

基于Python实现的百度贴吧网络爬虫实例

本文实例讲述了基于Python实现的百度贴吧网络爬虫。分享给大家供大家参考。具体如下:
完整实例代码点击此处本站下载。
项目内容:
用Python写的百度贴吧的网络爬虫。
使用方法:
新建一个BugBaidu.py文件,然后将代码复制到里面后,双击运行。
程序功能:
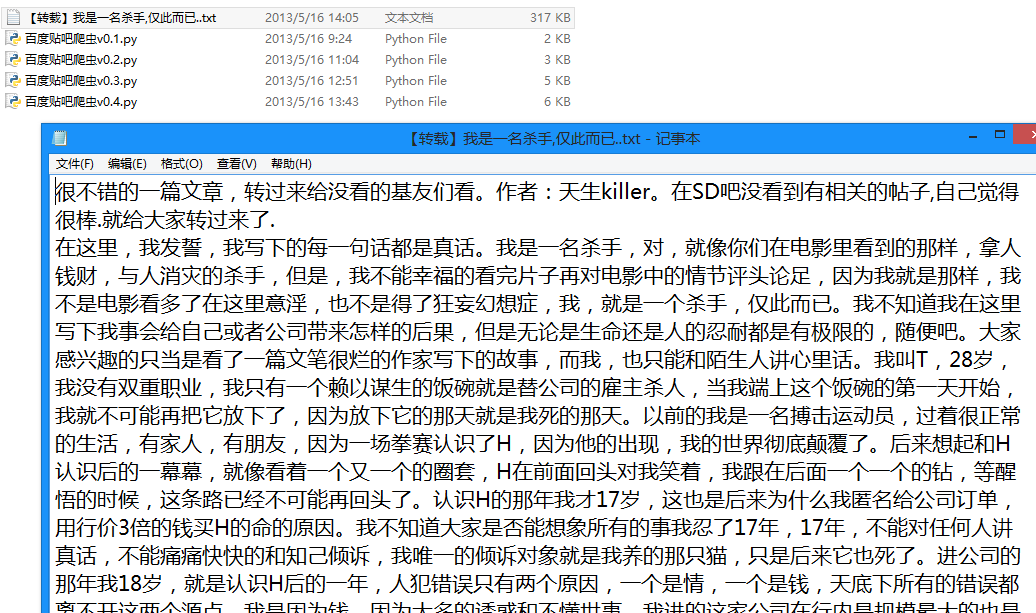
将贴吧中楼主发布的内容打包txt存储到本地。
原理解释:
首先,先浏览一下某一条贴吧,点击只看楼主并点击第二页之后url发生了一点变化,变成了:
http://tieba.baidu.com/p/2296712428?see_lz=1&pn=1
可以看出来,see_lz=1是只看楼主,pn=1是对应的页码,记住这一点为以后的编写做准备。
这就是我们需要利用的url。
接下来就是查看页面源码。
首先把题目抠出来存储文件的时候会用到。
可以看到百度使用gbk编码,标题使用h1标记:
【原创】时尚首席(关于时尚,名利,事业,爱情,励志)
同样,正文部分用div和class综合标记,接下来要做的只是用正则表达式来匹配即可。
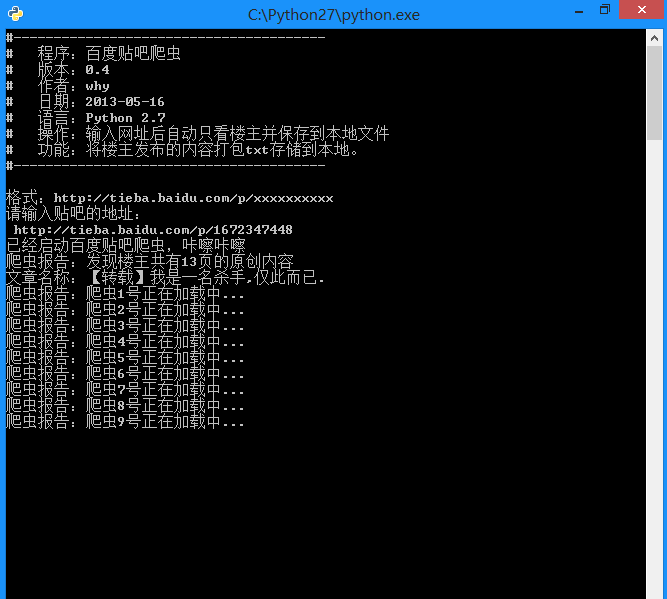
运行截图:
生成的txt文件:
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:百度贴吧爬虫
# 版本:0.5
# 作者:why
# 日期:2013-05-16
# 语言:Python 2.7
# 操作:输入网址后自动只看楼主并保存到本地文件
# 功能:将楼主发布的内容打包txt存储到本地。
#---------------------------------------
import string
import urllib2
import re
#----------- 处理页面上的各种标签 -----------
class HTML_Tool:
# 用非 贪婪模式 匹配 \t 或者 \n 或者 空格 或者 超链接 或者 图片
BgnCharToNoneRex = re.compile("(\t|\n| |<a.*?>|<img .*? alt="基于Python实现的百度贴吧网络爬虫实例" >)")
# 用非 贪婪模式 匹配 任意<>标签
EndCharToNoneRex = re.compile("<.*?>")
# 用非 贪婪模式 匹配 任意<p>标签
BgnPartRex = re.compile("<p.*?>")
CharToNewLineRex = re.compile("(<br/>|</p>|<tr>|<div>|</div>)")
CharToNextTabRex = re.compile("<td>")
# 将一些html的符号实体转变为原始符号
replaceTab = [("<","<"),(">",">"),("&","&"),("&","\""),(" "," ")]
def Replace_Char(self,x):
x = self.BgnCharToNoneRex.sub("",x)
x = self.BgnPartRex.sub("\n ",x)
x = self.CharToNewLineRex.sub("\n",x)
x = self.CharToNextTabRex.sub("\t",x)
x = self.EndCharToNoneRex.sub("",x)
for t in self.replaceTab:
x = x.replace(t[0],t[1])
return x
class Baidu_Spider:
# 申明相关的属性
def __init__(self,url):
self.myUrl = url + '?see_lz=1'
self.datas = []
self.myTool = HTML_Tool()
print u'已经启动百度贴吧爬虫,咔嚓咔嚓'
# 初始化加载页面并将其转码储存
def baidu_tieba(self):
# 读取页面的原始信息并将其从gbk转码
myPage = urllib2.urlopen(self.myUrl).read().decode("gbk")
# 计算楼主发布内容一共有多少页
endPage = self.page_counter(myPage)
# 获取该帖的标题
title = self.find_title(myPage)
print u'文章名称:' + title
# 获取最终的数据
self.save_data(self.myUrl,title,endPage)
#用来计算一共有多少页
def page_counter(self,myPage):
# 匹配 "共有<span class="red">12</span>页" 来获取一共有多少页
myMatch = re.search(r'class="red">(\d+?)</span>', myPage, re.S)
if myMatch:
endPage = int(myMatch.group(1))
print u'爬虫报告:发现楼主共有%d页的原创内容' % endPage
else:
endPage = 0
print u'爬虫报告:无法计算楼主发布内容有多少页!'
return endPage
# 用来寻找该帖的标题
def find_title(self,myPage):
# 匹配 <h1 id="xxxxxxxxxx">xxxxxxxxxx</h1> 找出标题
myMatch = re.search(r'<h1 id="">(.*?)</h1>', myPage, re.S)
title = u'暂无标题'
if myMatch:
title = myMatch.group(1)
else:
print u'爬虫报告:无法加载文章标题!'
# 文件名不能包含以下字符: \ / : * ? " < > |
title = title.replace('\\','').replace('/','').replace(':','').replace('*','').replace('?','').replace('"','').replace('>','').replace('<','').replace('|','')
return title
# 用来存储楼主发布的内容
def save_data(self,url,title,endPage):
# 加载页面数据到数组中
self.get_data(url,endPage)
# 打开本地文件
f = open(title+'.txt','w+')
f.writelines(self.datas)
f.close()
print u'爬虫报告:文件已下载到本地并打包成txt文件'
print u'请按任意键退出...'
raw_input();
# 获取页面源码并将其存储到数组中
def get_data(self,url,endPage):
url = url + '&pn='
for i in range(1,endPage+1):
print u'爬虫报告:爬虫%d号正在加载中...' % i
myPage = urllib2.urlopen(url + str(i)).read()
# 将myPage中的html代码处理并存储到datas里面
self.deal_data(myPage.decode('gbk'))
# 将内容从页面代码中抠出来
def deal_data(self,myPage):
myItems = re.findall('id="post_content.*?>(.*?)</div>',myPage,re.S)
for item in myItems:
data = self.myTool.Replace_Char(item.replace("\n","").encode('gbk'))
self.datas.append(data+'\n')
#-------- 程序入口处 ------------------
print u"""#---------------------------------------
# 程序:百度贴吧爬虫
# 版本:0.5
# 作者:why
# 日期:2013-05-16
# 语言:Python 2.7
# 操作:输入网址后自动只看楼主并保存到本地文件
# 功能:将楼主发布的内容打包txt存储到本地。
#---------------------------------------
"""
# 以某小说贴吧为例子
# bdurl = 'http://tieba.baidu.com/p/2296712428?see_lz=1&pn=1'
print u'请输入贴吧的地址最后的数字串:'
bdurl = 'http://tieba.baidu.com/p/' + str(raw_input(u'http://tieba.baidu.com/p/'))
#调用
mySpider = Baidu_Spider(bdurl)
mySpider.baidu_tieba()希望本文所述对大家的Python程序设计有所帮助。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7471
7471
 15
1377
52
77
11
48
19
19
30
15
1377
52
77
11
48
19
19
30

 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
MySQL 설치 실패의 주된 이유는 다음과 같습니다. 1. 권한 문제, 관리자로 실행하거나 Sudo 명령을 사용해야합니다. 2. 종속성이 누락되었으며 관련 개발 패키지를 설치해야합니다. 3. 포트 충돌, 포트 3306을 차지하는 프로그램을 닫거나 구성 파일을 수정해야합니다. 4. 설치 패키지가 손상되어 무결성을 다운로드하여 확인해야합니다. 5. 환경 변수가 잘못 구성되었으며 운영 체제에 따라 환경 변수를 올바르게 구성해야합니다. 이러한 문제를 해결하고 각 단계를 신중하게 확인하여 MySQL을 성공적으로 설치하십시오.
 MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일은 손상되었습니다. 어떻게해야합니까? 아아, mySQL을 다운로드하면 파일 손상을 만날 수 있습니다. 요즘 정말 쉽지 않습니다! 이 기사는 모든 사람이 우회를 피할 수 있도록이 문제를 해결하는 방법에 대해 이야기합니다. 읽은 후 손상된 MySQL 설치 패키지를 복구 할 수있을뿐만 아니라 향후에 갇히지 않도록 다운로드 및 설치 프로세스에 대해 더 깊이 이해할 수 있습니다. 파일 다운로드가 손상된 이유에 대해 먼저 이야기합시다. 이에 대한 많은 이유가 있습니다. 네트워크 문제는 범인입니다. 네트워크의 다운로드 프로세스 및 불안정성의 중단으로 인해 파일 손상이 발생할 수 있습니다. 다운로드 소스 자체에도 문제가 있습니다. 서버 파일 자체가 고장 났으며 물론 다운로드하면 고장됩니다. 또한 일부 안티 바이러스 소프트웨어의 과도한 "열정적 인"스캔으로 인해 파일 손상이 발생할 수 있습니다. 진단 문제 : 파일이 실제로 손상되었는지 확인하십시오
 MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 기본 데이터 저장 및 관리를위한 네트워크 연결없이 실행할 수 있습니다. 그러나 다른 시스템과의 상호 작용, 원격 액세스 또는 복제 및 클러스터링과 같은 고급 기능을 사용하려면 네트워크 연결이 필요합니다. 또한 보안 측정 (예 : 방화벽), 성능 최적화 (올바른 네트워크 연결 선택) 및 데이터 백업은 인터넷에 연결하는 데 중요합니다.
 MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 성능 최적화는 설치 구성, 인덱싱 및 쿼리 최적화, 모니터링 및 튜닝의 세 가지 측면에서 시작해야합니다. 1. 설치 후 innodb_buffer_pool_size 매개 변수와 같은 서버 구성에 따라 my.cnf 파일을 조정해야합니다. 2. 과도한 인덱스를 피하기 위해 적절한 색인을 작성하고 Execution 명령을 사용하여 실행 계획을 분석하는 것과 같은 쿼리 문을 최적화합니다. 3. MySQL의 자체 모니터링 도구 (showprocesslist, showstatus)를 사용하여 데이터베이스 건강을 모니터링하고 정기적으로 백업 및 데이터베이스를 구성하십시오. 이러한 단계를 지속적으로 최적화함으로써 MySQL 데이터베이스의 성능을 향상시킬 수 있습니다.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL이 시작을 거부 했습니까? 당황하지 말고 확인합시다! 많은 친구들이 MySQL을 설치 한 후 서비스를 시작할 수 없다는 것을 알았으며 너무 불안했습니다! 걱정하지 마십시오.이 기사는 침착하게 다루고 그 뒤에있는 마스터 마인드를 찾을 수 있습니다! 그것을 읽은 후에는이 문제를 해결할뿐만 아니라 MySQL 서비스에 대한 이해와 문제 해결 문제에 대한 아이디어를 향상시키고보다 강력한 데이터베이스 관리자가 될 수 있습니다! MySQL 서비스는 시작되지 않았으며 간단한 구성 오류에서 복잡한 시스템 문제에 이르기까지 여러 가지 이유가 있습니다. 가장 일반적인 측면부터 시작하겠습니다. 기본 지식 : 서비스 시작 프로세스 MySQL 서비스 시작에 대한 간단한 설명. 간단히 말해서 운영 체제는 MySQL 관련 파일을로드 한 다음 MySQL 데몬을 시작합니다. 여기에는 구성이 포함됩니다
