

Python的Urllib库的基本使用教程

1.分分钟扒一个网页下来
怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它 是一段HTML代码,加 JS、CSS,如果把网页比作一个人,那么HTML便是他的骨架,JS便是他的肌肉,CSS便是它的衣服。所以最重要的部分是存在于HTML中的,下面我 们就写个例子来扒一个网页下来。
import urllib2
response = urllib2.urlopen("http://www.baidu.com")
print response.read()
是的你没看错,真正的程序就两行,把它保存成 demo.py,进入该文件的目录,执行如下命令查看运行结果,感受一下。
python demo.py
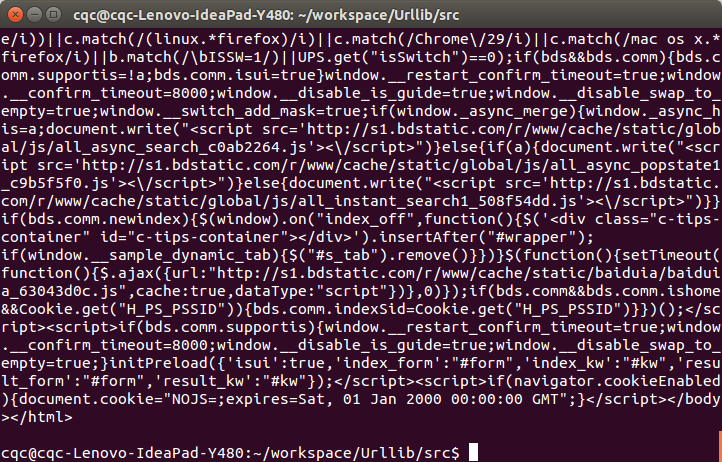
看,这个网页的源码已经被我们扒下来了,是不是很酸爽?
2.分析扒网页的方法
那么我们来分析这两行代码,第一行
response = urllib2.urlopen("http://www.baidu.com")
首先我们调用的是urllib2库里面的urlopen方法,传入一个URL,这个网址是百度首页,协议是HTTP协议,当然你也可以把HTTP换做FTP,FILE,HTTPS 等等,只是代表了一种访问控制协议,urlopen一般接受三个参数,它的参数如下:
urlopen(url, data, timeout)
第一个参数url即为URL,第二个参数data是访问URL时要传送的数据,第三个timeout是设置超时时间。
第二三个参数是可以不传送的,data默认为空None,timeout默认为 socket._GLOBAL_DEFAULT_TIMEOUT
第一个参数URL是必须要传送的,在这个例子里面我们传送了百度的URL,执行urlopen方法之后,返回一个response对象,返回信息便保存在这里面。
print response.read()
response对象有一个read方法,可以返回获取到的网页内容。
如果不加read直接打印会是什么?答案如下:
<addinfourl at 139728495260376 whose fp = <socket._fileobject object at 0x7f1513fb3ad0>>
直接打印出了该对象的描述,所以记得一定要加read方法,否则它不出来内容可就不怪我咯!
3.构造Requset
其实上面的urlopen参数可以传入一个request请求,它其实就是一个Request类的实例,构造时需要传入Url,Data等等的内容。比如上面的两行代码,我们可以这么改写
import urllib2
request = urllib2.Request("http://www.baidu.com")
response = urllib2.urlopen(request)
print response.read()
运行结果是完全一样的,只不过中间多了一个request对象,推荐大家这么写,因为在构建请求时还需要加入好多内容,通过构建一个request,服务器响应请求得到应答,这样显得逻辑上清晰明确。
4.POST和GET数据传送
上面的程序演示了最基本的网页抓取,不过,现在大多数网站都是动态网页,需要你动态地传递参数给它,它做出对应的响应。所以,在访问时,我们需要传递数据给它。最常见的情况是什么?对了,就是登录注册的时候呀。
把数据用户名和密码传送到一个URL,然后你得到服务器处理之后的响应,这个该怎么办?下面让我来为小伙伴们揭晓吧!
数据传送分为POST和GET两种方式,两种方式有什么区别呢?
最重要的区别是GET方式是直接以链接形式访问,链接中包含了所有的参数,当然如果包含了密码的话是一种不安全的选择,不过你可以直观地看到自己提交了什么内容。POST则不会在网址上显示所有的参数,不过如果你想直接查看提交了什么就不太方便了,大家可以酌情选择。
POST方式:
上面我们说了data参数是干嘛的?对了,它就是用在这里的,我们传送的数据就是这个参数data,下面演示一下POST方式。
import urllib
import urllib2
values = {"username":"1016903103@qq.com","password":"XXXX"}
data = urllib.urlencode(values)
url = "https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn"
request = urllib2.Request(url,data)
response = urllib2.urlopen(request)
print response.read()
我们引入了urllib库,现在我们模拟登陆CSDN,当然上述代码可能登陆不进去,因为还要做一些设置头部header的工作,或者还有一些参数 没有设置全,还没有提及到在此就不写上去了,在此只是说明登录的原理。我们需要定义一个字典,名字为values,参数我设置了username和 password,下面利用urllib的urlencode方法将字典编码,命名为data,构建request时传入两个参数,url和data,运 行程序,即可实现登陆,返回的便是登陆后呈现的页面内容。当然你可以自己搭建一个服务器来测试一下。
注意上面字典的定义方式还有一种,下面的写法是等价的
import urllib
import urllib2
values = {}
values['username'] = "1016903103@qq.com"
values['password'] = "XXXX"
data = urllib.urlencode(values)
url = "http://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn"
request = urllib2.Request(url,data)
response = urllib2.urlopen(request)
print response.read()
以上方法便实现了POST方式的传送
GET方式:
至于GET方式我们可以直接把参数写到网址上面,直接构建一个带参数的URL出来即可。
import urllib
import urllib2
values={}
values['username'] = "1016903103@qq.com"
values['password']="XXXX"
data = urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request = urllib2.Request(geturl)
response = urllib2.urlopen(request)
print response.read()
你可以print geturl,打印输出一下url,发现其实就是原来的url加?然后加编码后的参数
http://passport.csdn.net/account/login?username=1016903103%40qq.com&password=XXXX
和我们平常GET访问方式一模一样,这样就实现了数据的GET方式传送。
本节讲解了一些基本使用,可以抓取到一些基本的网页信息,小伙伴们加油!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7529
7529
 15
1378
52
82
11
54
19
21
76
15
1378
52
82
11
54
19
21
76

 PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP와 Python은 고유 한 장점과 단점이 있으며 선택은 프로젝트 요구와 개인 선호도에 달려 있습니다. 1.PHP는 대규모 웹 애플리케이션의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 데이터 과학 및 기계 학습 분야를 지배합니다.
 Centos에서 Pytorch 모델을 훈련시키는 방법
Apr 14, 2025 pm 03:03 PM
Centos에서 Pytorch 모델을 훈련시키는 방법
Apr 14, 2025 pm 03:03 PM
CentOS 시스템에서 Pytorch 모델을 효율적으로 교육하려면 단계가 필요 하며이 기사는 자세한 가이드를 제공합니다. 1. 환경 준비 : 파이썬 및 종속성 설치 : CentOS 시스템은 일반적으로 파이썬을 사전 설치하지만 버전은 더 오래 될 수 있습니다. YUM 또는 DNF를 사용하여 Python 3 및 Upgrade Pip : Sudoyumupdatepython3 (또는 SudodnfupdatePython3), PIP3INSTALL-UPGRADEPIP를 설치하는 것이 좋습니다. CUDA 및 CUDNN (GPU 가속도) : NVIDIAGPU를 사용하는 경우 Cudatool을 설치해야합니다.
 Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
CentOS 시스템에서 Pytorch GPU 가속도를 활성화하려면 Cuda, Cudnn 및 GPU 버전의 Pytorch를 설치해야합니다. 다음 단계는 프로세스를 안내합니다. CUDA 및 CUDNN 설치 CUDA 버전 호환성 결정 : NVIDIA-SMI 명령을 사용하여 NVIDIA 그래픽 카드에서 지원하는 CUDA 버전을보십시오. 예를 들어, MX450 그래픽 카드는 CUDA11.1 이상을 지원할 수 있습니다. Cudatoolkit 다운로드 및 설치 : NVIDIACUDATOOLKIT의 공식 웹 사이트를 방문하여 그래픽 카드에서 지원하는 가장 높은 CUDA 버전에 따라 해당 버전을 다운로드하여 설치하십시오. CUDNN 라이브러리 설치 :
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 02:51 PM
Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 02:51 PM
Centos에서 Pytorch 버전을 선택할 때 다음과 같은 주요 요소를 고려해야합니다. 1. Cuda 버전 호환성 GPU 지원 : NVIDIA GPU가 있고 GPU 가속도를 사용하려면 해당 CUDA 버전을 지원하는 Pytorch를 선택해야합니다. NVIDIA-SMI 명령을 실행하여 지원되는 CUDA 버전을 볼 수 있습니다. CPU 버전 : GPU가 없거나 GPU를 사용하지 않으려면 Pytorch의 CPU 버전을 선택할 수 있습니다. 2. 파이썬 버전 Pytorch
 Centos의 Pytorch로 데이터 전처리를 수행하는 방법
Apr 14, 2025 pm 02:15 PM
Centos의 Pytorch로 데이터 전처리를 수행하는 방법
Apr 14, 2025 pm 02:15 PM
Centos 시스템에서 Pytorch 데이터를 효율적으로 처리하면 다음 단계가 필요합니다. 종속성 설치 : 먼저 시스템을 업데이트하고 Python3 및 PIP를 설치합니다. Sudoyumupdate-ysudoyuminstallpython3-ysudoyuminstallpython3-pip-y는 Centos 버전 및 GPU 모델에 따라 Nvidia 공식 웹 사이트에서 Cudatoolkit 및 Cudnn을 다운로드하고 설치합니다. 가상 환경 구성 (권장) : Conda를 사용하여 새로운 가상 환경을 생성하고 활성화합니다.
 Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos Nginx를 설치하려면 다음 단계를 수행해야합니다. 개발 도구, PCRE-DEVEL 및 OPENSSL-DEVEL과 같은 종속성 설치. nginx 소스 코드 패키지를 다운로드하고 압축을 풀고 컴파일하고 설치하고 설치 경로를/usr/local/nginx로 지정하십시오. nginx 사용자 및 사용자 그룹을 만들고 권한을 설정하십시오. 구성 파일 nginx.conf를 수정하고 청취 포트 및 도메인 이름/IP 주소를 구성하십시오. Nginx 서비스를 시작하십시오. 종속성 문제, 포트 충돌 및 구성 파일 오류와 같은 일반적인 오류는주의를 기울여야합니다. 캐시를 켜고 작업자 프로세스 수 조정과 같은 특정 상황에 따라 성능 최적화를 조정해야합니다.
