
트랜스포머 통일 시대에도 컴퓨터 비전의 CNN 방향에 대한 연구는 필요할까요?
올해 초 OpenAI의 대형 비디오 모델인 Sora를 통해 ViT(Vision Transformer) 아키텍처가 인기를 끌었습니다. 그 이후로 ViT와 전통적인 CNN(Convolutional Neural Network) 중 누가 더 강력한지에 대한 논쟁이 계속되고 있습니다.
최근에는 Turing Award 수상자이자 소셜 미디어에서 활발한 활동을 펼치고 있는 Meta의 수석 과학자 Yann LeCun도 ViT와 CNN 간의 분쟁 논의에 동참했습니다.

이 사건의 원인은 Comma.ai의 CTO인 Harald Schäfer가 자신의 최신 연구를 과시하고 있었기 때문입니다. 그는 (많은 최근 AI 학자들과 마찬가지로) Turing Award 거물이 순수 ViT가 실용적이지 않다고 생각하지만 최근 압축기를 순수 ViT로 변경했다는 Yann LeCun의 표현을 인용했습니다. 빠른 이득은 없으며 훈련 시간이 더 오래 걸릴 것입니다. 효과가 아주 좋습니다.
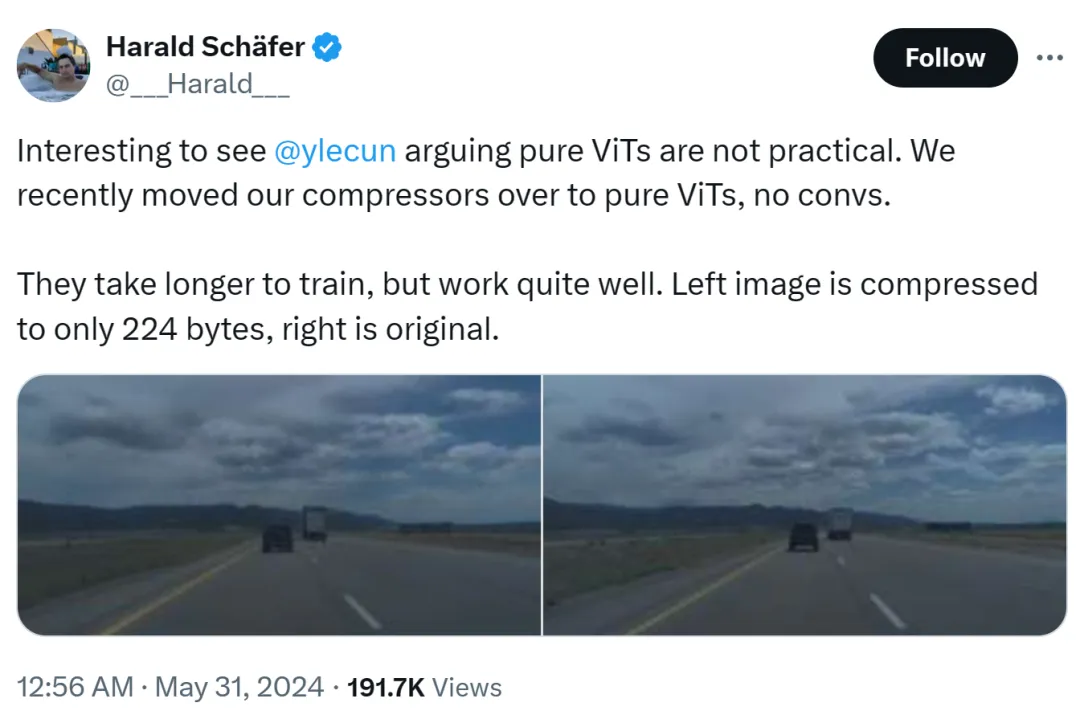
예를 들어 왼쪽 이미지는 224바이트로만 압축된 이미지이고, 오른쪽은 원본 이미지입니다.
은 14×128에 불과하며, 이는 자율 주행을 위한 세계 모델로서는 매우 크며, 이는 훈련에 많은 양의 데이터를 입력할 수 있음을 의미합니다. 가상 환경에서의 교육은 에이전트가 제대로 작동하려면 정책에 따라 교육을 받아야 하는 실제 환경보다 비용이 저렴합니다. 가상 훈련의 경우 해상도가 높을수록 더 잘 작동하지만 시뮬레이터가 매우 느려지므로 현재 압축이 필요합니다.
그의 시연은 AI계에서 논의를 촉발시켰고, 1X 인공지능 부문 에릭 장 부사장은 결과가 놀랍다고 답했다.
Harald는 계속해서 ViT를 칭찬했습니다. 이것은 매우 아름다운 건축물입니다.
누군가 여기서 공격하기 시작했습니다. LeCun과 같은 마스터는 때때로 혁신의 속도를 따라잡지 못합니다.
그러나 Yann LeCun은 즉각적으로 ViT가 실용적이지 않다고 말하는 것이 아니며 지금은 모두가 ViT를 사용하고 있다고 주장했습니다. 그가 표현하고 싶은 것은 ViT가 너무 느리고 비효율적이어서 고해상도 이미지 및 비디오 작업의 실시간 처리에 적합하지 않다는 것입니다.
Yann LeCun은 또한 New York University의 조교수인 Cue Xie Saining도 ConvNext 작업을 통해 방법이 옳다면 CNN이 ViT만큼 좋을 수 있음을 입증했습니다.
그는 계속해서 self-attention 루프를 고수하기 전에 풀링과 스트라이드가 포함된 최소한 몇 개의 컨벌루션 레이어가 필요하다고 말합니다.
self-attention이 순열과 동일하다면 낮은 수준의 이미지 또는 비디오 처리에는 전혀 의미가 없으며 프런트 엔드에서 단일 보폭을 사용하여 패치를 적용하지도 않습니다. 또한, 이미지나 영상의 상관관계는 지역적으로 매우 집중되어 있기 때문에 세계적인 관심은 무의미하고 확장 불가능합니다.
더 높은 수준에서 기능이 객체를 나타내면 self-attention 루프를 사용하는 것이 합리적입니다. 중요한 것은 위치가 아니라 객체 간의 관계와 상호 작용입니다. 이 하이브리드 아키텍처는 메타 연구 과학자 Nicolas Carion과 공동 저자가 완성한 DETR 시스템에 의해 개척되었습니다.
DETR 작업이 등장한 이후 Yann LeCun은 자신이 가장 좋아하는 아키텍처는 낮은 수준의 컨볼루션/스트라이드/풀링 및 높은 수준의 self-attention 루프라고 말했습니다.
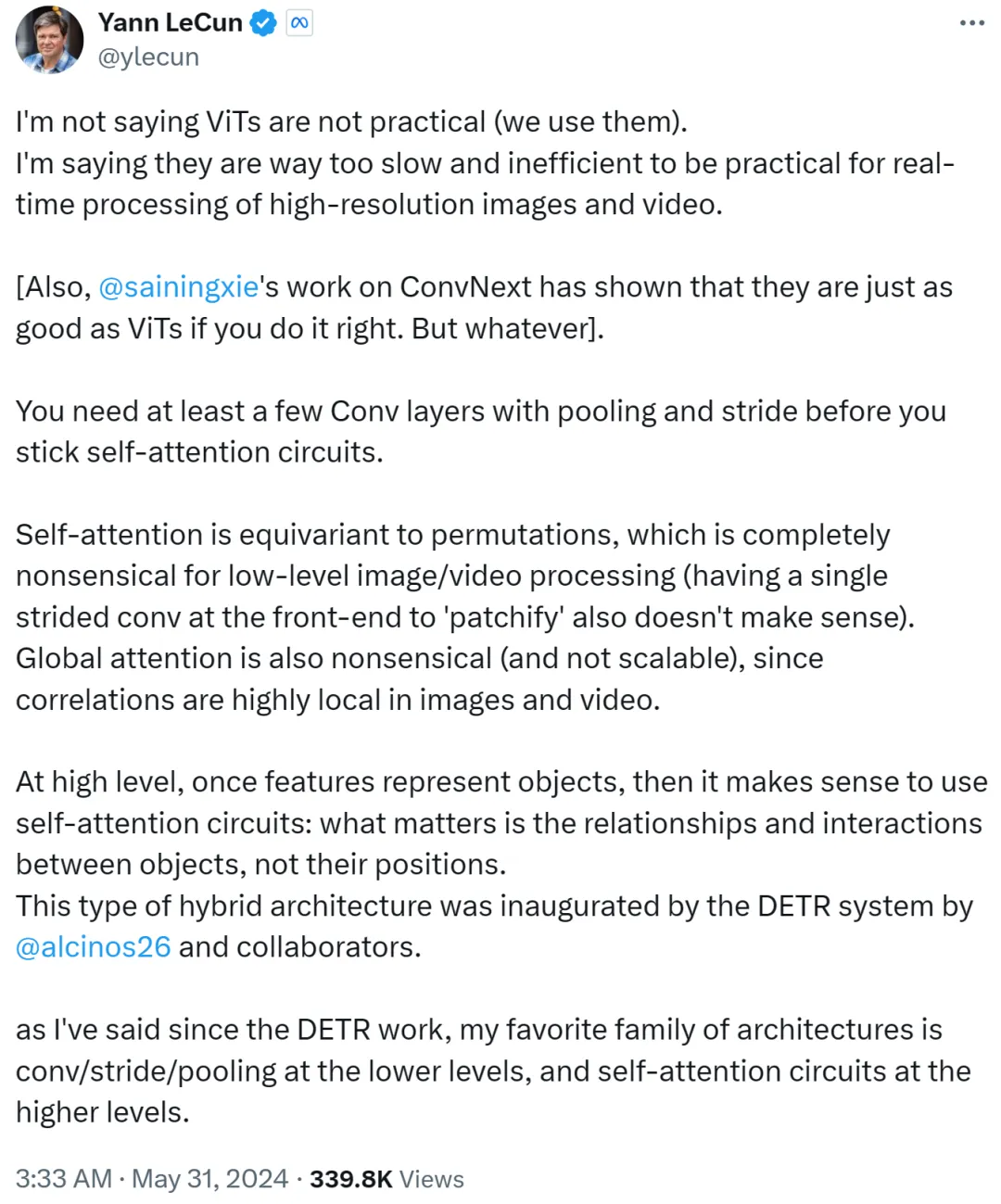
Yann LeCun은 두 번째 게시물에서 이를 요약했습니다. 낮은 수준에서는 스트라이드 또는 풀링과 함께 컨볼루션을 사용하고, 높은 수준에서는 self-attention 루프를 사용하고, 특징 벡터를 사용하여 객체를 표현합니다.
그는 또한 Tesla Fully Self-Driving(FSD)이 낮은 수준에서 컨볼루션(또는 더 복잡한 로컬 연산자)을 사용하고 더 높은 수준에서 더 많은 전역 루프(아마도 self-attention 사용)를 결합할 것이라고 확신합니다. 따라서 낮은 수준의 패치 임베딩에 Transformer를 사용하는 것은 완전한 낭비입니다.
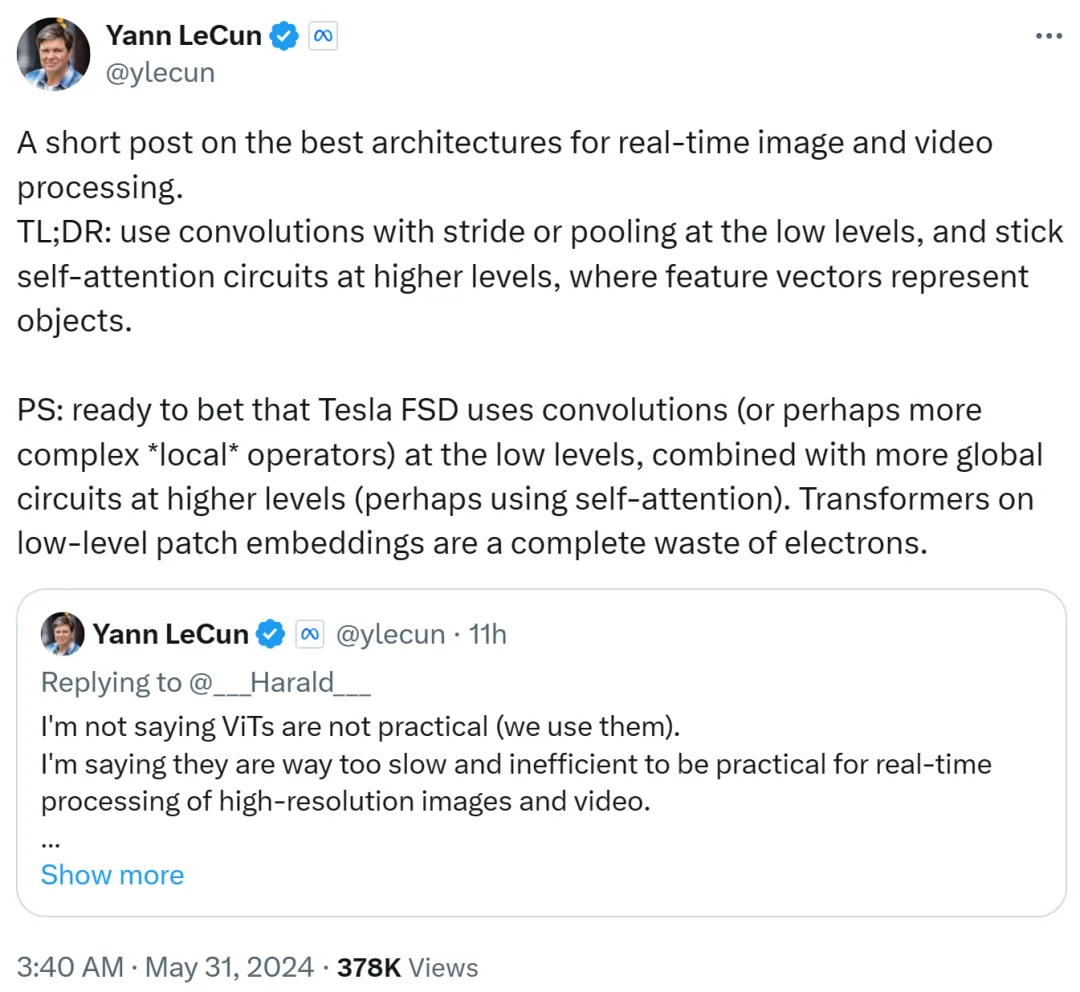
대적 머스크가 여전히 컨볼루션 경로를 사용하는 것 같아요.
Xie Senin도 ViT가 224x224의 저해상도 이미지에 매우 적합하다고 생각하지만, 이미지 해상도가 100만 x 100만이면 어떨까요? 이때 컨볼루션을 사용하거나 공유 가중치를 사용하여 ViT를 패치하고 처리하는 방식이 여전히 컨볼루션입니다.
따라서 Xie Senin은 그 순간 콘볼루션 네트워크가 아키텍처가 아니라 사고 방식이라는 것을 깨달았다고 말했습니다.
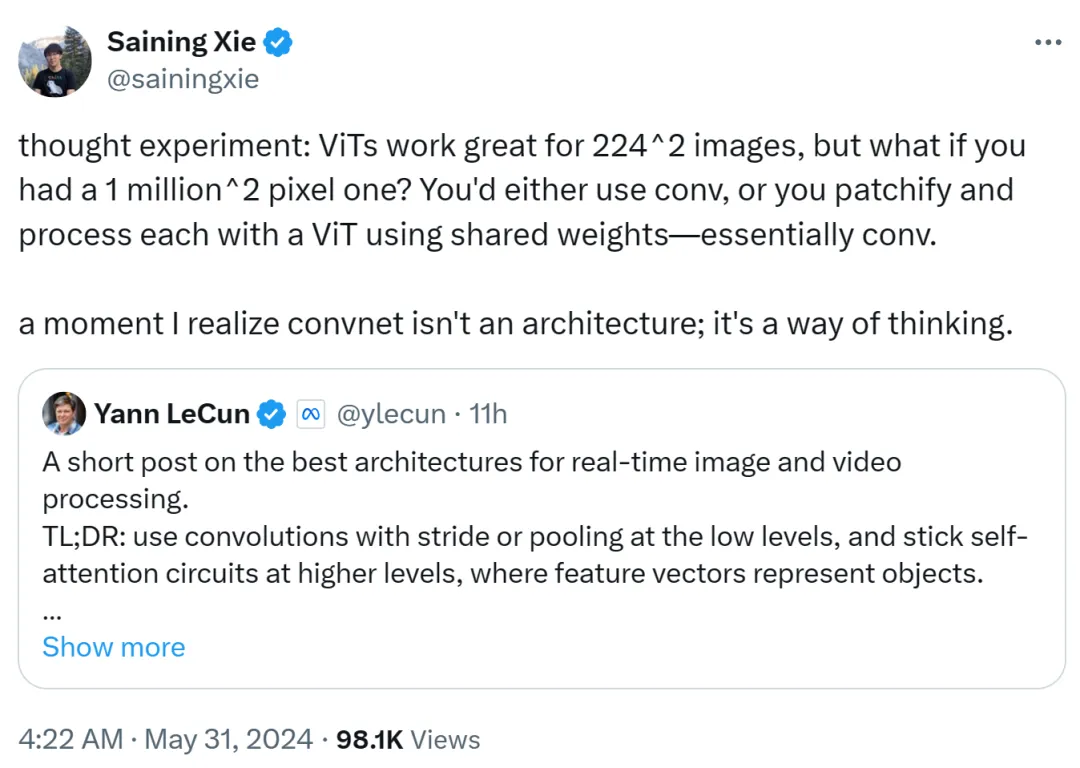
이 뷰는 Yann LeCun이 인정한 것입니다.

Google DeepMind 연구원 Lucas Beyer도 기존 컨볼루션 네트워크의 제로 패딩 덕분에 (ViT + 컨볼루션이 아닌) "컨볼루션 ViT"가 잘 작동할 것이라고 확신한다고 말했습니다.
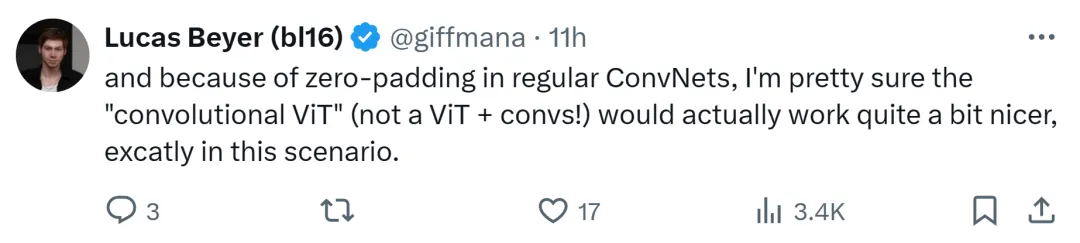
ViT와 CNN 간의 이러한 논쟁은 미래에 더욱 강력한 아키텍처가 등장할 때까지 계속될 것으로 예상됩니다.
위 내용은 Yann LeCun: ViT는 여전히 느리고 비효율적입니다. 실시간 이미지 처리는 여전히 컨볼루션에 의존합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



