

以911新闻为例演示Python实现数据可视化的教程

本文介绍一个将911袭击及后续影响相关新闻文章的主题可视化的项目。我将介绍我的出发点,实现的技术细节和我对一些结果的思考。
简介
近代美国历史上再没有比911袭击影响更深远的事件了,它的影响在未来还会持续。从事件发生到现在,成千上万主题各异的文章付梓。我们怎样能利用数据科学的工具来探索这些主题,并且追踪它们随着时间的变化呢?
灵感
首先提出这个问题的是一家叫做Local Projects的公司,有人委任它们为纽约的国家911博物馆设置一个展览。他们的展览,Timescape,将事件的主题和文章可视化之后投影到博物馆的一面墙上。不幸的是,由于考虑到官僚主义的干预和现代人的三分钟热度,这个展览只能展现很多主题,快速循环播放。Timescape的设计给了我启发,但是我想试着更深入、更有交互性,让每个能接入互联网的人都能在空闲时观看。
这个问题的关键是怎么讲故事。每篇文章都有不同的讲故事角度,但是有线索通过词句将它们联系到一起。”Osama bin Laden”、 “Guantanamo Bay”、”Freedom”,还有更多词汇组成了我模型的砖瓦。
获取数据
所有来源当中,没有一个比纽约时报更适合讲述911的故事了。他们还有一个神奇的API,允许在数据库中查询关于某一主题的全部文章。我用这个API和其他一些Python网络爬虫以及NLP工具构建了我的数据集。
爬取过程是如下这样的:
- 调用API查询新闻的元数据,包括每篇文章的URL。
- 给每个URL发送GET请求,找到HTML中的正文文本,提取出来。
- 清理文章文本,去除停用词和标点
我写了一个Python脚本自动做这些事,并能够构建一个有成千上万文章的数据集。也许这个过程中最有挑战性的部分是写一个从HTML文档里提取正文的函数。近几十年来,纽约时报不时也更改了他们HTML文档的结构,所以这个抽取函数取决于笨重的嵌套条件语句:
# s is a BeautifulSoup object containing the HTML of the page
if s.find('p', {'itemprop': 'articleBody'}) is not None:
paragraphs = s.findAll('p', {'itemprop': 'articleBody'})
story = ' '.join([p.text for p in paragraphs])
elif s.find('nyt_text'):
story = s.find('nyt_text').text
elif s.find('div', {'id': 'mod-a-body-first-para'}):
story = s.find('div', {'id': 'mod-a-body-first-para'}).text
story += s.find('div', {'id': 'mod-a-body-after-first-para'}).text
else:
if s.find('p', {'class': 'story-body-text'}) is not None:
paragraphs = s.findAll('p', {'class': 'story-body-text'})
story = ' '.join([p.text for p in paragraphs])
else:
story = ''
文档向量化
在我们应用机器学习算法之前,我们要将文档向量化。感谢scikit-learn的IT-IDF Vectorizer模块,这很容易。只考虑单个词是不够的,因为我的数据集里并不缺一些重要的名字。所以我选择使用n-grams,n取了1到3。让人高兴的是,实现多个n-gram和实现单独关键词一样简单,只需要简单地设置一下Vectorizer的参数。
vec = TfidfVectorizer(max_features=max_features,
ngram_range=(1, 3),
max_df=max_df)
开始的模型里,我设置max_features(向量模型里词或词组的最大数量)参数为20000或30000,在我计算机的计算能力之内。但是考虑到我还加入了2-gram和3-gram,这些组合会导致特征数量的爆炸(这里面很多特征也很重要),在我的最终模型里我会提高这个数字。
用NMF做主题模型
非负矩阵分解(Non-negative Matrix Factorization,或者叫NMF),是一个线性代数优化算法。它最具魔力的地方在于不用任何阐释含义的先验知识,它就能提取出关于主题的有意义的信息。数学上它的目标是将一个nxm的输入矩阵分解成两个矩阵,称为W和H,W是nxt的文档-主题矩阵,H是txm的主题-词语矩阵。你可以发现W和H的点积与输入矩阵形状一样。实际上,模型试图构建W和H,使得他们的点积是输入矩阵的一个近似。这个算法的另一个优点在于,用户可以自主选择变量t的值,代表生成主题的数量。
再一次地,我把这个重要的任务交给了scikit-learn,它的NMF模块足够处理这个任务。如果我在这个项目上投入更多时间,我也许会找一些更高效的NMF实现方法,毕竟它是这个项目里最复杂耗时的过程。实现过程中我产生了一个主意,但没实现它,是一个热启动的问题。那样可以让用户用一些特定的词来填充H矩阵的行,从而在形成主题的过程中给系统一些领域知识。不管怎么样,我只有几周时间完成整个项目。还有很多其他的事需要我更多的精力。
主题模型的参数
因为主题模型是整个项目的基石,我在构建过程中做的决定对最终成果有很大影响。我决定输入模型的文章为911事件发生18个月以后的。在这个时间段喧嚣不再,所以这段时间出现的主题的确是911事件的直接结果。在向量化的阶段,开始几次运行的规模受限于我的计算机。20或者30个主题的结果还不错,但是我想要包含更多结果的更大模型。
我最终的模型使用了100000个向量词汇和大约15000篇文章。我设置了200个主题,所以NMF算法需要处理15000×100000, 15000×200和200×100000规模的矩阵。逐渐变换后两个矩阵来拟合第一个矩阵。
完成模型
最终模型矩阵完成之后,我查看每个主题并检查关键词(那些在主题-词语矩阵里有最高概率值的)。我给每个主题一个特定的名字(在可视化当中可以用),并决定是否保留这个主题。一些主题由于和中心话题无关被删除了(例如本地体育);还有一些太宽泛(关于股票市场或者政治的主题);还有一些太特定了,很可能是NMF算法的误差(一系列来源于同一篇文章中的有关联的3-grams)
这个过程之后我有了75个明确和相关的主题,每个都根据内容进行命名了。
分析
主题模型训练好之后,算出给定文章的不同主题的权重就很容易了:
- 使用存储的TF-IDF模型将文章文本向量化。
- 算出这个向量和精简过的NMF主题-词语矩阵的点积。(1x100k * 100k x 75 = 1 x 75 )
- 结果向量的75个维度表示这篇文章和75个主题有多相关。
更难的部分在于决定怎么把这些权重变成一个能讲故事的可视化的形式。如果我只是简单地将一段时期全部文章的话题权重加起来,这个分布应该是一个关于那段时间中每个主题出现频率的准确表达。但是,这个分布的组成部分对人类来说毫无意义。换种方式想,如果我对每个主题做一个二分分类,我就能算出一段时间内和一个主题相关的文章百分数。我选择了这个方法因为它更能说明问题。
话题二分分类也有难度,尤其是这么多文章和话题的情况下。一些文章在很多主题下都有更高的权重,因为他们比较长并且包含的关键词出现在不同主题里。其他一些文章在大多主题下权重都很低,即使人工判断都能发现它的确和某些主题相关。这些差别决定了固定权重阈值不是一个好的分类方法;一些文章属于很多主题而一些文章不属于任何主题。我决定将每篇文章分类到权重最高的三个主题下。尽管这个方法不完美,它还是能提供一个很好的平衡来解决我们主题模型的一些问题。
可视化
尽管数据获取,主题模型和分析阶段对这个项目都很重要,它们都是为最终可视化服务的。我努力平衡视觉吸引力和用户交互,让用户可以不需指导地探索和理解主题的趋势。我开始的图使用的是堆叠的区块,后来我意识到简单的线画出来就足够和清晰了。
我使用d3.js来做可视化,它对本项目数据驱动的模式来说正合适。数据本身被传到了网页上,通过一个包含主题趋势数据的CSV文件和两个包含主题和文章元数据的JSON文件。尽管我不是前端开发的专家,我还是成功地通过一周的课程学习了足够的d3,html和css知识,来构建一个令人满意的可视化页面。
一些有趣的主题
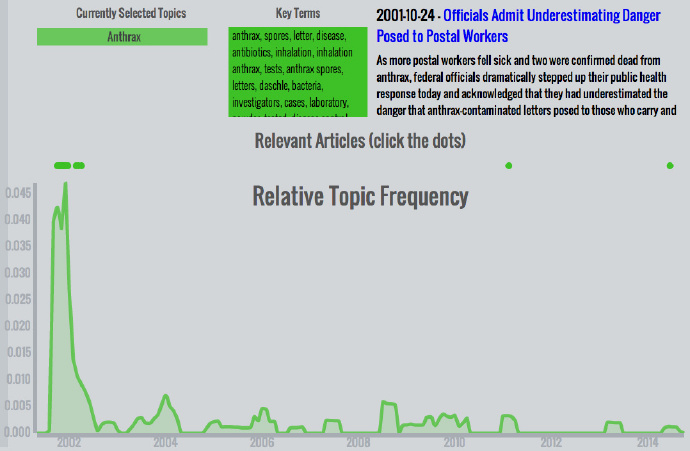
炭疽热 – 911以后,恐慌情绪笼罩全国。幸运的是,大部分恐慌都是多虑了。2001年晚期的炭疽热恐慌是一个没有什么后续影响的孤立事件,如图中清晰可见。
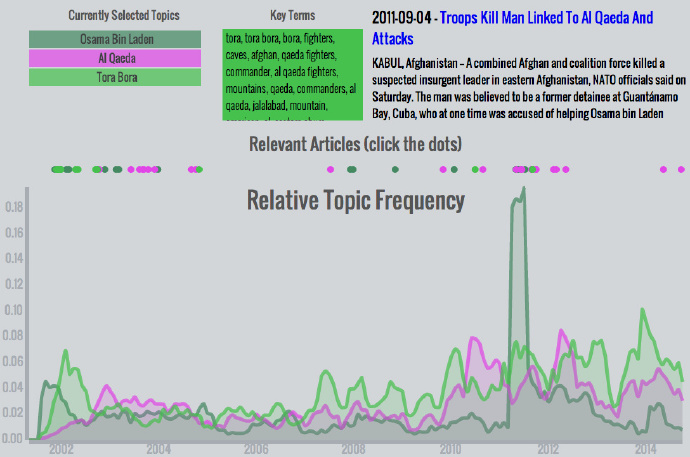
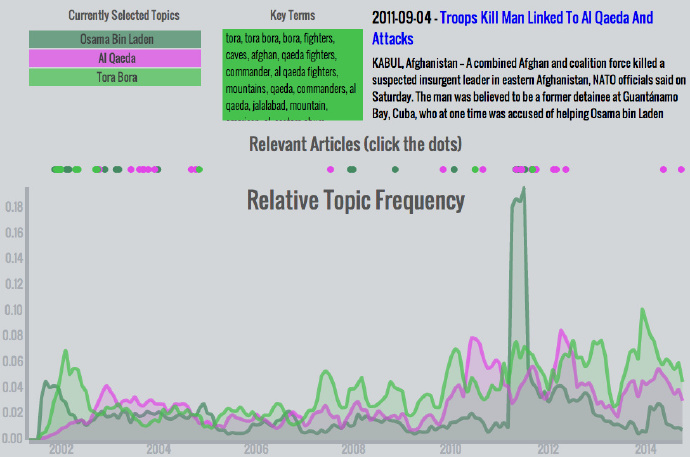
奥萨玛本拉登,基地组织,托拉博拉 – 所有主题中关注的峰值发生在本拉登2011年在阿伯塔巴德被打死之后。这个话题组合值得注意,因为它展现了911事件后媒体关注的演进:最开始,本拉登获得了很多关注。不久后,托拉博拉话题变得突出,因为托拉博拉是疑似本拉登的藏身地点和美军的关注重点。当本拉登逃脱了追捕,这两个话题的关注下降,而更宽泛的基地组织话题有些提升。近几年每个话题的逐渐提升说明了它们的关联性。尽管没有显著提升,它们相对的关注度还是在其他话题安静时有所提升。
我学到了什么
尽管我提出这个项目的时候就对主题模型和数据处理中的各个组分有了解,这个项目的真正意义在于它(再次)讲出的故事。911事件的本质是消极的,但是也有许多积极的故事:许多英雄救了很多人,社区融合,以及重建。
不幸的是,在我主题模型中展现出来这样的媒体环境:关注负能量、反派和破坏。当然,单独的一些英雄在一两篇文章中被赞扬了,但是没有一个足够广来形成一个主题。另一方面,像奥萨玛·本拉登和卡利亚·穆萨维这样的反派在很多文章中被提及。即使是理查德·里德,一个笨手笨脚的(试图)穿*鞋炸飞机的人,都比一些成功的英雄有更持久的媒体影响(一个补充:注重词汇的主题模型的一个缺点就是,像Reid这样普通的名字会导致谈论不同人物的文章被聚集到一起。在这个例子里,哈利·里德和理查德·里德)。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7563
7563
 15
1385
52
84
11
61
19
28
99
15
1385
52
84
11
61
19
28
99

 PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP와 Python은 고유 한 장점과 단점이 있으며 선택은 프로젝트 요구와 개인 선호도에 달려 있습니다. 1.PHP는 대규모 웹 애플리케이션의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 데이터 과학 및 기계 학습 분야를 지배합니다.
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
 파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬은 자동화, 스크립팅 및 작업 관리가 탁월합니다. 1) 자동화 : 파일 백업은 OS 및 Shutil과 같은 표준 라이브러리를 통해 실현됩니다. 2) 스크립트 쓰기 : PSUTIL 라이브러리를 사용하여 시스템 리소스를 모니터링합니다. 3) 작업 관리 : 일정 라이브러리를 사용하여 작업을 예약하십시오. Python의 사용 편의성과 풍부한 라이브러리 지원으로 인해 이러한 영역에서 선호하는 도구가됩니다.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 VScode 란 무엇입니까?
Apr 15, 2025 pm 06:45 PM
VScode 란 무엇입니까?
Apr 15, 2025 pm 06:45 PM
VS Code는 Full Name Visual Studio Code로, Microsoft가 개발 한 무료 및 오픈 소스 크로스 플랫폼 코드 편집기 및 개발 환경입니다. 광범위한 프로그래밍 언어를 지원하고 구문 강조 표시, 코드 자동 완료, 코드 스 니펫 및 스마트 프롬프트를 제공하여 개발 효율성을 향상시킵니다. 풍부한 확장 생태계를 통해 사용자는 디버거, 코드 서식 도구 및 GIT 통합과 같은 특정 요구 및 언어에 확장을 추가 할 수 있습니다. VS 코드에는 코드에서 버그를 신속하게 찾아서 해결하는 데 도움이되는 직관적 인 디버거도 포함되어 있습니다.
 Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos Nginx를 설치하려면 다음 단계를 수행해야합니다. 개발 도구, PCRE-DEVEL 및 OPENSSL-DEVEL과 같은 종속성 설치. nginx 소스 코드 패키지를 다운로드하고 압축을 풀고 컴파일하고 설치하고 설치 경로를/usr/local/nginx로 지정하십시오. nginx 사용자 및 사용자 그룹을 만들고 권한을 설정하십시오. 구성 파일 nginx.conf를 수정하고 청취 포트 및 도메인 이름/IP 주소를 구성하십시오. Nginx 서비스를 시작하십시오. 종속성 문제, 포트 충돌 및 구성 파일 오류와 같은 일반적인 오류는주의를 기울여야합니다. 캐시를 켜고 작업자 프로세스 수 조정과 같은 특정 상황에 따라 성능 최적화를 조정해야합니다.
