

使用python开发vim插件及心得分享

vim有各种强大的插件,这不仅归功于其提供的用来编写插件的脚本语言vimL,还得益于它良好的接口实现,从而支持python等语言编写插件。当vim编译时带有+python特性时就能使用python2.x编写插件,+python3则支持python3.x,可以使用vim --version来查看vim的编译特性。
要使用python接口,可以用:h python来查看vim提供的帮助文档,本文做一个简单的介绍。我们都知道在vim里可以执行bash命令,只需要:!command即可,那么vim里可以执行python语句吗?当然可以了,vim那么强大!不是吗,是吗?!
vim中执行python命令
在vim中可以使用py[thon] {stmt}来执行python语句{stmt},你可以用:python print "Hello World!"来验证一下。
只能执行一条语句,没什么用,不是吗?所以有更加强大的接口,语法如下:
py[thon] {script}
{endmarker}
这样我们就可以执行python脚本{script}中的内容了。{endmarker}是一个标记符号,可以是任何内容,不过{endmarker}后面不能有任何的空白字符。看一个简单的例子,假设下面代码保存为script_demo.vim:
<code>function! Foo()<br>python class Foo_demo:<br> def __init__(self):<br> print 'Foo_demo init'<br>Foo_demo()<br>EOF<br>endfunction</code>
那么在vim中我们先用:source path_to_script/script_demo.vim来加载脚本,然后就可以用:call Foo()来运行python脚本了,整个过程如图所示:
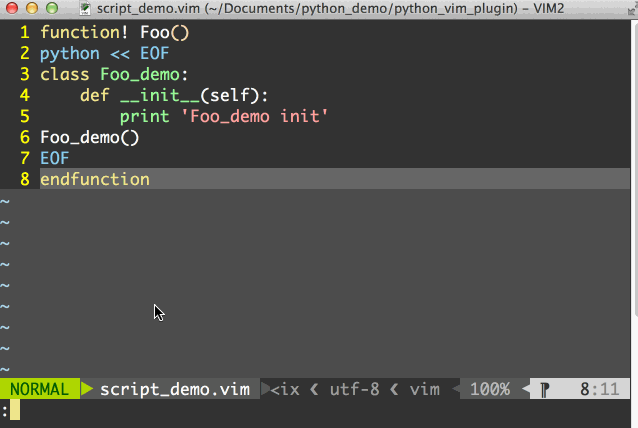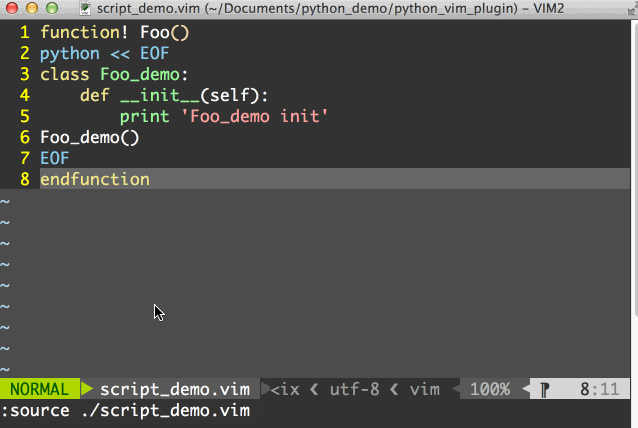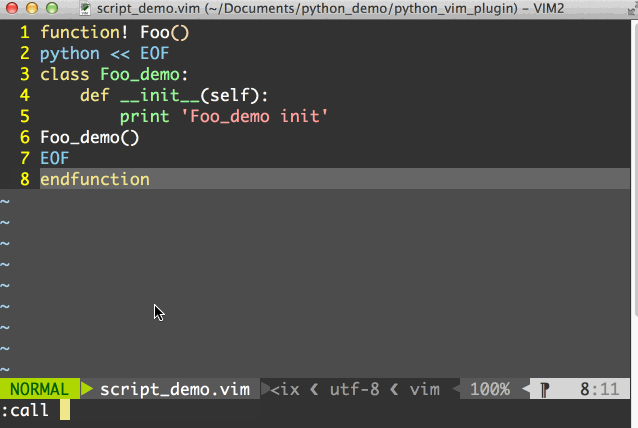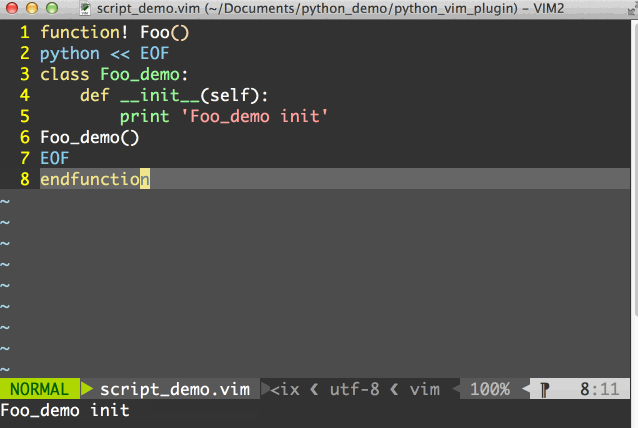
此外,我们还可以将python脚本放到一个单独的.py文件中,然后用pyf[ile] {file}来运行python文件中的程序,要注意这里pyf[ile]后面的所有参数被看做是一个文件的名字。
vim模块
我们已经可以在vim中执行python命令了,但是python怎么获取vim中的一些信息呢?比如说我想知道vim当前缓冲区一共有多少行内容,然后获取最后一行的内容,用python该怎么做呢?
于是vim提供了一个python模块,有趣的是模块名字就叫做vim,我们可以用它来获取vim编辑器里面的所有信息。上面问题用以下python脚本就可以解决了:
<code>function! Bar()<br>python import vim<br>cur_buf = vim.current.buffer<br>print "Lines: {0}".format(len(cur_buf))<br>print "Contents: {0}".format(cur_buf[-1])<br>EOF<br>endfunction</code>你可以自己加载脚本运行一下见证奇迹!上面代码出现了vim.current.buffer,想必你已经从名字猜到了它的意思了,不过还是来详细看下吧:
vim模块中的常量
vim.buffers: 用来访问vim中缓冲区的列表对象,可以进行如下操作:
<code>:py b = vim.buffers[i] # Indexing (read-only)<br>:py b in vim.buffers # Membership test<br>:py n = len(vim.buffers) # Number of elements<br>:py for b in vim.buffers: # Iterating over buffer list</code>
vim.windows: 用来访问vim中窗口的列表对象,和vim.buffers支持的操作基本相。
vim.current: 用来访问vim中当前位置的各种信息,比如:
vim.current.line
vim.current.buffer
vim.current.window
vim.current.tabpage
vim.current.range
vim.vvars: 类似字典的对象,用来存储global(g:)变量或者vim(v:)变量。
还有其他的一些常量,这里不做叙述。注意这里的常量并不是真正意义上的常量,你可以重新给他们赋值。但是我们应该避免这样做,因为这样会丢失该常量引用的值。现在为止我们已经能获取vim中数据,然后用python来对其进行操作,似乎完美了。
不过vim并没有止步于此,它可是Stronger than Stronger!因为我们可以在python里使用vim强大的命令集,这样就可以用python写一些常用的批处理插件,看下面简单的例子:
<code>function! Del(number)<br>python import vim<br>num = vim.eval("a:number")<br>vim.command("normal gg{0}dd".format(num))<br>vim.command("w")<br>EOF<br>endfunction</code>可以调用上面函数Del(n)用来删除当前缓冲区前n行的内容(只是示例而已,现实中别这么做!)上面用到了eval和command函数,如下:
vim模块中两个主要的方法
vim.command(str): 执行vim中的命令str(ex-mode,命令模式下的命令),返回值为None,比如:
<code>:py vim.command("%s/aaa/bbb/g")</code>也可以用vim.command("normal "+str)来执行normal模式下的命令,比如说用以下命令删除当前行的内容:
<code>:py vim.command("normal "+'dd')</code>vim.eval(str): 用vim内部的解释器来计算str中的内容,返回值可以是字符串、字典、或者列表,比如计算12+12的值:
<code>:py print vim.eval("12+12")</code>将返回结算结果24。
前面的Del函数还提供了一个number参数,在vimL里面可以通过let arg=a:number来使用,在python中通过vim.eval("a:number")来使用。也可以通过参数位置来访问,比如let arg=a:0或者是vim.eval("a:0")。我们可以使用"..."来代替命名参数来定义一个能接收任意数量参数的函数,不过这样只能通过位置来访问。
vim模块还提供了一个异常处理对象vim.error,使用vim模块时一旦出现错误,将会触发一个vim.error异常,简单的例子如下:
<code>try:<br> vim.command("put a")<br>except vim.error:<br> # nothing in register a</code>vim模块提供的对象
到这里你基本能用python来对缓冲区进行基本的操作,比如删除行或者是在指定行添加内容等。不过在缓冲区添加内容会很不pythoner,因为你得使用command来调用vim的i/I/a/A命令。好在有更科学的方式,那就是利用vim模块提供的对象来进行操作,看下面简单的例子:
<code>function! Append()<br>python import vim<br>cur_buf = vim.current.buffer<br>lens = len(cur_buf)<br>cur_buf.append('" Demo', lens)<br>EOF<br>endfunction</code>Append函数在当前缓冲区的结尾添加注释内容" Demo,缓冲区对象是怎么一会儿事呢?
缓冲区对象
vim模块提供了缓冲区对象来让我们对缓冲区进行操作,该对象有两个只读属性name和number,name为当前缓冲区文件的名称(包含绝对路径),number为缓冲区的数量。还有一个bool属性valid,用来标识相关缓冲区是否被擦除。
缓冲区对象有以下几种方法:
b.append(str): 在当前行的下面插入新的行,内容为str;b.append(str, n): 在第n行的下面插入新的行,内容为str;b.append(list)
b.append(list, n): 插入多行到缓冲区中;b.range(s,e): 返回一个range对象表示缓冲区中s到e行的内容。
注意使用append添加新行str时,str中一定不能包含换行符"\n"。str结尾可以有"\n",但会被忽略掉。
缓冲区对象的range方法会返回一个range对象来代表部分的缓冲区内容,那么range对象又有那些属性以及方法呢? 其实在操作上range对象和缓冲区对象基本相同,除了range对象的操作均是在指定的区域上。range对象有两个属性start和end,分别是range对象的起始和结尾行。它的方法有r.append(str),r.append(str, n)和r.append(list),r.append(list, n)。
我们可以通过vim.windows来获取vim中的窗口对象,我们只能通过窗口对象的属性来对其进行操作,因为它没有提供方法或者其他接口来操作。其中只读属性有buffer、number、tabpage等,读写属性有cursor、height、width、valid等。具体可以查看帮助:h python-window

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7465
7465
 15
1376
52
77
11
45
19
18
19
15
1376
52
77
11
45
19
18
19

 PS 페더 링은 어떻게 전환의 부드러움을 제어합니까?
Apr 06, 2025 pm 07:33 PM
PS 페더 링은 어떻게 전환의 부드러움을 제어합니까?
Apr 06, 2025 pm 07:33 PM
깃털 통제의 열쇠는 점진적인 성격을 이해하는 것입니다. PS 자체는 그라디언트 곡선을 직접 제어하는 옵션을 제공하지 않지만 여러 깃털, 일치하는 마스크 및 미세 선택으로 반경 및 구배 소프트를 유연하게 조정하여 자연스럽게 전이 효과를 달성 할 수 있습니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 PS 페더 링을 설정하는 방법?
Apr 06, 2025 pm 07:36 PM
PS 페더 링을 설정하는 방법?
Apr 06, 2025 pm 07:36 PM
PS 페더 링은 이미지 가장자리 블러 효과로, 가장자리 영역에서 픽셀의 가중 평균에 의해 달성됩니다. 깃털 반경을 설정하면 흐림 정도를 제어 할 수 있으며 값이 클수록 흐려집니다. 반경을 유연하게 조정하면 이미지와 요구에 따라 효과를 최적화 할 수 있습니다. 예를 들어, 캐릭터 사진을 처리 할 때 더 작은 반경을 사용하여 세부 사항을 유지하고 더 큰 반경을 사용하여 예술을 처리 할 때 흐릿한 느낌을줍니다. 그러나 반경이 너무 커서 가장자리 세부 사항을 쉽게 잃을 수 있으며 너무 작아 효과는 분명하지 않습니다. 깃털 효과는 이미지 해상도의 영향을받으며 이미지 이해 및 효과 파악에 따라 조정해야합니다.
 PS 깃털은 이미지 품질에 어떤 영향을 미칩니 까?
Apr 06, 2025 pm 07:21 PM
PS 깃털은 이미지 품질에 어떤 영향을 미칩니 까?
Apr 06, 2025 pm 07:21 PM
PS 페더 링은 이미지 세부 사항 손실, 색상 포화 감소 및 노이즈 증가로 이어질 수 있습니다. 충격을 줄이려면 더 작은 깃털 반경을 사용하고 레이어를 복사 한 다음 깃털을 복사 한 다음 깃털 전후에 이미지 품질을 조심스럽게 비교하는 것이 좋습니다. 또한 깃털이 모든 경우에 적합하지는 않으며 때로는 마스크와 같은 도구가 이미지 가장자리를 처리하는 데 더 적합합니다.
 MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 성능 최적화는 설치 구성, 인덱싱 및 쿼리 최적화, 모니터링 및 튜닝의 세 가지 측면에서 시작해야합니다. 1. 설치 후 innodb_buffer_pool_size 매개 변수와 같은 서버 구성에 따라 my.cnf 파일을 조정해야합니다. 2. 과도한 인덱스를 피하기 위해 적절한 색인을 작성하고 Execution 명령을 사용하여 실행 계획을 분석하는 것과 같은 쿼리 문을 최적화합니다. 3. MySQL의 자체 모니터링 도구 (showprocesslist, showstatus)를 사용하여 데이터베이스 건강을 모니터링하고 정기적으로 백업 및 데이터베이스를 구성하십시오. 이러한 단계를 지속적으로 최적화함으로써 MySQL 데이터베이스의 성능을 향상시킬 수 있습니다.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 MySQL 설치 오류 솔루션
Apr 08, 2025 am 10:48 AM
MySQL 설치 오류 솔루션
Apr 08, 2025 am 10:48 AM
MySQL 설치 실패에 대한 일반적인 이유 및 솔루션 : 1. 잘못된 사용자 이름 또는 비밀번호 또는 MySQL 서비스가 시작되지 않았으므로 사용자 이름과 비밀번호를 확인하고 서비스를 시작해야합니다. 2. 포트 충돌, MySQL 청취 포트를 변경하거나 포트 3306을 차지하는 프로그램을 닫아야합니다. 3. 종속성 라이브러리가 없으므로 시스템 패키지 관리자를 사용하여 필요한 종속성 라이브러리를 설치해야합니다. 4. 권한이 부족하면 Sudo 또는 관리자 권한을 사용하여 설치 프로그램을 실행해야합니다. 5. 잘못된 구성 파일, 구성이 올바른지 확인하려면 my.cnf 구성 파일을 확인해야합니다. 꾸준하고 신중하게 확인하는 것만으로 만 MySQL을 원활하게 설치할 수 있습니다.
