
소프트웨어 기술의 선두에 있는 UIUC Zhang Lingming 그룹은 BigCode 조직의 연구원들과 함께 최근 StarCoder2-15B-Instruct 대규모 코드 모델을 발표했습니다.
이 혁신적인 성과는 코드 생성 작업에서 획기적인 발전을 이루어 CodeLlama-70B-Instruct를 성공적으로 능가하고 코드 생성 성능 목록의 상위에 올랐습니다.

StarCoder2-15B-Instruct의 독창성은 전체 교육 프로세스가 개방적이고 투명하며 완전히 자율적이고 제어 가능하다는 것입니다.
이 모델은 StarCoder2-15B를 통해 수천 개의 명령을 생성하고 이에 대응하여 StarCoder-15B 기본 모델을 미세 조정합니다. 값비싼 데이터 주석에 의존할 필요도 없고 대규모 상용 시스템에서 데이터를 얻을 필요도 없습니다. GPT4와 같은 모델을 사용하여 잠재적인 저작권 문제를 피합니다.
HumanEval 테스트에서 StarCoder2-15B-Instruct는 Pass@1 점수 72.6%로 두각을 나타냈으며 이는 CodeLlama-70B-Instruct의 72.0%보다 향상되었습니다.
LiveCodeBench 데이터 세트에 대한 평가에서 이 자체 정렬 모델은 GPT-4 생성 데이터에 대해 훈련된 유사한 모델보다 성능이 뛰어났습니다. 이 결과는 대형 모델이 외부 교사의 대형 모델의 편향된 분포에 의존하지 않고 자체 분포 내의 데이터를 사용하여 인간과 유사하게 정렬하는 방법을 효과적으로 학습할 수도 있음을 보여줍니다.
이 프로젝트의 성공적인 구현은 Northeastern University, University of California, Berkeley, ServiceNow 및 Hugging Face 및 기타 기관의 Arjun Guha 연구 그룹으로부터 강력한 지원을 받았습니다.
StarCoder2-Instruct의 데이터 생성 프로세스는 주로 세 가지 핵심 단계로 구성됩니다.
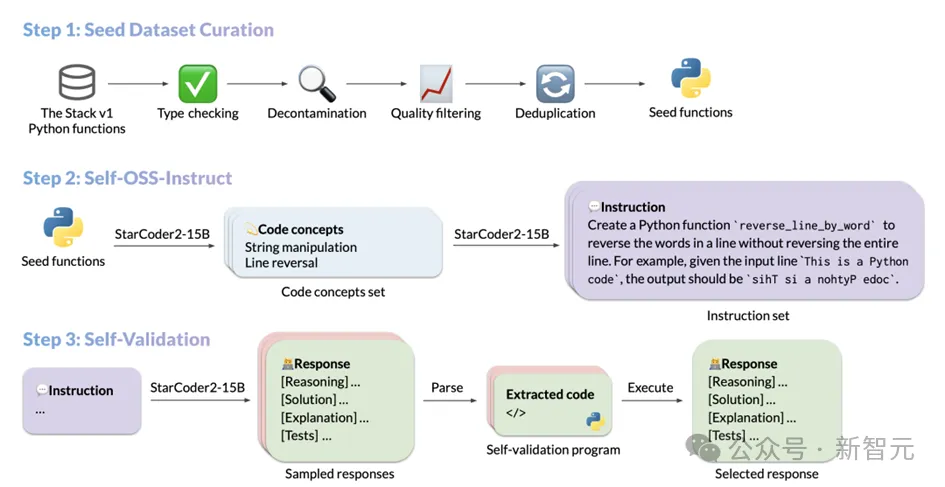
1 The Team from The Stack v. 1 라이센스가 부여된 대규모 소스 코드 모음에서 고품질의 다양한 시드 기능을 필터링합니다. 엄격한 필터링과 심사를 통해 시드 코드의 품질과 다양성이 보장됩니다.
2. 다양한 명령어 생성:시드 기능의 다양한 프로그래밍 개념을 기반으로 StarCoder2-15B-Instruct는 다양한 명령어를 생성할 수 있습니다. 그리고 현실적인 코드 지침. 이 명령어는 데이터 역직렬화부터 목록 연결, 재귀까지 광범위한 프로그래밍 시나리오를 다룹니다.
3. 고품질 응답 생성:각 명령어에 대해 모델은 컴파일 및 실행을 채택합니다. 안내된 자가 검증 방법을 통해 생성된 응답이 정확하고 고품질인지 확인합니다. 각 단계의 구체적인 작업은 다음과 같습니다.
시드 코드 조각을 선택하는 과정
기본 데이터 세트를 구축할 때 StarCoder2-15B-Instruct는 The Stack V1에 대한 심층적인 탐색을 수행하고 문서화된 지침과 함께 모든 Python 함수를 선택했으며 다음의 도움으로 이러한 함수에 필요한 함수를 자동으로 분석하고 추론했습니다. 자동 가져오기 기능 종속성.
데이터 세트의 순도와 고품질을 보장하기 위해 StarCoder2-15B-Instruct는 선택된 모든 기능을 신중하게 필터링하고 선별했습니다.
먼저 Pyright 유형 검사기를 통해 엄격한 유형 검사를 수행하며 정적 오류를 일으킬 수 있는 모든 기능을 제외하여 데이터의 정확성과 신뢰성을 보장합니다.
이후 정밀한 문자열 매칭 기술을 통해 평가 데이터 세트와 잠재적으로 관련이 있는 코드 및 힌트를 식별하고 제거하여 데이터 오염을 방지합니다. 문서 품질 측면에서 StarCoder2-15B-Instruct는 독특한 검사 메커니즘을 채택합니다.
자체 평가 기능을 사용하여 모델에 7개의 샘플 프롬프트를 표시함으로써 모델이 각 기능의 문서 품질이 표준을 충족하는지 판단하여 최종 데이터 세트에 포함할지 여부를 결정할 수 있습니다.
모델 자체 판단을 기반으로 하는 이 방법은 데이터 스크리닝의 효율성과 정확성을 향상시킬 뿐만 아니라 데이터 세트의 높은 품질과 일관성을 보장합니다.
마지막으로, 데이터 중복 및 중복을 피하기 위해 StarCoder2-15B-Instruct는 MinHash 및 지역 구분 해싱 알고리즘을 사용하여 데이터 세트에서 함수를 중복 제거합니다. Jaccard 유사성 임계값을 0.5로 설정하면 유사성이 높은 중복 함수가 효과적으로 제거되어 데이터 세트의 고유성과 다양성이 보장됩니다.
이 일련의 정밀한 선별 및 필터링 후에 StarCoder2-15B-Instruct는 마침내 문서를 시드 데이터 세트로 사용하여 500만 개의 Python 함수 중에서 250,000개의 고품질 함수를 선택했습니다. 이 접근 방식은 MultiPL-T 데이터 수집 프로세스에서 크게 영감을 받았습니다.
StarCoder2-15B-Instruct는 시드 기능 모음을 완성하면 Self-OSS-Instruct 기술을 사용하여 다양한 프로그래밍 명령어를 생성합니다. 이 기술의 핵심은 StarCoder2-15B 기본 모델이 상황별 학습을 통해 주어진 시드 코드 조각에 대한 해당 명령을 자동으로 생성할 수 있도록 하는 것입니다.
이 목표를 달성하기 위해 StarCoder2-15B-Instruct는 16개의 예제를 신중하게 설계했으며 각 예제는 (코드 조각, 개념, 지침)의 구조를 따릅니다. 명령어 생성 프로세스는 두 단계로 세분화됩니다.
코드 개념 식별: 이 단계에서 StarCoder2-15B는 각 시드 기능에 대한 심층 분석을 수행하고 해당 기능의 핵심 코드 개념이 포함된 목록을 생성합니다. 이러한 개념은 패턴 일치, 데이터 유형 변환 등 프로그래밍 분야의 기본 원리와 기술을 광범위하게 다루며 개발자에게 매우 실용적인 가치가 있습니다.
명령 생성: 인식된 코드 개념을 기반으로 StarCoder2-15B는 해당 코딩 작업 지침을 추가로 생성합니다. 이 프로세스는 생성된 지침이 코드 조각의 핵심 기능과 요구 사항을 정확하게 반영하도록 설계되었습니다.
위 프로세스를 통해 StarCoder2-15B-Instruct는 마침내 최대 238k 명령을 성공적으로 생성하여 교육 데이터 세트를 크게 풍부하게 하고 프로그래밍 작업 성능에 대한 강력한 지원을 제공했습니다.
Self-OSS-Instruct에서 생성된 명령어를 얻은 후 StarCoder2-15B-Instruct의 핵심 작업은 각 명령어에 대해 고품질 응답을 일치시키는 것입니다. .
전통적으로 사람들은 이러한 응답을 얻기 위해 GPT-4와 같은 더 강력한 교사 모델에 의존하는 경향이 있지만 이 접근 방식은 저작권 라이센스 문제에 직면할 수 있을 뿐만 아니라 외부 모델이 항상 접근 가능하거나 정확하지는 않습니다. 더 중요한 것은 외부 모델에 의존하면 교사와 학생 간의 분포 차이가 발생할 수 있으며, 이는 최종 결과의 정확성에 영향을 미칠 수 있습니다.
이러한 문제를 극복하기 위해 StarCoder2-15B-Instruct는 자체 검증 메커니즘을 도입했습니다. 이 메커니즘의 핵심 아이디어는 StarCoder2-15B 모델이 자연어 응답을 생성한 후 자체적으로 해당 테스트 케이스를 생성하도록 하는 것입니다. 이 과정은 개발자가 코드를 작성한 후 거치는 자체 테스트 과정과 유사합니다.
구체적으로 각 명령어에 대해 StarCoder2-15B는 자연어 응답과 해당 테스트 사례가 포함된 10개의 샘플을 생성합니다. 그런 다음 StarCoder2-15B-Instruct는 샌드박스 환경에서 이러한 테스트 사례를 실행하여 응답의 유효성을 확인합니다. 테스트 실행에 실패한 모든 샘플은 필터링됩니다.
이 엄격한 심사 과정을 거친 후 StarCoder2-15B-Instruct는 각 명령어의 테스트된 응답 중 하나를 무작위로 선택하여 최종 SFT 데이터 세트에 추가합니다. 프로세스 전반에 걸쳐 StarCoder2-15B-Instruct는 238k 명령에 대해 총 240만 개의 응답 샘플(명령당 10개 샘플)을 생성했습니다. 0.7의 샘플링 전략을 채택한 후 500,000개의 샘플이 실행 테스트를 성공적으로 통과했습니다.
데이터 세트의 다양성과 품질을 보장하기 위해 StarCoder2-15B-Instruct는 중복 제거 처리도 수행합니다. 결국 50,000개의 명령이 남았고 각 명령에는 무작위로 선택되고 테스트되고 검증된 고품질 응답이 포함되었습니다. 이러한 응답은 StarCoder2-15B-Instruct의 최종 SFT 데이터 세트를 구성하여 모델의 후속 교육 및 적용을 위한 견고한 기반을 제공합니다.
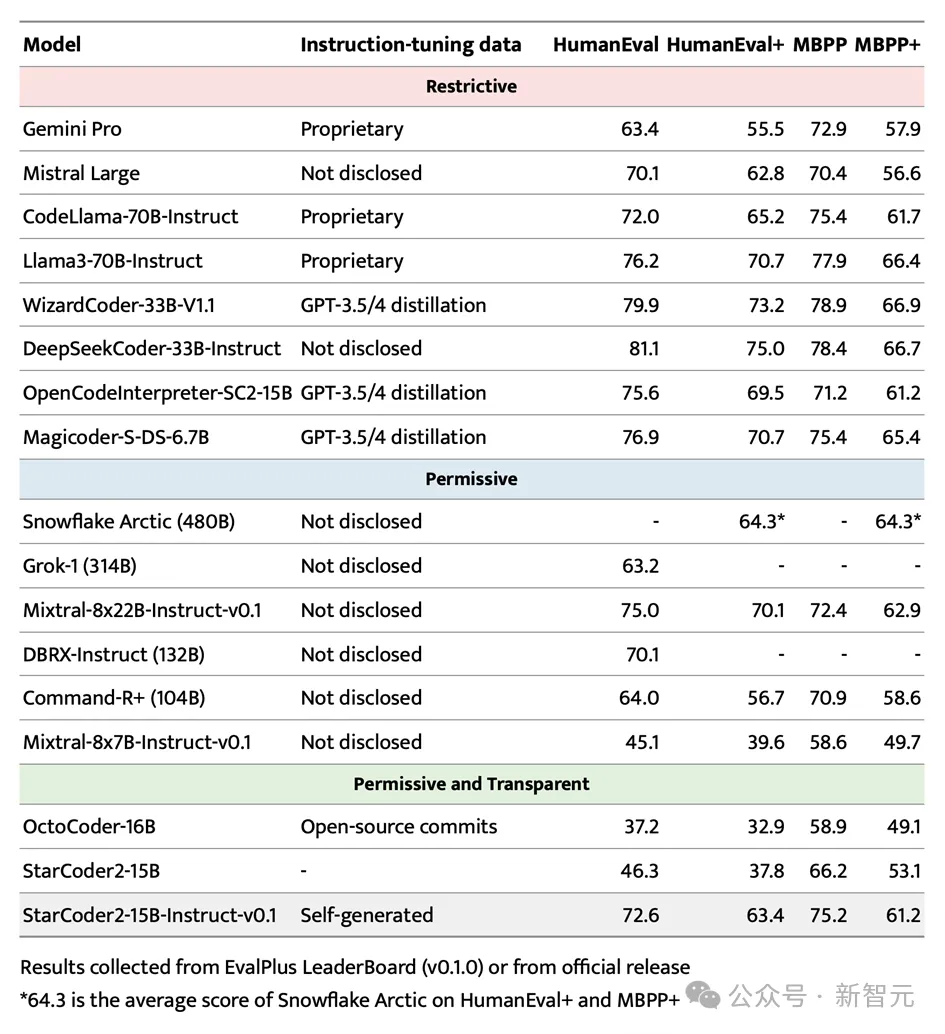
세간의 이목을 끄는 EvalPlus 벤치마크 테스트에서 StarCoder2-15B-Instruct는 성공적으로 두각을 나타내며 규모의 이점으로 인해 최고 성능의 자율 시스템이 되었습니다. . 제어 가능한 대형 모델.
더 큰 Grok-1 Command-R+ 및 DBRX를 능가할 뿐만 아니라 Snowflake Arctic 480B 및 Mixtral-8x22B-Instruct와 같은 업계 리더와도 일치합니다.
StarCoder2-15B-Instruct는 HumanEval 벤치마크에서 70점 이상의 점수를 획득한 최초의 대규모 독립 코드 모델이라는 점을 언급할 가치가 있습니다. 훈련 과정은 완전히 투명하며 데이터와 방법의 사용은 법률과 규정을 준수합니다. .
독립적으로 제어 가능한 코드 대형 모델 분야에서 StarCoder2-15B-Instruct는 이전 리더인 OctoCoder를 크게 능가하여 이 분야의 선두 위치를 입증했습니다.
Gemini Pro 및 Mistral Large와 같이 라이센스가 제한된 크고 강력한 모델과 비교해도 StarCoder2-15B-Instruct는 여전히 뛰어난 성능을 보여 CodeLlama-70B-Instruct와 동등합니다. 더욱 놀라운 점은 StarCoder2-15B-Instruct가 훈련을 위해 자체 생성 데이터에 전적으로 의존하지만 그 성능은 GPT-3.5/4 데이터 미세 조정을 기반으로 하는 OpenCodeInterpreter-SC2-15B와 비슷하다는 것입니다.
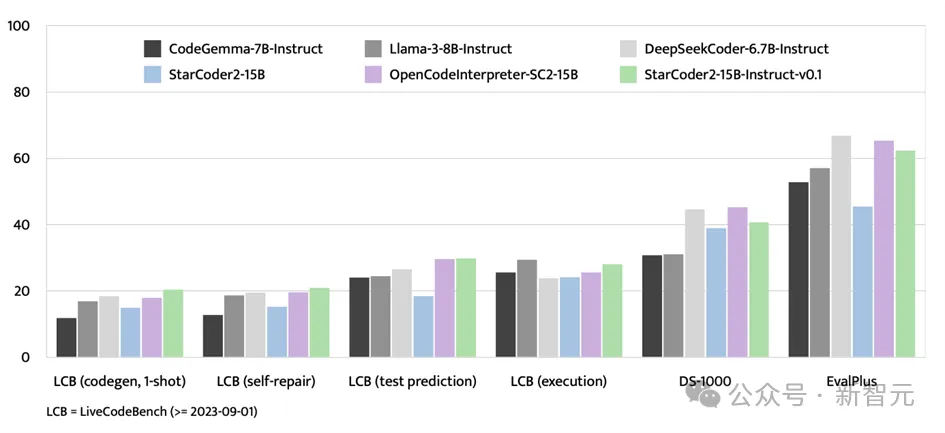
StarCoder2-15B-Instruct는 EvalPlus 벤치마크 테스트 외에도 LiveCodeBench 및 DS-1000과 같은 평가 플랫폼에서도 강력한 강점을 보여주었습니다.
LiveCodeBench는 2023년 9월 1일 이후에 나타나는 코딩 문제를 평가하는 데 중점을 두고 있으며 StarCoder2-15B-Instruct는 이 벤치마크에서 최고의 결과를 달성하고 GPT-4 데이터 -SC2-15B를 사용하여 미세 조정된 OpenCodeInterpreter보다 지속적으로 앞서 있습니다. -SC2-15B
DS-1000은 데이터 과학 작업에 중점을 두고 있지만 StarCoder2-15B-Instruct는 이 벤치마크에서 여전히 강력한 성능을 발휘하며 교육 데이터에서 상대적으로 적은 데이터 과학 문제를 보여줍니다.
StarCoder2-15B-Instruct-v0.1의 출시는 코드 모델 자체 조정 분야에서 연구원들의 발전을 의미합니다. 우수성 분야에서 중요한 단계가 이루어졌습니다. 이 모델의 성공적인 실행은 GPT-4와 같은 강력한 외부 교사 모델에 의존해야 했던 이전의 한계를 깨고 자체 튜닝을 통해 뛰어난 성능을 가진 코드 모델도 구축할 수 있음을 보여줍니다.
StarCoder2-15B-Instruct-v0.1의 핵심은 코드 학습 분야에서 자체 정렬 전략을 성공적으로 적용하는 데 있습니다. 이 전략은 모델의 성능을 향상시킬 뿐만 아니라 더 중요한 것은 모델에 더 큰 투명성과 해석 가능성을 제공한다는 것입니다. 이는 Snowflake-Arctic, Grok-1, Mixtral-8x22B, DBRX 및 CommandR+와 같은 다른 대형 모델과 극명한 대조를 이룹니다. 이 모델은 강력하지만 투명성 부족으로 인해 적용 범위와 신뢰성이 제한되는 경우가 많습니다.
더욱 만족스러운 점은 StarCoder2-15B-Instruct-v0.1이 데이터 세트와 데이터 수집 및 교육 프로세스를 포함한 전체 교육 프로세스를 완전히 오픈 소스로 만들었다는 것입니다. 이러한 움직임은 연구자들의 개방적인 정신을 보여줄 뿐만 아니라 이 분야의 향후 연구 개발을 위한 견고한 기반을 마련합니다.
StarCoder2-15B-Instruct-v0.1의 성공적인 실행이 더 많은 연구자들이 코드 모델 자체 조정 분야의 연구에 투자하도록 영감을 주고 이에 대한 기술 발전과 응용 프로그램 확장을 촉진할 것이라고 믿을 이유가 있습니다. 필드. 동시에 우리는 이 분야에서 더욱 혁신적인 결과가 계속해서 등장하여 인류 사회의 지능적 발전에 새로운 추진력을 불어넣을 것으로 기대합니다.
UIUC의 Zhang Lingming 선생님은 소프트웨어 공학, 프로그래밍 언어, 기계 학습의 교차점에서 깊은 성취를 이룬 학자입니다. 그가 이끄는 연구그룹은 오랫동안 대형 AI 모델을 기반으로 한 자동 소프트웨어 합성, 수리, 검증 연구와 머신러닝 시스템의 신뢰성 향상에 전념해 왔다.
최근에는 혁신적인 대규모 코드 모델과 테스트 벤치마크 데이터 세트를 다수 출시했으며, 대규모 모델 기반 소프트웨어 테스트 및 복구 기술 시리즈를 제안하는 데 앞장섰습니다. 동시에 여러 실제 소프트웨어 시스템에서 수천 개의 새로운 결함과 허점을 성공적으로 발견하여 소프트웨어 품질 향상에 크게 기여했습니다.
위 내용은 OpenAI 데이터가 필요하지 않습니다. 대규모 코드 모델 목록에 참여하세요! UIUC, StarCoder-15B-Instruct 출시의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



