

Python list操作用法总结

本文实例讲述了Python list操作用法。分享给大家供大家参考,具体如下:
List是python中的基本数据结构之一,和Java中的ArrayList有些类似,支持动态的元素的增加。list还支持不同类型的元素在一个列表中,List is an Object。
最基本的创建一个列表的方法
Python list常见操作如下:
创建列表
Python 列表操作
得到列表中的某一个值
value_start = sample_list[0] end_value = sample_list[-1]
删除列表的第一个值
在列表中插入一个值
得到列表的长度
列表遍历
for element in sample_list: print(element)
Python 列表高级操作/技巧
产生一个数值递增列表
num_inc_list = range(30) #will return a list [0,1,2,...,29]
用某个固定值初始化列表
initial_value = 0 list_length = 5 sample_list = [ initial_value for i in range(10)] sample_list = [initial_value]*list_length # sample_list ==[0,0,0,0,0]
附:python内置类型
1、list:列表(即动态数组,C++标准库的vector,但可含不同类型的元素于一个list中)
下标:按下标读写,就当作数组处理
以0开始,有负下标的使用
0第一个元素,-1最后一个元素,
-len第一个元 素,len-1最后一个元素
取list的元素数量
len(list) #list的长度。实际该方法是调用了此对象的__len__(self)方法。
创建连续的list
L = range(1,5) #即 L=[1,2,3,4],不含最后一个元素 L = range(1, 10, 2) #即 L=[1, 3, 5, 7, 9]
list的方法
L.append(var) #追加元素 L.insert(index,var) L.pop(var) #返回最后一个元素,并从list中删除之 L.remove(var) #删除第一次出现的该元素 L.count(var) #该元素在列表中出现的个数 L.index(var) #该元素的位置,无则抛异常 L.extend(list) #追加list,即合并list到L上 L.sort() #排序 L.reverse() #倒序 list 操作符:,+,*,关键字del a[1:] #片段操作符,用于子list的提取 [1,2]+[3,4] #为[1,2,3,4]。同extend() [2]*4 #为[2,2,2,2] del L[1] #删除指定下标的元素 del L[1:3] #删除指定下标范围的元素
list的复制
L1 = L #L1为L的别名,用C来说就是指针地址相同,对L1操作即对L操作。函数参数就是这样传递的 L1 = L[:] #L1为L的克隆,即另一个拷贝。
[
2、dictionary: 字典(即C++标准库的map)
每一个元素是pair,包含key、value两部分。key是Integer或string类型,value 是任意类型。
键是唯一的,字典只认最后一个赋的键值。
dictionary的方法
D.get(key, 0) #同dict[key],多了个没有则返回缺省值,0。[]没有则抛异常
D.has_key(key) #有该键返回TRUE,否则FALSE
D.keys() #返回字典键的列表
D.values()
D.items()
D.update(dict2) #增加合并字典
D.popitem() #得到一个pair,并从字典中删除它。已空则抛异常
D.clear() #清空字典,同del dict
D.copy() #拷贝字典
D.cmp(dict1,dict2) #比较字典,(优先级为元素个数、键大小、键值大小)
#第一个大返回1,小返回-1,一样返回0
dictionary的复制
dict1 = dict #别名 dict2=dict.copy() #克隆,即另一个拷贝。
3、tuple:元组(即常量数组)
可以用list的 [],:操作符提取元素。就是不能直接修改元素。
4、string: 字符串(即不能修改的字符list)
字符串是一个整 体。如果你想直接修改字符串的某一部分,是不可能的。但我们能够读出字符串的某一部分。
子字符串的提取
字符串包含 判断操作符:in,not in
"He" in str
"she" not in str
string模块,还提供了很多方法,如
S.find(substring, [start [,end]]) #可指范围查找子串,返回索引值,否则返回-1 S.rfind(substring,[start [,end]]) #反向查找 S.index(substring,[start [,end]]) #同find,只是找不到产生ValueError异常 S.rindex(substring,[start [,end]])#同上反向查找 S.count(substring,[start [,end]]) #返回找到子串的个数 S.lowercase() S.capitalize() #首字母大写 S.lower() #转小写 S.upper() #转大写 S.swapcase() #大小写互换 S.split(str, ' ') #将string转list,以空格切分 S.join(list, ' ') #将list转string,以空格连接
处理字符串的内置函数
len(str) #串长度
cmp("my friend", str) #字符串比较。第一个大,返回1
max('abcxyz') #寻找字符串中最大的字符
min('abcxyz') #寻找字符串中最小的字符
string的转换
oat(str) #变成浮点数,float("1e-1") 结果为0.1
int(str) #变成整型, int("12") 结果为12
int(str,base) #变成base进制整型数,int("11",2) 结果为2
long(str) #变成长整型,
long(str,base) #变成base进制长整型,
字符串的格式化(注意其转义字符,大多如C语言的,略)
str_format % (参数列表) #参数列表是以tuple的形式定义的,即不可运行中改变
#结果显示为 My brother's height is 180cm
list 和 tuple 的相互转化
tuple(ls) list(ls)
补充:
在python中list也是对象,所以他也有方法和属性,在ptython解释器中 使用help(list)可以查看其文档,部分开放方法如下:
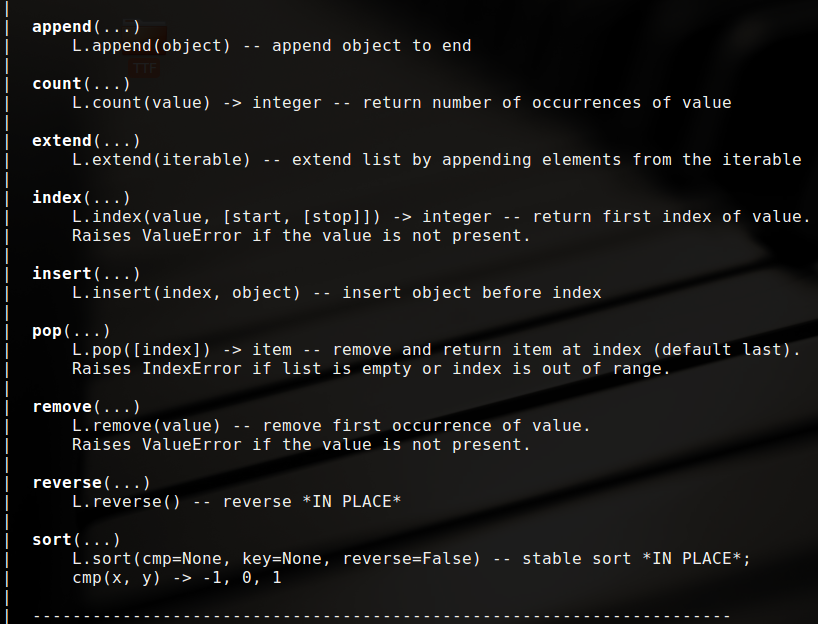
这里以一个实例代码介绍这些方法的具体用法:
# coding=utf-8
# Filename : list.py
# Date: 2012 11 20
# 创建一个list方式
heatList = ['wade','james','bosh','haslem']
tableList = list('123') #list方法接受一个iterable的参数
print 'Miami heat has ',len(heatList),' NBA Stars , they are:'
#遍历list中的元素
for player in heatList:
print player,
#向list添加元素
heatList.append('allen') #方式一:向list结尾添加 参数object
print '\nAfter allen join the team ,they are: '
print heatList
heatList.insert(4,'lewis') #方式二:插入一个元素 参数一:index位置 参数二:object
print 'After lewis join the team, they are:'
print heatList
heatList.extend(tableList) #方式三:扩展列表,参数:iterable参数
print 'After extend a table list,now they are :'
print heatList
#从list删除元素
heatList.remove('1') #删除方式一:参数object 如有重复元素,只会删除最靠前的
print" Remove '1' ..now '1' is gone\n",heatList
heatList.pop() #删除方式二:pop 可选参数index删除指定位置的元素 默认为最后一个元素
print "Pop the last element '3'\n",heatList
del heatList[6] #删除方式三:可以删除制定元素或者列表切片
print "del '3' at the index 6\n",heatList
#逻辑判断
#统计方法 count 参数:具体元素的值
print 'james apears ',heatList.count('wade'),' times'
#in 和 not in
print 'wade in list ? ',('wade' in heatList)
print 'wade not in list ? ',('wade' not in heatList)
#定位 index方法:参数:具体元素的值 可选参数:切片范围
print 'allen in the list ? ',heatList.index('allen')
#下一行代码会报错,因为allen不在前三名里
#print 'allen in the fisrt 3 player ? ',heatList.index('allen',0,3)
#排序和反转代码
print 'When the list is reversed : '
heatList.reverse()
print heatList
print 'When the list is sorted: '
heatList.sort() #sort有三个默认参数 cmp=None,key=None,reverse=False 因此可以制定排序参数以后再讲
print heatList
#list 的分片[start:end] 分片中不包含end位置的元素
print 'elements from 2nd to 3rd ' , heatList[1:3]希望本文所述对大家Python程序设计有所帮助。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7369
7369
 15
1628
14
1354
52
1266
25
1214
29
15
1628
14
1354
52
1266
25
1214
29

 XML을 PDF로 변환 할 수있는 모바일 앱이 있습니까?
Apr 02, 2025 pm 08:54 PM
XML을 PDF로 변환 할 수있는 모바일 앱이 있습니까?
Apr 02, 2025 pm 08:54 PM
XML을 PDF로 직접 변환하는 응용 프로그램은 근본적으로 다른 두 형식이므로 찾을 수 없습니다. XML은 데이터를 저장하는 데 사용되는 반면 PDF는 문서를 표시하는 데 사용됩니다. 변환을 완료하려면 Python 및 ReportLab과 같은 프로그래밍 언어 및 라이브러리를 사용하여 XML 데이터를 구문 분석하고 PDF 문서를 생성 할 수 있습니다.
 XML을 PDF로 변환 할 수있는 모바일 앱이 있습니까?
Apr 02, 2025 pm 09:45 PM
XML을 PDF로 변환 할 수있는 모바일 앱이 있습니까?
Apr 02, 2025 pm 09:45 PM
XML 구조가 유연하고 다양하기 때문에 모든 XML 파일을 PDF로 변환 할 수있는 앱은 없습니다. XML에서 PDF의 핵심은 데이터 구조를 페이지 레이아웃으로 변환하는 것입니다. XML을 구문 분석하고 PDF를 생성해야합니다. 일반적인 방법으로는 요소 트리와 같은 파이썬 라이브러리를 사용한 XML 및 ReportLab 라이브러리를 사용하여 PDF를 생성하는 XML을 구문 분석합니다. 복잡한 XML의 경우 XSLT 변환 구조를 사용해야 할 수도 있습니다. 성능을 최적화 할 때는 멀티 스레드 또는 멀티 프로세스 사용을 고려하고 적절한 라이브러리를 선택하십시오.
 휴대폰에서 XML을 PDF로 변환 할 때 변환 속도가 빠르나요?
Apr 02, 2025 pm 10:09 PM
휴대폰에서 XML을 PDF로 변환 할 때 변환 속도가 빠르나요?
Apr 02, 2025 pm 10:09 PM
모바일 XML에서 PDF의 속도는 다음 요인에 따라 다릅니다. XML 구조의 복잡성. 모바일 하드웨어 구성 변환 방법 (라이브러리, 알고리즘) 코드 품질 최적화 방법 (효율적인 라이브러리 선택, 알고리즘 최적화, 캐시 데이터 및 다중 스레딩 사용). 전반적으로 절대적인 답변은 없으며 특정 상황에 따라 최적화해야합니다.
 이미지로 변환 된 XML의 크기를 제어하는 방법은 무엇입니까?
Apr 02, 2025 pm 07:24 PM
이미지로 변환 된 XML의 크기를 제어하는 방법은 무엇입니까?
Apr 02, 2025 pm 07:24 PM
XML을 통해 이미지를 생성하려면 XML에서 메타 데이터 (크기, 색상)를 기반으로 이미지를 생성하기 위해 브리지로 그래프 라이브러리 (예 : Pillow 및 JFreeChart)를 사용해야합니다. 이미지의 크기를 제어하는 열쇠는 & lt; width & gt의 값을 조정하는 것입니다. 및 & lt; 높이 & gt; XML의 태그. 그러나 실제 애플리케이션에서 XML 구조의 복잡성, 그래프 드로잉의 편향, 이미지 생성 속도 및 메모리 소비 및 이미지 형식 선택은 모두 생성 된 이미지 크기에 영향을 미칩니다. 따라서 그래픽 라이브러리에 능숙한 XML 구조에 대한 깊은 이해가 필요하고 최적화 알고리즘 및 이미지 형식 선택과 같은 요소를 고려해야합니다.
 권장 XML 서식 도구
Apr 02, 2025 pm 09:03 PM
권장 XML 서식 도구
Apr 02, 2025 pm 09:03 PM
XML 서식 도구는 규칙에 따라 코드를 입력하여 가독성과 이해를 향상시킬 수 있습니다. 도구를 선택할 때는 사용자 정의 기능, 특수 상황 처리, 성능 및 사용 편의성에주의하십시오. 일반적으로 사용되는 도구 유형에는 온라인 도구, IDE 플러그인 및 명령 줄 도구가 포함됩니다.
 XML 형식을 아름답게하는 방법
Apr 02, 2025 pm 09:57 PM
XML 형식을 아름답게하는 방법
Apr 02, 2025 pm 09:57 PM
XML 미화는 합리적인 압입, 라인 브레이크 및 태그 구성을 포함하여 기본적으로 가독성을 향상시키고 있습니다. 원칙은 XML 트리를 가로 지르고 레벨에 따라 들여 쓰기를 추가하고 텍스트가 포함 된 빈 태그와 태그를 처리하는 것입니다. Python의 xml.etree.elementtree 라이브러리는 위의 미화 프로세스를 구현할 수있는 편리한 Pretty_XML () 기능을 제공합니다.
 휴대 전화에서 XML 파일을 PDF로 변환하는 방법은 무엇입니까?
Apr 02, 2025 pm 10:12 PM
휴대 전화에서 XML 파일을 PDF로 변환하는 방법은 무엇입니까?
Apr 02, 2025 pm 10:12 PM
단일 애플리케이션으로 휴대 전화에서 직접 XML에서 PDF 변환을 완료하는 것은 불가능합니다. 두 단계를 통해 달성 할 수있는 클라우드 서비스를 사용해야합니다. 1. 클라우드에서 XML을 PDF로 변환하십시오. 2. 휴대 전화에서 변환 된 PDF 파일에 액세스하거나 다운로드하십시오.
 C 언어 합계의 기능은 무엇입니까?
Apr 03, 2025 pm 02:21 PM
C 언어 합계의 기능은 무엇입니까?
Apr 03, 2025 pm 02:21 PM
C 언어에는 내장 합계 기능이 없으므로 직접 작성해야합니다. 합계는 배열 및 축적 요소를 가로 질러 달성 할 수 있습니다. 루프 버전 : 루프 및 배열 길이를 사용하여 계산됩니다. 포인터 버전 : 포인터를 사용하여 배열 요소를 가리키며 효율적인 합계는 자체 증가 포인터를 통해 달성됩니다. 동적으로 배열 버전을 할당 : 배열을 동적으로 할당하고 메모리를 직접 관리하여 메모리 누출을 방지하기 위해 할당 된 메모리가 해제되도록합니다.
