

Riva는 실시간 음성 AI 서비스를 위해 출시된 SDK입니다. 고도로 사용자 정의 가능한 도구이며 GPU 가속을 사용합니다. 사전 훈련된 많은 모델이 NGC에서 제공됩니다. 이러한 모델은 즉시 사용할 수 있으며 Riva에서 제공하는 ASR 및 TTS 솔루션을 사용하여 직접 배포할 수 있습니다.
특정 분야의 요구 사항을 충족하거나 맞춤형 기능을 개발하기 위해 사용자는 NeMo를 사용하여 이러한 모델을 재교육하거나 미세 조정할 수도 있습니다. 이를 통해 모델의 성능이 더욱 향상되고 사용자 요구에 더 잘 적응할 수 있게 됩니다.
Riva+Skills는 GPU를 활용하여 실시간 스트리밍 음성 인식 및 음성 합성을 가속화하고 수천 개의 동시 요청을 동시에 처리할 수 있는 고도로 사용자 정의 가능한 도구입니다. 로컬, 클라우드, 엔드사이드를 포함한 다양한 배포 플랫폼을 지원합니다.

Riva는 음성 인식 측면에서 Citrinet, Conformer 및 NeMo가 자체 개발한 FastConformer와 같은 매우 정확한 SOTA 모델을 사용합니다. 현재 Riva는 10개 이상의 단일 언어 모델을 지원하며, 영어-스페인어, 영어-중국어, 영어-일본어 음성 인식을 포함한 다국어 음성 인식도 지원합니다.
맞춤형 기능을 통해 모델의 정확도를 더욱 높일 수 있습니다. 예를 들어, 특정 산업 용어, 억양 또는 방언에 대한 지원과 시끄러운 환경에 대한 사용자 정의는 음성 인식 성능을 향상시키는 데 도움이 될 수 있습니다.
Riva의 전체 프레임워크는 고객 서비스, 회의 시스템 등 다양한 시나리오에 적용될 수 있습니다. 일반적인 시나리오 외에도 Riva의 서비스는 CSP, 교육, 금융 및 기타 산업과 같은 다양한 산업의 요구에 따라 맞춤화될 수도 있습니다.
Riva ASR의 전체 프로세스에는 난이도에 따라 세 가지 범주로 나눌 수 있는 몇 가지 사용자 정의 가능한 모듈이 있습니다.

우선, 주황색 상자는 추론 과정 중에 클라이언트에서 수행할 수 있는 사용자 정의입니다. 예를 들어, 추론 과정에서 제품 이름이나 고유명사를 추가함으로써 음성 모델이 이러한 특정 단어를 보다 정확하게 식별할 수 있는 핫워드 기능을 지원합니다. 이 기능은 Riva에서 기본적으로 지원되며 모델을 다시 훈련하거나 Riva 서버를 다시 시작하지 않고도 사용자 정의할 수 있습니다.
보라색 상자에는 배포 시 만들 수 있는 몇 가지 사용자 정의 항목이 있습니다. 예를 들어, Riva의 스트리밍 인식은 대기 시간 최적화 또는 처리량 최적화라는 두 가지 모드를 제공하며, 이는 더 나은 성능을 얻기 위해 비즈니스 요구 사항에 따라 선택할 수 있습니다. 또한 배포 과정에서 발음 사전을 사용자 정의할 수도 있습니다. 맞춤형 발음사전을 이용하면 특정 용어나 이름, 업계 전문 용어의 정확한 발음을 보장하고 음성 인식의 정확도를 높일 수 있습니다.
녹색 상자는 학습 과정 중에 수행할 수 있는 사용자 정의, 즉 서버 측에서 수행되는 학습 및 조정입니다. 예를 들어 훈련 시작 시 텍스트 정규화 단계에서 특정 텍스트에 대한 일부 처리를 추가할 수 있습니다. 또한 음향 모델을 미세 조정하거나 재학습하여 특정 비즈니스 시나리오의 악센트 및 소음과 같은 문제를 해결하여 모델을 더욱 강력하게 만들 수 있습니다. 또한 언어 모델 재교육, 구두점 모델 미세 조정, 역 텍스트 정규화 등을 수행할 수 있습니다.
위는 Riva의 커스터마이징 가능한 부분입니다.

Riva TTS 프로세스는 위 그림의 오른쪽에 표시됩니다.
위 그림에서 "Hello World"라는 문장을 예로 들어 먼저 텍스트 정규화 모듈에 들어가 대문자와 소문자를 정규화하는 등 텍스트를 표준화합니다. 그런 다음 G2P 모듈을 입력하여 텍스트를 음소 시퀀스로 변환합니다. 그런 다음 스펙트럼 합성 모듈에 들어가서 신경망 훈련을 통해 스펙트럼을 얻습니다. 마지막으로 보코더를 입력하여 스펙트럼을 최종 사운드로 변환합니다.
Riva는 현재 인기 있는 FastPitch와 HiFi-GAN 모델의 조합을 사용하여 스트리밍 TTS 지원을 제공합니다. 현재 영어, 중국어(북경어), 스페인어, 이탈리아어, 독일어를 포함한 여러 언어를 지원합니다.
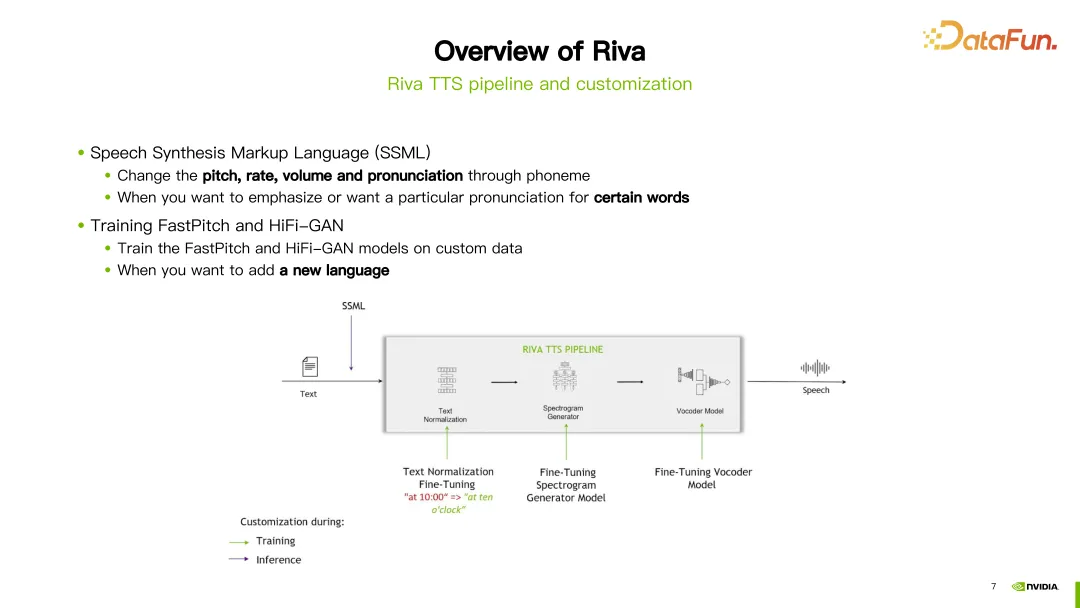
Riva의 TTS 프로세스에서는 Customization을 위한 두 가지 방법이 제공됩니다. 첫 번째 방법은 더 쉽게 사용자 정의할 수 있는 음성 합성 마크업 언어(SSML)를 사용하는 것입니다. 일부 구성을 통해 발음의 높낮이, 말하기 속도, 볼륨 등을 조정할 수 있습니다. 일반적으로 특정 단어의 발음을 변경하려는 경우 이 방법을 선택합니다.
또 다른 방법은 FastPitch 또는 HiFi-GAN 모델을 미세 조정하거나 재교육하는 것입니다. 두 모델 모두 고유한 특정 데이터를 사용하여 미세 조정하거나 재교육할 수 있습니다.

지난 1년 동안 Riva는 중국 모델을 일부 업데이트하고 개선했습니다. 다음은 몇 가지 중요한 업데이트입니다.
우선 중국어 음성 인식(ASR) 모델을 계속해서 최적화하세요. 최신 ASR 모델은 해당 링크에서 찾아보실 수 있습니다.
두 번째로 통합 모델에 대한 지원이 도입되었습니다. 이는 음성인식 구두점 예측이 하나의 추론으로 동시에 이루어질 수 있음을 의미한다.
셋째, 중국어와 영어 혼합 모델에 대한 지원이 추가되었습니다. 이는 모델이 중국어와 영어 음성 입력을 모두 처리할 수 있음을 의미합니다.
또한 몇 가지 새로운 모듈과 기능 지원이 도입되었습니다. 신경망 기반 음성 활동 감지(VAD) 및 화자 분할 모듈이 포함되어 있습니다. 중국어 역텍스트 정규화 기능도 도입되었습니다. 해당 모델에 대한 자세한 내용은 해당 링크에서 확인할 수 있습니다.
또한 중국어에 대한 자세한 튜토리얼도 제공합니다. 첫 번째 부분은 핫 워드(Word Boosting)에 대한 튜토리얼입니다.

핫 단어는 인식 중에 특정 단어의 가중치를 조정하여 단어 인식을 더 정확하게 만듭니다. 튜토리얼에서는 고대 시의 이름인 "Wangyue"와 같은 핫 단어를 사용한 중국어 모델의 예를 보여주며 이 단어에 가중치 20을 부여합니다. 다음으로 Riva에서 제공하는 add_word_boosting_to_config 메소드를 사용하여 클라이언트에 추가하려는 단어와 해당 점수를 구성합니다. 그런 다음 핫 워드를 추가한 후 인식 결과를 얻기 위해 구성된 요청을 ASR 서버로 보냅니다.
핫워드를 구성할 때 Boosted_lm_words 및 Boosted_lm_score라는 두 가지 매개변수를 설정해야 합니다. Boosted_lm_words는 인식 정확도를 향상시키려는 단어 목록입니다. Boosted_lm_score는 이러한 단어에 대해 설정된 점수이며 일반적으로 20에서 100 사이입니다.

이전의 기본 구성 외에도 Riva의 핫워드 기능은 일부 고급 사용법도 지원합니다. 예를 들어, 여러 단어의 가중치를 동시에 늘릴 수 있습니다. 예를 들어, 이 예에서는 단어 "five G"와 "four G"에 대해 각각 20과 30의 가중치를 설정했습니다.
또한 단어 부스팅을 사용하여 특정 단어의 정확성을 줄일 수도 있습니다. 즉, 단어에 음수 가중치를 할당하여 발생 확률을 줄일 수도 있습니다. 예를 들어, 이 예에서는 한자 "she"가 주어지고 그 점수는 -100으로 설정됩니다. 이런 식으로 모델은 한자를 인식하지 못하는 경향이 있습니다. 이론적으로는 대기 시간에 영향을 주지 않고 핫 워드 수를 얼마든지 설정할 수 있습니다. 부스팅 프로세스는 클라이언트 측에서 구현되며 서버 측에는 영향을 미치지 않는다는 점도 주목할 가치가 있습니다.
두 번째 튜토리얼은 Conformer 음향 모델을 미세 조정하는 방법에 대한 것입니다.

ASR 미세 조정은 NeMo 도구를 사용합니다. NGC 계정을 구성한 후 "NGC 다운로드" 명령을 사용하여 Riva에서 제공하는 사전 훈련된 중국어 모델을 직접 다운로드할 수 있습니다. 이 예에서는 중국 ASR 모델의 다섯 번째 버전이 다운로드되었습니다. 다운로드가 완료되면 사전 훈련된 모델을 로드해야 합니다.
먼저 일부 패키지를 가져와야 합니다. 매개변수 모델 경로는 방금 다운로드한 모델의 경로로 설정됩니다. 다음으로 NeMo에서 제공하는 ASRModel.restore_from 함수를 사용하여 모델 구성 파일을 얻고, target 매개변수를 사용하여 원본 ASR 모델의 카테고리를 얻습니다. 다음으로 import_class_by_path 함수를 사용하여 실제 모델 클래스를 가져옵니다. 마지막으로 이 카테고리에 있는 모델의 Restore_from 메소드를 사용하여 지정된 경로에 있는 ASR 모델 매개변수를 로드합니다.

모델을 로드한 후 NeMo에서 제공하는 교육 스크립트를 사용하여 미세 조정할 수 있습니다. 이 예에서는 CTC 모델 교육을 예로 들었고 사용된 스크립트는 speech_to_text_ctc.py입니다. 구성해야 하는 일부 매개변수에는 훈련 데이터의 JSON 파일 경로인 train_ds.manifest_filepath와 GPU 사용 여부, 최적화 프로그램 및 최대 반복 라운드 수 등이 포함됩니다.
모델 학습 후 평가할 수 있습니다. 평가할 때 use_cer 매개변수를 true로 설정하는 데 주의해야 합니다. 중국어의 경우 문자 오류율(Character Error Rate)을 지표로 사용하기 때문입니다. 모델 훈련 및 평가를 완료한 후 nemo2riva 명령을 사용하여 NeMo 모델을 Riva 모델로 변환할 수 있습니다. 그런 다음 Riva의 빠른 시작 도구를 사용하여 모델을 배포하세요.
다음으로 Riva TTS 서비스를 소개하겠습니다.
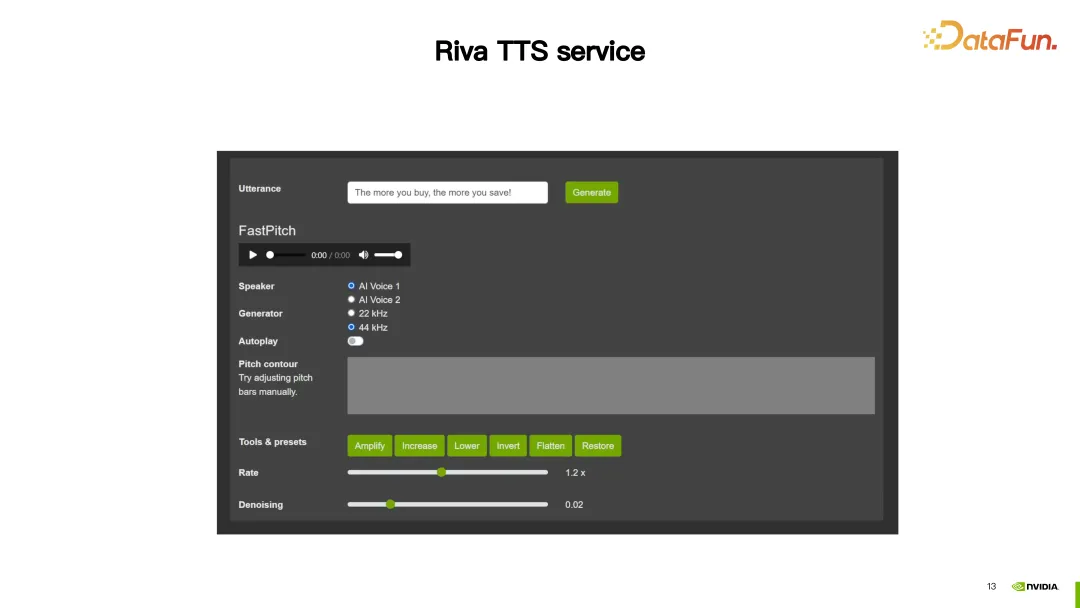
이 데모에서 Riva TTS는 합성된 음성을 더욱 자연스럽게 만들기 위한 맞춤 기능을 제공합니다.
다음으로 Riva TTS에서 제공하는 2가지 커스터마이징 방법을 소개하겠습니다.

첫 번째는 앞서 언급한 SSML(Speech Synesis Markup Language)로, 스크립트를 통해 구성됩니다. SSML을 통해 TTS의 리듬(음높이, 속도 포함)을 조정할 수 있으며 볼륨도 조정할 수 있습니다.
위 그림과 같이 첫 번째 문장 "오늘은 맑은 날"에서 운율의 높낮이를 2.5로 변경합니다. 두 번째 문장에서는 두 가지 구성을 했는데, 하나는 속도를 높게 설정하는 것이고, 다른 하나는 볼륨을 1DB 늘리는 것이었습니다. 이렇게 하면 맞춤형 결과를 얻을 수 있습니다.
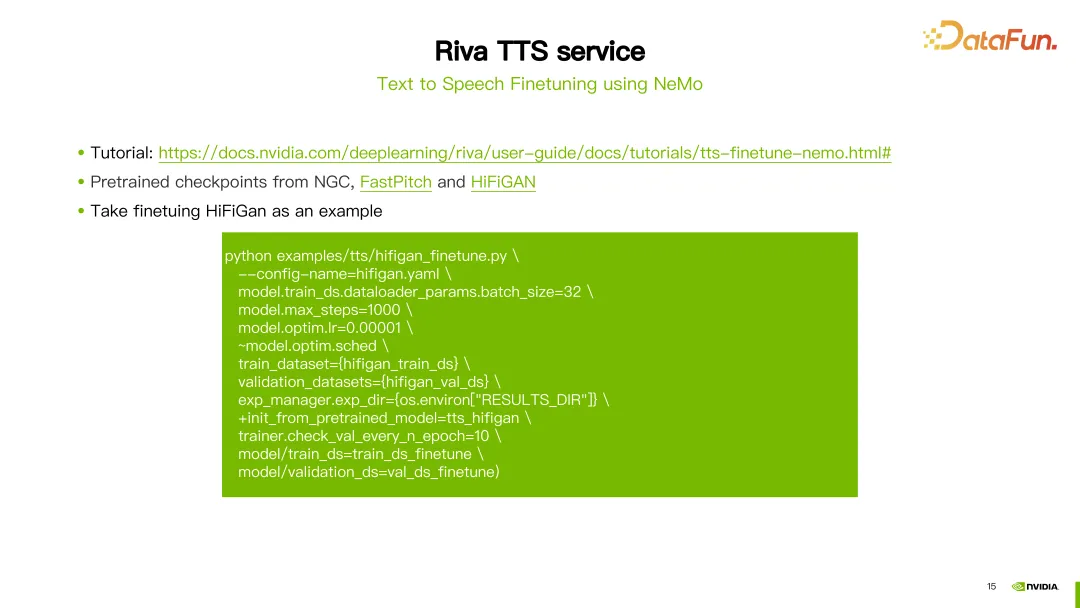
SSML 외에도 NeMo 도구를 사용하여 Riva TTS의 FastPitch 또는 HiFi-GAN 모델을 미세 조정하거나 재교육할 수도 있습니다.
Riva는 NGC에 대한 튜토리얼과 일부 사전 훈련된 모델을 제공합니다(위 이미지의 링크 참조).
사진은 HiFi-GAN 모델을 미세 조정한 예를 보여줍니다. hifigan_finetune.py 명령을 사용하여 모델 구성 이름, 배치 크기, 최대 반복 단계 수, 학습 속도와 같은 매개변수를 구성합니다. train_dataset 매개변수를 설정하여 HiFi-GAN을 미세 조정하는 데 필요한 데이터 세트 경로를 설정합니다. NGC에서 사전 훈련된 모델을 다운로드한 경우 init_from_pretrained_model 매개변수를 사용하여 사전 훈련된 모델을 로드할 수도 있습니다. 이러한 방식으로 HiFi-GAN 모델을 재교육할 수 있습니다.
Quickstart 도구를 사용하여 맞춤형 모델을 배포할 수 있습니다.

시작하기 전에 NGC 계정을 등록해야 하며, GPU가 Riva를 지원하는지, Docker 환경이 설치되어 있는지 확인하세요.
준비가 완료되면 제공된 링크를 통해 Riva Quickstart를 다운로드하세요. NGC CLI가 구성된 경우 NGC CLI를 사용하여 Riva Quickstart를 직접 다운로드할 수도 있습니다.
Riva Quick Start를 다운로드한 후 제공된 스크립트를 사용하여 서버를 초기화, 시작 및 종료할 수 있습니다.

최신 버전의 Riva(2.13.1)를 예로 들면, 다운로드가 완료된 후 riva_init.sh, riva_start.sh 또는 riva_stop.sh만 실행하면 초기화, 시작이 완료됩니다. 그리고 서버 종료.
중국어 모델을 사용하려면 언어 코드를 zh-CN으로 설정하면 도구가 자동으로 해당 사전 훈련된 모델을 다운로드합니다. 중국어 ASR(자동 음성 인식) 및 TTS(문자 음성 변환) 기능을 사용하기 위해 서비스를 시작할 수 있습니다.

서버가 성공적으로 시작되면 Riva에서 제공하는 스크립트 riva_start_client.sh를 사용하여 서비스를 호출할 수 있습니다. 오프라인 음성 인식을 원할 경우 riva_asr_client 명령을 실행하고 인식하려는 오디오 파일의 경로를 지정하면 됩니다. 스트리밍 음성 인식을 수행하려면 riva_streaming_asr_client 명령을 사용하면 됩니다. 음성 합성을 수행하려면 riva_tts_client 명령을 사용하여 처리하거나 합성할 오디오를 방금 시작한 서버로 보낼 수 있습니다.
다음은 Riva 관련 문서 리소스입니다.

Riva 공식 문서: 이 문서는 설치, 구성 및 사용 가이드를 포함하여 Riva에 대한 자세한 정보를 제공합니다. 여기에서 Riva의 공식 문서를 찾아 Riva에 대해 자세히 알아보고 모든 측면을 알아볼 수 있습니다.
Riva 빠른 시작 사용자 가이드: 이 가이드는 설치 및 구성 단계는 물론 자주 묻는 질문에 대한 답변을 포함하여 Riva 빠른 시작에 대한 자세한 지침을 사용자에게 제공합니다. Riva Quick Start를 사용하면서 문제가 발생하는 경우, 이 사용자 가이드에서 답변을 찾을 수 있습니다.
Riva 출시 노트: 이 문서는 Riva의 최신 모델에 대한 업데이트된 정보를 제공합니다. 여기에서 각 버전의 새로운 기능과 향상된 기능을 확인할 수 있습니다.
위 리소스는 사용자가 Riva를 더 잘 이해하고 사용하는 데 도움이 될 것입니다.
위는 이번에 공유한 내용입니다. 모두 감사드립니다.
A1: 예, Riva는 Nvidia Triton의 일부 개발을 기반으로 하는 Nvidia Triton의 추론 프레임워크를 사용합니다.
A2: Riva는 현재 Speech AI 분야에 주로 집중해야 합니다.
A3: Riva는 배포 솔루션에 더 중점을 둡니다. Nemo로 훈련된 모델을 Riva로 배포할 수도 있으며, 일부 미세 조정 및 훈련 작업을 수행한 다음 좋은 모델을 미세 조정하여 배포할 수도 있습니다. 리바에서.
A4: 다른 프레임워크를 사용한 교육은 일시적으로 지원되지 않거나 일부 추가 개발 작업이 필요합니다.
A5: Riva는 이제 Nemo가 훈련한 모델을 주로 지원합니다. Nemo는 실제로 PyTorch를 기반으로 개발되었습니다.
A6: 자체 개발한 모델의 경우 Riva에서 지원하려면 추가 개발을 해야 합니다.
A7: 다양한 유형의 GPU에 대한 적응이 포함된 Riva에서 제공하는 적응 플랫폼 관련 문서를 참조할 수 있습니다.
A8: NGC에서 직접 Riva Quickstart 툴킷을 다운로드하여 Riva를 사용해 볼 수 있습니다.
A9: 그렇죠. 일부 방언으로 데이터를 사용할 수 있습니다. Riva에서 제공하는 사전 훈련된 모델을 기반으로 미세 조정한 후 Riva에 배포하면 됩니다.
A10: Riva의 가속은 실제로 Tensor RT를 사용합니다. Riva는 Tensor RT와 Triton을 기반으로 한 제품입니다.
위 내용은 NVIDIA Riva를 사용하여 기업 수준의 중국어 음성 AI 서비스를 신속하게 배포하고 최적화 및 가속화하세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



