KeyError:
pass
def on_announce_peer_request(self, msg, address):
try:
infohash = msg["a"]["info_hash"]
#print msg["a"]
tname = msg["a"]["name"]
token = msg["a"]["token"]
nid = msg["a"]["id"]
tid = msg["t"]
if infohash[:TOKEN_LENGTH] == token:
if msg["a"].has_key("implied_port") and msg["a"]["implied_port"] != 0:
port = address[1]
else:
port = msg["a"]["port"]
if port < 1 or port > 65535: return
self.master.log(infohash, (address[0], port),tname)
except Exception:
pass
finally:
self.ok(msg, address)
def play_dead(self, msg, address):
try:
tid = msg["t"]
msg = {
"t": tid,
"y": "e",
"e": [202, "Server Error"]
}
self.send_krpc(msg, address)
except KeyError:
pass
def ok(self, msg, address):
try:
tid = msg["t"]
nid = msg["a"]["id"]
msg = {
"t": tid,
"y": "r",
"r": {
"id": get_neighbor(nid, self.nid)
}
}
self.send_krpc(msg, address)
except KeyError:
pass
class Master(object):
def log(self, infohash,address=None,tname=None):
hexinfohash = infohash.encode("hex")
print "info_hash is: %s,name is: %s from %s:%s" % (
hexinfohash,tname, address[0], address[1]
)
print "magnet:?xt=urn:btih:%s&dn=%s" % (hexinfohash, tname)
# using example
if __name__ == "__main__":
# max_node_qsize bigger, bandwith bigger, speed higher
dht = DHTServer(Master(), "0.0.0.0", 6882, max_node_qsize=200)
dht.start()
dht.auto_send_find_node()
PS: DHT协议中有几个重点的需要澄清的地方:
1. node与infohash同样使用160bit的表示方式,160bit意味着整个节点空间有2^160 = 730750818665451459101842416358141509827966271488,是48位10进制,也就是说有百亿亿亿亿亿个节点空间,这么大的节点空间,是足够存放你的主机节点以及任意的资源信息的。
2. 每个节点有张路由表。每张路由表由一堆K桶组成,所谓K桶,就是桶中最多只能放K个节点,默认是8个。而桶的保存则是类似一颗前缀树的方式。相当于一张8桶的路由表中最多有160-4个K桶。
3. 根据DHT协议的规定,每个infohash都是有位置的,因此,两个infohash之间就有距离一说,而两个infohash的距离就可以用异或来表示,即infohash1 xor infohash2,也就是说,高位一样的话,他们的距离就近,反之则远,这样可以快速的计算两个节点的距离。计算这个距离有什么用呢,在DHT网络中,如果一个资源的infohash与一个节点的infohash越近则该节点越有可能拥有该资源的信息,为什么呢?可以想象,因为人人都用同样的距离算法去递归的询问离资源接近的节点,并且只要该节点做出了回应,那么就会得到一个announce信息,也就是说跟资源infohash接近的节点就有更大的概率拿到该资源的infohash
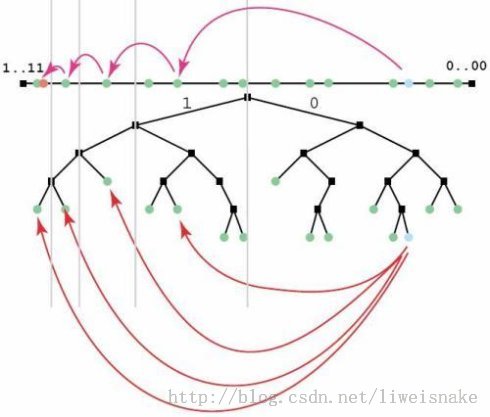
4. 根据上述算法,DHT中的查询是跳跃式查询,可以迅速的跨越的的节点桶而接近目标节点桶。之所以在远处能够大幅度跳跃,而在近处只能小幅度跳跃,原因是每个节点的路由表中离自身越接近的节点保存得越多,如下图
5. 在一个DHT网络中当爬虫并不容易,不像普通爬虫一样,看到资源就可以主动爬下来,相反,因为得到资源的方式(get_peers, announce_peer)都是被动的,所以爬虫的方式就有些变化了,爬虫所要做的事就是像个正常节点一样去响应其他节点的查询,并且得到其他节点的回应,把其中的数据收集下来就算是完成工作了。而爬虫唯一能做的,是尽可能的去多认识其他节点,这样,才能有更多其他节点来向你询问。
6. 有人说,那么我把DHT爬虫的K桶中的容量K增大是不是就能增加得到资源的机会,其实不然,之前也分析过了,DHT爬虫最重要的信息来源全是被动的,因为你不能增大别人的K,所以距离远的节点保存你自身的概率就越小,当然距离远的节点去请求你的概率相对也比较小。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7454
7454
 15
1374
52
77
11
40
19
14
9
15
1374
52
77
11
40
19
14
9

 PS가 계속 로딩을 보여주는 이유는 무엇입니까?
Apr 06, 2025 pm 06:39 PM
PS가 계속 로딩을 보여주는 이유는 무엇입니까?
Apr 06, 2025 pm 06:39 PM
PS "로드"문제는 자원 액세스 또는 처리 문제로 인한 것입니다. 하드 디스크 판독 속도는 느리거나 나쁘다 : CrystalDiskinfo를 사용하여 하드 디스크 건강을 확인하고 문제가있는 하드 디스크를 교체하십시오. 불충분 한 메모리 : 고해상도 이미지 및 복잡한 레이어 처리에 대한 PS의 요구를 충족시키기 위해 메모리 업그레이드 메모리. 그래픽 카드 드라이버는 구식 또는 손상됩니다. 운전자를 업데이트하여 PS와 그래픽 카드 간의 통신을 최적화하십시오. 파일 경로는 너무 길거나 파일 이름에는 특수 문자가 있습니다. 짧은 경로를 사용하고 특수 문자를 피하십시오. PS 자체 문제 : PS 설치 프로그램을 다시 설치하거나 수리하십시오.
 PS가 시작될 때 로딩 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:36 PM
PS가 시작될 때 로딩 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:36 PM
부팅 할 때 "로드"에 PS가 붙어있는 여러 가지 이유로 인해 발생할 수 있습니다. 손상되거나 충돌하는 플러그인을 비활성화합니다. 손상된 구성 파일을 삭제하거나 바꾸십시오. 불충분 한 메모리를 피하기 위해 불필요한 프로그램을 닫거나 메모리를 업그레이드하십시오. 하드 드라이브 독서 속도를 높이기 위해 솔리드 스테이트 드라이브로 업그레이드하십시오. 손상된 시스템 파일 또는 설치 패키지 문제를 복구하기 위해 PS를 다시 설치합니다. 시작 오류 로그 분석의 시작 과정에서 오류 정보를 봅니다.
 PS가 파일을 열 때로드 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:33 PM
PS가 파일을 열 때로드 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:33 PM
"로드"는 PS에서 파일을 열 때 말더듬이 발생합니다. 그 이유에는 너무 크거나 손상된 파일, 메모리 불충분, 하드 디스크 속도가 느리게, 그래픽 카드 드라이버 문제, PS 버전 또는 플러그인 충돌이 포함될 수 있습니다. 솔루션은 다음과 같습니다. 파일 크기 및 무결성 확인, 메모리 증가, 하드 디스크 업그레이드, 그래픽 카드 드라이버 업데이트, 의심스러운 플러그인 제거 또는 비활성화 및 PS를 다시 설치하십시오. 이 문제는 PS 성능 설정을 점차적으로 확인하고 잘 활용하고 우수한 파일 관리 습관을 개발함으로써 효과적으로 해결할 수 있습니다.
 PS가 항상 로딩되고 있음을 보여줄 때 로딩 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:30 PM
PS가 항상 로딩되고 있음을 보여줄 때 로딩 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:30 PM
PS 카드가 "로드"되어 있습니까? 솔루션에는 컴퓨터 구성 (메모리, 하드 디스크, 프로세서) 확인, 하드 디스크 조각 청소, 그래픽 카드 드라이버 업데이트, PS 설정 조정, PS 재설치 및 우수한 프로그래밍 습관 개발이 포함됩니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 PS 페더 링은 어떻게 전환의 부드러움을 제어합니까?
Apr 06, 2025 pm 07:33 PM
PS 페더 링은 어떻게 전환의 부드러움을 제어합니까?
Apr 06, 2025 pm 07:33 PM
깃털 통제의 열쇠는 점진적인 성격을 이해하는 것입니다. PS 자체는 그라디언트 곡선을 직접 제어하는 옵션을 제공하지 않지만 여러 깃털, 일치하는 마스크 및 미세 선택으로 반경 및 구배 소프트를 유연하게 조정하여 자연스럽게 전이 효과를 달성 할 수 있습니다.
 MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 성능 최적화는 설치 구성, 인덱싱 및 쿼리 최적화, 모니터링 및 튜닝의 세 가지 측면에서 시작해야합니다. 1. 설치 후 innodb_buffer_pool_size 매개 변수와 같은 서버 구성에 따라 my.cnf 파일을 조정해야합니다. 2. 과도한 인덱스를 피하기 위해 적절한 색인을 작성하고 Execution 명령을 사용하여 실행 계획을 분석하는 것과 같은 쿼리 문을 최적화합니다. 3. MySQL의 자체 모니터링 도구 (showprocesslist, showstatus)를 사용하여 데이터베이스 건강을 모니터링하고 정기적으로 백업 및 데이터베이스를 구성하십시오. 이러한 단계를 지속적으로 최적화함으로써 MySQL 데이터베이스의 성능을 향상시킬 수 있습니다.
 PS 카드가 로딩 인터페이스에 있으면 어떻게해야합니까?
Apr 06, 2025 pm 06:54 PM
PS 카드가 로딩 인터페이스에 있으면 어떻게해야합니까?
Apr 06, 2025 pm 06:54 PM
PS 카드의로드 인터페이스는 소프트웨어 자체 (파일 손상 또는 플러그인 충돌), 시스템 환경 (DIFE 드라이버 또는 시스템 파일 손상) 또는 하드웨어 (하드 디스크 손상 또는 메모리 스틱 고장)로 인해 발생할 수 있습니다. 먼저 컴퓨터 자원이 충분한 지 확인하고 배경 프로그램을 닫고 메모리 및 CPU 리소스를 릴리스하십시오. PS 설치를 수정하거나 플러그인의 호환성 문제를 확인하십시오. PS 버전을 업데이트하거나 폴백합니다. 그래픽 카드 드라이버를 확인하고 업데이트하고 시스템 파일 확인을 실행하십시오. 위의 문제를 해결하면 하드 디스크 감지 및 메모리 테스트를 시도 할 수 있습니다.
