

지식 그래프 검색을 위해 향상된 GraphRAG(Neo4j 코드를 기반으로 구현됨)

Graph Retrieval Enhanced Generation(Graph RAG)은 점차 대중화되고 있으며 기존 벡터 검색 방법을 강력하게 보완하는 수단이 되었습니다. 이 방법은 그래프 데이터베이스의 구조적 특성을 활용하여 데이터를 노드와 관계의 형태로 구성함으로써 검색된 정보의 깊이와 맥락적 관련성을 향상시킵니다. 그래프는 다양하고 상호 연관된 정보를 표현하고 저장하는 데 자연스러운 이점을 가지며, 다양한 데이터 유형 간의 복잡한 관계와 속성을 쉽게 캡처할 수 있습니다. 벡터 데이터베이스는 이러한 유형의 구조화된 정보를 처리할 수 없으며 고차원 벡터로 표현되는 구조화되지 않은 데이터를 처리하는 데 더 중점을 둡니다. RAG 애플리케이션에서 구조화된 그래프 데이터와 구조화되지 않은 텍스트 벡터 검색을 결합하면 이 기사에서 논의할 내용인 두 가지의 장점을 동시에 누릴 수 있습니다.
지식 그래프를 구축하는 것은 그래프 데이터 표현의 힘을 활용하는 데 있어 가장 어려운 단계인 경우가 많습니다. 데이터를 수집하고 정리하는 것이 필요하며, 이를 위해서는 도메인 지식과 그래프 모델링에 대한 깊은 이해가 필요합니다. 이 프로세스를 단순화하기 위해 기존 프로젝트를 참조하거나 LLM을 사용하여 지식 그래프를 만든 다음 검색 및 회상에 집중하여 LLM 생성 단계를 개선할 수 있습니다. 아래의 관련 코드를 연습해 보겠습니다.
1. 지식 그래프 구축
지식 그래프 데이터를 저장하려면 먼저 Neo4j 인스턴스를 구축해야 합니다. 가장 쉬운 방법은 Neo4j 데이터베이스의 클라우드 버전을 제공하는 Neo4j Aura에서 무료 인스턴스를 시작하는 것입니다. 물론 Docker를 통해 로컬로 시작한 다음 그래프 데이터를 Neo4j 데이터베이스로 가져올 수도 있습니다.
1단계: Neo4j 환경 설정
다음은 로컬에서 docker를 실행하는 예입니다.
docker run -d \--restart always \--publish=7474:7474 --publish=7687:7687 \--env NEO4J_AUTH=neo4j/000000 \--volume=/yourdockerVolume/neo4j:/data \neo4j:5.19.0
2단계: 그래프 데이터 가져오기
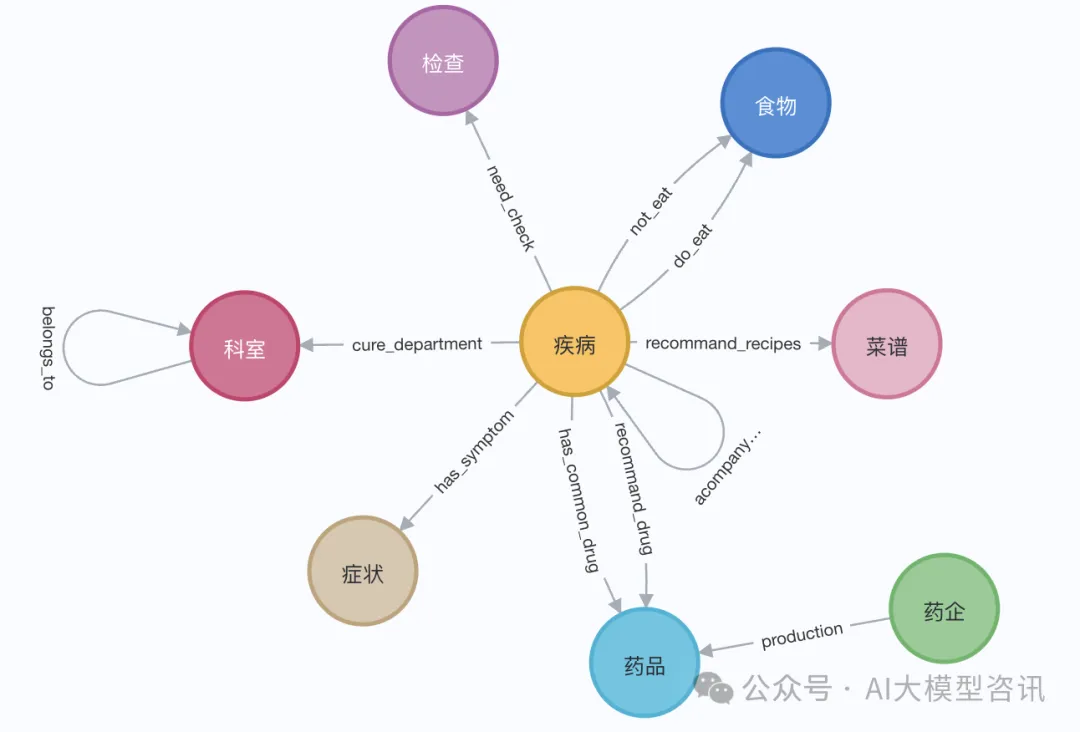
데모에서는 Elizabeth I의 Wikipedia 페이지를 사용할 수 있습니다. LangChain 로더를 사용하여 Wikipedia에서 문서를 가져와 분할한 다음 Neo4j 데이터베이스에 저장합니다. 중국어로 효과를 테스트하기 위해 Github에서 이 프로젝트(QASystemOnMedicalKG)의 의학 지식 그래프를 가져왔는데, 여기에는 거의 35,000개의 노드와 300,000개의 트리플 세트가 포함되어 있습니다.
 Pictures
Pictures
또는 대략 다음 단계에 표시된 대로 LangChainLangChain 로더를 사용하여 Wikipedia에서 문서를 가져오고 분할합니다.
# 读取维基百科文章raw_documents = WikipediaLoader(query="Elizabeth I").load()# 定义分块策略text_splitter = TokenTextSplitter(chunk_size=512, chunk_overlap=24)documents = text_splitter.split_documents(raw_documents[:3])llm=ChatOpenAI(temperature=0, model_name="gpt-4-0125-preview")llm_transformer = LLMGraphTransformer(llm=llm)# 提取图数据graph_documents = llm_transformer.convert_to_graph_documents(documents)# 存储到 neo4jgraph.add_graph_documents(graph_documents, baseEntityLabel=True, include_source=True)
2. 지식 그래프 검색
지식 그래프를 검색하기 전에 엔터티 및 관련 속성을 벡터에 삽입하고 저장해야 합니다. Neo4j 데이터베이스에:
- 엔티티 정보 벡터 임베딩: 엔터티 이름과 엔터티 설명 정보를 이어붙인 후 벡터 표현 모델을 사용하여 벡터 임베딩을 수행합니다(아래 샘플 코드의 add_embeddings 메서드에 표시됨).
- 그래프의 구조적 검색: 그래프의 구조적 검색은 4단계로 나뉩니다. 1단계, 그래프에서 쿼리와 관련된 엔터티 검색 2단계, 글로벌 인덱스에서 엔터티 태그 검색 , 엔터티 태그를 기반으로 해당 노드의 이웃 노드 경로를 쿼리합니다. 4단계, 관계를 필터링하여 다양성을 유지합니다(전체 검색 프로세스는 아래 샘플 코드의 구조화_retriever 메서드에 표시됨).
class GraphRag(object):def __init__(self):"""Any embedding function implementing `langchain.embeddings.base.Embeddings` interface."""self._database = 'neo4j'self.label = 'Med'self._driver = neo4j.GraphDatabase.driver(uri=os.environ["NEO4J_URI"],auth=(os.environ["NEO4J_USERNAME"],os.environ["NEO4J_PASSWORD"]))self.embeddings_zh = HuggingFaceEmbeddings(model_name=os.environ["EMBEDDING_MODEL"])self.vectstore = Neo4jVector(embedding=self.embeddings_zh, username=os.environ["NEO4J_USERNAME"], password=os.environ["NEO4J_PASSWORD"], url=os.environ["NEO4J_URI"], node_label=self.label, index_name="vector" )def query(self, query: str, params: dict = {}) -> List[Dict[str, Any]]:"""Query Neo4j database."""from neo4j.exceptions import CypherSyntaxErrorwith self._driver.session(database=self._database) as session:try:data = session.run(query, params)return [r.data() for r in data]except CypherSyntaxError as e:raise ValueError(f"Generated Cypher Statement is not valid\n{e}")def add_embeddings(self):"""Add embeddings to Neo4j database."""# 查询图中所有节点,并且根据节点的描述和名字生成embedding,添加到该节点上query = """MATCH (n) WHERE not (n:{}) RETURN ID(n) AS id, labels(n) as labels, n""".format(self.label)print("qurey node...")data = self.query(query)ids, texts, embeddings, metas = [], [], [], []for row in tqdm(data,desc="parsing node"):ids.append(row['id'])text = row['n'].get('name','') + row['n'].get('desc','')texts.append(text)metas.append({"label": row['labels'], "context": text})self.embeddings_zh.multi_process = Falseprint("node embeddings...")embeddings = self.embeddings_zh.embed_documents(texts)print("adding node embeddings...")ids_ret = self.vectstore.add_embeddings(ids=ids,texts=texts,embeddings=embeddings,metadatas=metas)return ids_ret# Fulltext index querydef structured_retriever(self, query, limit=3, simlarity=0.9) -> str:"""Collects the neighborhood of entities mentioned in the question"""# step1 从图谱中检索与查询相关的实体。docs_with_score = self.vectstore.similarity_search_with_score(query, k=topk)entities = [item[0].page_content for item in data if item[1] > simlarity] # scoreself.vectstore.query("CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:Med) ON EACH [e.context]")result = ""for entity in entities:qry = entity# step2 从全局索引中查出entity label,query1 =f"""CALL db.index.fulltext.queryNodes('entity', '{qry}') YIELD node, score return node.label as label,node.context as context, node.id as id, score LIMIT {limit}"""data1 = self.vectstore.query(query1)# step3 根据label在相应的节点中查询邻居节点路径for item in data1:node_type = item['label']node_type = item['label'] if type(node_type) == str else node_type[0]node_id = item['id']query2 = f"""match (node:{node_type})-[r]-(neighbor) where ID(node) = {node_id} RETURN type(r) as rel, node.name+' - '+type(r)+' - '+neighbor.name as output limit 50"""data2 = self.vectstore.query(query2)# step4 为了保持多样性,对关系进行筛选rel_dict = defaultdict(list)if len(data2) > 3*limit:for item1 in data2:rel_dict[item1['rel']].append(item1['output'])if rel_dict:rel_dict = {k:random.sample(v, 3) if len(v)>3 else v for k,v in rel_dict.items()}result += "\n".join(['\n'.join(el) for el in rel_dict.values()]) +'\n'else:result += "\n".join([el['output'] for el in data2]) +'\n'return result3. LLM 생성과 결합
마지막으로 LLM(대형 언어 모델)을 사용하여 지식 그래프에서 검색된 구조화된 정보를 기반으로 최종 답변을 생성합니다. 다음 코드에서는 Tongyi Qianwen 오픈 소스의 대규모 언어 모델을 예로 들어 보겠습니다.
1단계: LLM 모델 로드
from langchain import HuggingFacePipelinefrom transformers import pipeline, AutoTokenizer, AutoModelForCausalLMdef custom_model(model_name, branch_name=None, cache_dir=None, temperature=0, top_p=1, max_new_tokens=512, stream=False):tokenizer = AutoTokenizer.from_pretrained(model_name, revision=branch_name, cache_dir=cache_dir)model = AutoModelForCausalLM.from_pretrained(model_name,device_map='auto',torch_dtype=torch.float16,revision=branch_name,cache_dir=cache_dir)pipe = pipeline("text-generation",model = model,tokenizer = tokenizer,torch_dtype = torch.bfloat16,device_map = 'auto',max_new_tokens = max_new_tokens,do_sample = True)llm = HuggingFacePipeline(pipeline = pipe,model_kwargs = {"temperature":temperature, "top_p":top_p,"tokenizer":tokenizer, "model":model})return llmtongyi_model = "Qwen1.5-7B-Chat"llm_model = custom_model(model_name=tongyi_model)tokenizer = llm_model.model_kwargs['tokenizer']model = llm_model.model_kwargs['model']2단계: 검색 데이터를 입력하여 응답 생성
final_data = self.get_retrieval_data(query)prompt = ("请结合以下信息,简洁和专业的来回答用户的问题,若信息与问题关联紧密,请尽量参考已知信息。\n""已知相关信息:\n{context} 请回答以下问题:{question}".format(cnotallow=final_data, questinotallow=query))messages = [{"role": "system", "content": "你是**开发的智能助手。"},{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(self.device)generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print(response)4 결론
RAG 없이 LLM만 사용하여 응답을 생성하는 상황에 비해 쿼리 질문을 별도로 테스트한 경우 GraphRAG를 사용하면 LLM 모델이 더 많은 양의 정보에 응답하고 더 정확합니다.
위 내용은 지식 그래프 검색을 위해 향상된 GraphRAG(Neo4j 코드를 기반으로 구현됨)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7315
7315
 9
1625
14
1348
46
1261
25
1208
29
9
1625
14
1348
46
1261
25
1208
29

 Groq Llama 3 70B를 로컬에서 사용하기 위한 단계별 가이드
Jun 10, 2024 am 09:16 AM
Groq Llama 3 70B를 로컬에서 사용하기 위한 단계별 가이드
Jun 10, 2024 am 09:16 AM
Groq Llama 3 70B를 로컬에서 사용하기 위한 단계별 가이드
 Caltech Chinese는 AI를 사용하여 수학적 증명을 뒤집습니다! 충격적인 Tao Zhexuan의 속도 5배 향상, 수학 단계의 80%가 완전 자동화됨
Apr 23, 2024 pm 03:01 PM
Caltech Chinese는 AI를 사용하여 수학적 증명을 뒤집습니다! 충격적인 Tao Zhexuan의 속도 5배 향상, 수학 단계의 80%가 완전 자동화됨
Apr 23, 2024 pm 03:01 PM
Caltech Chinese는 AI를 사용하여 수학적 증명을 뒤집습니다! 충격적인 Tao Zhexuan의 속도 5배 향상, 수학 단계의 80%가 완전 자동화됨
 '인간 + RPA'에서 '인간 + 생성 AI + RPA'까지 LLM은 RPA 인간-컴퓨터 상호 작용에 어떤 영향을 미치나요?
Jun 05, 2023 pm 12:30 PM
'인간 + RPA'에서 '인간 + 생성 AI + RPA'까지 LLM은 RPA 인간-컴퓨터 상호 작용에 어떤 영향을 미치나요?
Jun 05, 2023 pm 12:30 PM
'인간 + RPA'에서 '인간 + 생성 AI + RPA'까지 LLM은 RPA 인간-컴퓨터 상호 작용에 어떤 영향을 미치나요?



 지식 그래프 검색을 위해 향상된 GraphRAG(Neo4j 코드를 기반으로 구현됨)
Jun 12, 2024 am 10:32 AM
지식 그래프 검색을 위해 향상된 GraphRAG(Neo4j 코드를 기반으로 구현됨)
Jun 12, 2024 am 10:32 AM
지식 그래프 검색을 위해 향상된 GraphRAG(Neo4j 코드를 기반으로 구현됨)
 FAISS 벡터 공간을 시각화하고 RAG 매개변수를 조정하여 결과 정확도 향상
Mar 01, 2024 pm 09:16 PM
FAISS 벡터 공간을 시각화하고 RAG 매개변수를 조정하여 결과 정확도 향상
Mar 01, 2024 pm 09:16 PM
FAISS 벡터 공간을 시각화하고 RAG 매개변수를 조정하여 결과 정확도 향상
