

让python在hadoop上跑起来

本文实例讲解的是一般的hadoop入门程序“WordCount”,就是首先写一个map程序用来将输入的字符串分割成单个的单词,然后reduce这些单个的单词,相同的单词就对其进行计数,不同的单词分别输出,结果输出每一个单词出现的频数。
注意:关于数据的输入输出是通过sys.stdin(系统标准输入)和sys.stdout(系统标准输出)来控制数据的读入与输出。所有的脚本执行之前都需要修改权限,否则没有执行权限,例如下面的脚本创建之前使用“chmod +x mapper.py”
1.mapper.py
#!/usr/bin/env python
import sys
for line in sys.stdin: # 遍历读入数据的每一行
line = line.strip() # 将行尾行首的空格去除
words = line.split() #按空格将句子分割成单个单词
for word in words:
print '%s\t%s' %(word, 1)
2.reducer.py
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None # 为当前单词
current_count = 0 # 当前单词频数
word = None
for line in sys.stdin:
words = line.strip() # 去除字符串首尾的空白字符
word, count = words.split('\t') # 按照制表符分隔单词和数量
try:
count = int(count) # 将字符串类型的‘1'转换为整型1
except ValueError:
continue
if current_word == word: # 如果当前的单词等于读入的单词
current_count += count # 单词频数加1
else:
if current_word: # 如果当前的单词不为空则打印其单词和频数
print '%s\t%s' %(current_word, current_count)
current_count = count # 否则将读入的单词赋值给当前单词,且更新频数
current_word = word
if current_word == word:
print '%s\t%s' %(current_word, current_count)
在shell中运行以下脚本,查看输出结果:
echo "foo foo quux labs foo bar zoo zoo hying" | /home/wuying/mapper.py | sort -k 1,1 | /home/wuying/reducer.py # echo是将后面“foo ****”字符串输出,并利用管道符“|”将输出数据作为mapper.py这个脚本的输入数据,并将mapper.py的数据输入到reducer.py中,其中参数sort -k 1,1是将reducer的输出内容按照第一列的第一个字母的ASCII码值进行升序排序
其实,我觉得后面这个reducer.py处理单词频数有点麻烦,将单词存储在字典里面,单词作为‘key',每一个单词出现的频数作为'value',进而进行频数统计感觉会更加高效一点。因此,改进脚本如下:
mapper_1.py
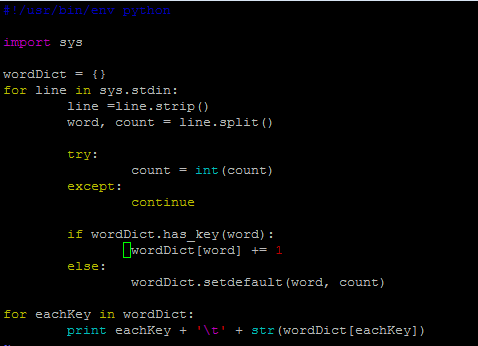
但是,貌似写着写着用了两个循环,反而效率低了。关键是不太明白这里的current_word和current_count的作用,如果从字面上老看是当前存在的单词,那么怎么和遍历读取的word和count相区别?
下面看一些脚本的输出结果:
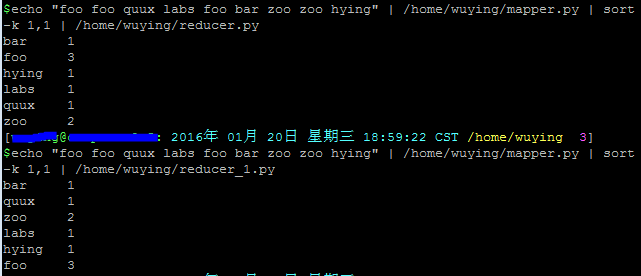
我们可以看到,上面同样的输入数据,同样的shell换了不同的reducer,结果后者并没有对数据进行排序,实在是费解~
让Python代码在hadoop上跑起来!
一、准备输入数据
接下来,先下载三本书:
$ mkdir -p tmp/gutenberg $ cd tmp/gutenberg $ wget http://www.gutenberg.org/ebooks/20417.txt.utf-8 $ wget http://www.gutenberg.org/files/5000/5000-8.txt $ wget http://www.gutenberg.org/ebooks/4300.txt.utf-8
然后把这三本书上传到hdfs文件系统上:
$ hdfs dfs -mkdir /user/${whoami}/input # 在hdfs上的该用户目录下创建一个输入文件的文件夹
$ hdfs dfs -put /home/wuying/tmp/gutenberg/*.txt /user/${whoami}/input # 上传文档到hdfs上的输入文件夹中
寻找你的streaming的jar文件存放地址,注意2.6的版本放到share目录下了,可以进入hadoop安装目录寻找该文件:
$ cd $HADOOP_HOME $ find ./ -name "*streaming*"
然后就会找到我们的share文件夹中的hadoop-straming*.jar文件:
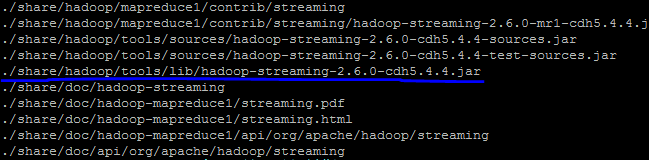
寻找速度可能有点慢,因此你最好是根据自己的版本号到对应的目录下去寻找这个streaming文件,由于这个文件的路径比较长,因此我们可以将它写入到环境变量:
$ vi ~/.bashrc # 打开环境变量配置文件 # 在里面写入streaming路径 export STREAM=$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar
由于通过streaming接口运行的脚本太长了,因此直接建立一个shell名称为run.sh来运行:
hadoop jar $STREAM \ -files ./mapper.py,./reducer.py \ -mapper ./mapper.py \ -reducer ./reducer.py \ -input /user/$(whoami)/input/*.txt \ -output /user/$(whoami)/output
然后"source run.sh"来执行mapreduce。结果就响当当的出来啦。这里特别要提醒一下:
1、一定要把本地的输入文件转移到hdfs系统上面,否则无法识别你的input内容;
2、一定要有权限,一定要在你的hdfs系统下面建立你的个人文件夹否则就会被denied,是的,就是这两个错误搞得我在服务器上面痛不欲生,四处问人的感觉真心不如自己清醒对待来的好;
3、如果你是第一次在服务器上面玩hadoop,建议在这之前请在自己的虚拟机或者linux系统上面配置好伪分布式然后入门hadoop来的比较不那么头疼,之前我并不知道我在服务器上面运维没有给我运行的权限,后来在自己的虚拟机里面运行一下example实例以及wordcount才找到自己的错误。
好啦,然后不出意外,就会complete啦,你就可以通过如下方式查看计数结果:
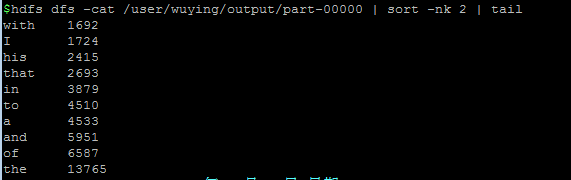
以上就是本文的全部内容,希望对大家学习python软件编程有所帮助。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7342
7342
 9
1627
14
1352
46
1265
25
1210
29
9
1627
14
1352
46
1265
25
1210
29

 XML을 PDF로 변환 할 수있는 모바일 앱이 있습니까?
Apr 02, 2025 pm 08:54 PM
XML을 PDF로 변환 할 수있는 모바일 앱이 있습니까?
Apr 02, 2025 pm 08:54 PM
XML을 PDF로 직접 변환하는 응용 프로그램은 근본적으로 다른 두 형식이므로 찾을 수 없습니다. XML은 데이터를 저장하는 데 사용되는 반면 PDF는 문서를 표시하는 데 사용됩니다. 변환을 완료하려면 Python 및 ReportLab과 같은 프로그래밍 언어 및 라이브러리를 사용하여 XML 데이터를 구문 분석하고 PDF 문서를 생성 할 수 있습니다.
 protobuf 및 연결 문자열 상수에서 열거 유형을 정의하는 방법은 무엇입니까?
Apr 02, 2025 pm 03:36 PM
protobuf 및 연결 문자열 상수에서 열거 유형을 정의하는 방법은 무엇입니까?
Apr 02, 2025 pm 03:36 PM
protobuf에서 문자열 상수 열거를 정의하는 문제 protobuf를 사용할 때 종종 열거 유형을 문자열 상수와 연관시켜야하는 상황이 발생합니다 ...
 XML에서 댓글 내용을 수정하는 방법
Apr 02, 2025 pm 06:15 PM
XML에서 댓글 내용을 수정하는 방법
Apr 02, 2025 pm 06:15 PM
작은 XML 파일의 경우 주석 내용을 텍스트 편집기로 직접 교체 할 수 있습니다. 큰 파일의 경우 XML 파서를 사용하여 효율성과 정확성을 보장하기 위해 수정하는 것이 좋습니다. XML 주석을 삭제할 때주의를 기울이면 주석을 유지하면 일반적으로 코드 이해 및 유지 관리에 도움이됩니다. 고급 팁은 XML 파서를 사용하여 댓글을 수정하기위한 파이썬 샘플 코드를 제공하지만 사용 된 XML 라이브러리에 따라 특정 구현을 조정해야합니다. XML 파일을 수정할 때 인코딩 문제에주의하십시오. UTF-8 인코딩을 사용하고 인코딩 형식을 지정하는 것이 좋습니다.
 XML 수정에 프로그래밍이 필요합니까?
Apr 02, 2025 pm 06:51 PM
XML 수정에 프로그래밍이 필요합니까?
Apr 02, 2025 pm 06:51 PM
XML 컨텐츠를 수정하려면 프로그래밍이 필요합니다. 대상 노드를 추가, 삭제, 수정 및 확인하려면 정확한 찾기가 필요하기 때문입니다. 프로그래밍 언어에는 XML을 처리하기위한 해당 라이브러리가 있으며 운영 데이터베이스와 같이 안전하고 효율적이며 제어 가능한 작업을 수행 할 수있는 API를 제공합니다.
 휴대폰에서 XML을 PDF로 변환 할 때 변환 속도가 빠르나요?
Apr 02, 2025 pm 10:09 PM
휴대폰에서 XML을 PDF로 변환 할 때 변환 속도가 빠르나요?
Apr 02, 2025 pm 10:09 PM
모바일 XML에서 PDF의 속도는 다음 요인에 따라 다릅니다. XML 구조의 복잡성. 모바일 하드웨어 구성 변환 방법 (라이브러리, 알고리즘) 코드 품질 최적화 방법 (효율적인 라이브러리 선택, 알고리즘 최적화, 캐시 데이터 및 다중 스레딩 사용). 전반적으로 절대적인 답변은 없으며 특정 상황에 따라 최적화해야합니다.
 이미지로 변환 된 XML의 크기를 제어하는 방법은 무엇입니까?
Apr 02, 2025 pm 07:24 PM
이미지로 변환 된 XML의 크기를 제어하는 방법은 무엇입니까?
Apr 02, 2025 pm 07:24 PM
XML을 통해 이미지를 생성하려면 XML에서 메타 데이터 (크기, 색상)를 기반으로 이미지를 생성하기 위해 브리지로 그래프 라이브러리 (예 : Pillow 및 JFreeChart)를 사용해야합니다. 이미지의 크기를 제어하는 열쇠는 & lt; width & gt의 값을 조정하는 것입니다. 및 & lt; 높이 & gt; XML의 태그. 그러나 실제 애플리케이션에서 XML 구조의 복잡성, 그래프 드로잉의 편향, 이미지 생성 속도 및 메모리 소비 및 이미지 형식 선택은 모두 생성 된 이미지 크기에 영향을 미칩니다. 따라서 그래픽 라이브러리에 능숙한 XML 구조에 대한 깊은 이해가 필요하고 최적화 알고리즘 및 이미지 형식 선택과 같은 요소를 고려해야합니다.
 XML을 이미지로 변환하는 프로세스는 무엇입니까?
Apr 02, 2025 pm 08:24 PM
XML을 이미지로 변환하는 프로세스는 무엇입니까?
Apr 02, 2025 pm 08:24 PM
XML 이미지를 먼저 변환하려면 먼저 XML 데이터 구조를 결정한 다음 Python의 Matplotlib와 같은 적절한 그래픽 라이브러리를 선택하고 데이터 구조를 기반으로 시각화 전략을 선택하고 데이터 볼륨 및 이미지 형식을 고려하고 효율적인 라이브러리를 수행하거나 필요에 따라 PNG, JPEG 또는 SVG로 저장하십시오.
 XML 형식을 여는 방법
Apr 02, 2025 pm 09:00 PM
XML 형식을 여는 방법
Apr 02, 2025 pm 09:00 PM
대부분의 텍스트 편집기를 사용하여 XML 파일을여십시오. 보다 직관적 인 트리 디스플레이가 필요한 경우 Oxygen XML 편집기 또는 XMLSPy와 같은 XML 편집기를 사용할 수 있습니다. 프로그램에서 XML 데이터를 처리하는 경우 프로그래밍 언어 (예 : Python) 및 XML 라이브러 (예 : XML.etree.elementtree)를 사용하여 구문 분석해야합니다.
