고정밀 지역 수준 다중 모드 이해를 달성하기 위해 본 논문에서는 인간의 시각 인지 시스템을 시뮬레이션하는 동적 해상도 방식을 제안합니다.
이 기사의 저자는 중국과학원 LAMP 연구소 출신입니다. 제1저자는 2023년 중국과학원 박사과정 학생이고, 공동저자는 Liu입니다. Feng은 2020년 중국과학원 대학 직속 박사과정 학생입니다. 주요 연구 방향은 시각적 언어 모델과 시각적 객체 인식입니다.
DynRefer는 인간의 시각적 인지 과정을 시뮬레이션하여 지역 수준의 다중 모달 인식 기능을 크게 향상시킵니다. 인간 눈의 동적 해상도 메커니즘을 도입함으로써 DynRefer는 단일 모델로 영역 인식, 영역 속성 감지 및 영역 수준 캡션 작업을 동시에 완료하고 위의 모든 작업에서 SOTA 성능을 달성할 수 있습니다. 그 중 RefCOCOg 데이터 세트의 지역 수준 캡션 작업에서 115.7 CIDEr가 달성되었으며 이는 RegionGPT, GlaMM, Osprey, Alpha-CLIP 등과 같은 CVPR 2024 방법보다 훨씬 높습니다. 
- 논문 제목: DynRefer: Delving into Region-level Multi-modality Tasks via Dynamic Resolution
- 논문 링크: https://arxiv.org/abs/2405.16071
- 논문 코드: https ://github.com/callsys/DynRefer
지역 수준 다중 모달 작업은 지정된 이미지 영역을 인간 기본 설정과 일치하는 언어 설명으로 변환하는 데 전념합니다. 인간은 지역 수준의 다중 모드 작업을 완료할 때 해상도 적응 능력을 가지고 있습니다. 즉, 관심 영역은 고해상도이고 비주의 영역은 저해상도입니다. 그러나 현재의 지역 수준 다중 모드 대형 언어 모델은 고정 해상도 인코딩 방식을 채택하는 경우가 많습니다. 즉, 전체 이미지를 인코딩한 다음 RoI Align을 통해 지역 특징을 추출하는 것입니다. 이 접근 방식은 인간의 시각 인지 시스템에서 해상도 적응 능력이 부족하고, 인코딩 효율성과 관심 영역에 대한 능력이 낮습니다. 고정밀 지역 수준 다중 모드 이해를 달성하기 위해 아래 그림과 같이 인간의 시각 인지 시스템을 시뮬레이션하는 동적 해상도 체계를 제안합니다.
区 그림 1: 전통적인 지역적 다중 모드 방법(왼쪽)과 Dynrefer 방법(오른쪽)의 비교.
1. 동적 해상도 이미지를 시뮬레이션합니다(다중 뷰 구성). 주요 사전 학습된 시각적 언어 모델(CLIP)은 균일한 해상도 입력만 받을 수 있으므로 여러 개의 균일한 해상도 뷰를 구성하여 동적 해상도 이미지를 시뮬레이션합니다. 이미지는 참조 영역에서는 해상도가 높고 비참조 영역에서는 해상도가 낮습니다. 구체적인 프로세스는 그림 2에 나와 있습니다. 원본 이미지 x는 잘리고 여러 후보 뷰로 크기가 조정됩니다. 자르기 영역은
로 계산됩니다. 여기서 입니다. 여기서 는 참조 영역의 경계 상자를 나타내고, 는 전체 이미지의 크기를 나타내며, t는 보간 계수를 나타냅니다. 훈련 중에 응시 및 빠른 눈 움직임으로 인해 생성된 이미지를 시뮬레이션하기 위해 후보 뷰에서 n개의 뷰를 무작위로 선택합니다. 이러한 n개의 뷰는 보간 계수 t, 즉 에 해당합니다. 참조 영역(예: )만 포함된 뷰를 고정적으로 유지합니다. 이 관점은 모든 지역 다중 모드 작업에 중요한 지역 세부 정보를 보존하는 데 도움이 된다는 것이 실험적으로 입증되었습니다. ㅋㅋ 그림 2: DynRefer 훈련(상위) ) 및 추론(하단).
구체적인 프로세스는 그림 3에 나와 있습니다. 샘플링된 n개의 뷰는 고정된 CLIP을 통해 공간 특징으로 인코딩된 다음 RoI-Align 모듈에 의해 처리되어 영역 임베딩(예:
)을 얻습니다. 이는 그림 3의 왼쪽에 나와 있습니다. 이러한 영역 임베딩은 자르기, 크기 조정 및 RoI-Align으로 인해 발생하는 공간 오류로 인해 공간적으로 정렬되지 않습니다. 변형 가능한 컨볼루션 연산에서 영감을 받아 를 로 정렬하여 편향을 줄이는 정렬 모듈을 제안합니다. 여기서 는 참조 영역만 포함하는 뷰 인코딩의 영역 임베딩입니다. 각 영역 임베딩 에 대해 먼저 과 연결한 후 컨볼루셔널 레이어를 통해 2D 오프셋 맵을 계산합니다. 그런 다음 의 공간 특징이 2D 오프셋을 기반으로 리샘플링됩니다. 마지막으로, 정렬된 영역 임베딩은 채널 차원을 따라 연결되고 선형 레이어를 통해 융합됩니다. 출력은 시각적 리샘플링 모듈, 즉 Q-former를 통해 더욱 압축되어 원본 이미지 x(그림 3의 )의 참조 영역 의 지역 표현을 추출합니다. ㅋㅋ 그림 3: DynRefer 네트워크 구조
확률적 다중 뷰 임베딩 모듈에 의해 계산된 영역 표현
은 그림 3(오른쪽)과 같이 3개의 디코더 에 의해 디코딩되며 각각 3개의 다중 모달 작업에 의해 감독됩니다:
i ) 이미지 영역 레이블 세대. 우리는 지역 라벨 생성을 위해 경량 쿼리 기반 인식 디코더를 사용합니다. 디코더 는 그림 3(오른쪽)에 나와 있습니다. 태그 지정 프로세스는 태그를 쿼리로, 키와 값으로 사용하여 사전 정의된 태그의 신뢰도를 계산함으로써 완료됩니다. 인식 디코더를 감독하기 위해 실제 자막의 레이블을 구문 분석합니다. ii) 지역-텍스트 대조 학습. 지역 태그 디코더와 유사하게 디코더
는 쿼리 기반 인식 디코더로 정의됩니다. 디코더는 SigLIP 손실을 사용하여 감독된 자막과 지역 기능 간의 유사성 점수를 계산합니다. iii) 언어 모델링. 사전 훈련된 대규모 언어 모델을 사용하여 지역 표현을 언어 설명으로 변환합니다. 그림 4: 지역 수준 다중 모달 작업에 대한 듀얼 뷰(n=2) DynRefer 모델의 성능. 다양한 보간 계수 t에서 . 보기 1은 고정되어 있고() 보기 2는 무작위로 선택되거나 고정됩니다. 4. 추론 프로세스 중에 훈련된 DynRefer 모델은 동적 해상도의 이미지에 대해 다중 모드 작업을 수행합니다. 샘플링된 n개 뷰의 보간 계수 를 조정하면 동적 해상도 특성을 갖는 지역 표현을 얻을 수 있습니다. 다양한 동적 해상도에서 속성을 평가하기 위해 듀얼 뷰(n=2) DynRefer 모델을 교육하고 4가지 다중 모드 작업에 대해 평가했습니다. 그림 4의 곡선에서 볼 수 있듯이 속성 감지는 상황 정보가 없는 뷰에 대해 더 나은 결과를 얻습니다(). 이는 이러한 작업에 종종 상세한 지역 정보가 필요하다는 사실로 설명할 수 있습니다. 지역 수준 캡션 및 조밀한 캡션 작업의 경우 참조 지역을 완전히 이해하려면 상황이 풍부한 보기()가 필요합니다. 너무 많은 컨텍스트()가 포함된 보기는 지역과 관련 없는 정보를 너무 많이 도입하기 때문에 모든 작업의 성능을 저하시킨다는 점에 유의하는 것이 중요합니다. 작업 유형이 알려지면 작업 특성에 따라 적절한 보기를 샘플링할 수 있습니다. 작업 유형을 알 수 없는 경우 먼저 다양한 보간 계수 t, 에 따라 후보 뷰 세트를 구성합니다. 후보 세트에서 탐욕적 검색 알고리즘을 통해 n개의 뷰가 샘플링됩니다. 검색의 목적 함수는 다음과 같이 정의됩니다. 여기서 는 i번째 뷰의 보간 계수를 나타내고, 는 i번째 뷰를 나타내고, pHASH(・)는 지각 이미지 해시 함수를 나타내고, 는 XOR을 나타냅니다. 작업. 글로벌 관점에서 뷰의 정보를 비교하기 위해 "pHASH(・)" 함수를 사용하여 뷰를 공간 영역에서 주파수 영역으로 변환한 후 해시 코드로 인코딩합니다. 이 항목 에서는 중복된 정보가 너무 많이 도입되지 않도록 상황이 풍부한 보기의 가중치를 줄였습니다.
지역 자막 생성 작업에서 DynRefer는 RefCOCOg 및 VG 데이터 세트 모두에서 더 작은 모델(4.2B 대 7B)을 사용합니다. METEOR 및 CIDEr 지표는 RegionGPT, GlaMM, Alpha-CLIP 및 Osprey 등과 같은 CVPR 2024의 많은 방법을 크게 능가하여 DynRefer의 엄청난 성능 이점을 보여줍니다.
촘촘한 자막 생성 작업에서 VG1.2 데이터 세트에서 DynRefer는 이전 SOTA 방식인 GRiT에 비해 mAP를 7.1% 향상시켰습니다.
지역 속성 탐지 작업에서도 DynRefer가 SOTA 성능을 달성했습니다. Open Vocabulary Region Recognition
영역 인식 작업에서 DynRefer는 CVPR 24의 RegionGPT에 비해 mAP는 15%, 정확도는 8.8% 향상되었으며 ICLR 24의 ASM보다 mAP가 15.7% 더 높습니다.
- 라인 1-6: 고정 뷰보다 무작위 동적 멀티뷰가 더 좋습니다.
- 라인 6-10: 정보를 최대화하여 보기 선택이 무작위로 보기를 선택하는 것보다 낫습니다.
- 라인 10-13: 다중 작업 교육을 통해 더 나은 지역 표현을 배울 수 있습니다.
다음 그림은 DynRefer가 하나의 모델을 사용하여 지역 자막, 태그, 속성 및 카테고리를 동시에 출력할 수 있는 모습을 보여줍니다.
위 내용은 CVPR 2024 방법을 능가하는 DynRefer는 지역 수준 다중 모드 인식 작업에서 여러 SOTA를 달성합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!




 는 전체 이미지의 크기를 나타내며, t는 보간 계수를 나타냅니다. 훈련 중에 응시 및 빠른 눈 움직임으로 인해 생성된 이미지를 시뮬레이션하기 위해 후보 뷰에서 n개의 뷰를 무작위로 선택합니다. 이러한 n개의 뷰는 보간 계수 t, 즉
는 전체 이미지의 크기를 나타내며, t는 보간 계수를 나타냅니다. 훈련 중에 응시 및 빠른 눈 움직임으로 인해 생성된 이미지를 시뮬레이션하기 위해 후보 뷰에서 n개의 뷰를 무작위로 선택합니다. 이러한 n개의 뷰는 보간 계수 t, 즉  에 해당합니다. 참조 영역(예:
에 해당합니다. 참조 영역(예:  )만 포함된 뷰를 고정적으로 유지합니다. 이 관점은 모든 지역 다중 모드 작업에 중요한 지역 세부 정보를 보존하는 데 도움이 된다는 것이 실험적으로 입증되었습니다.
)만 포함된 뷰를 고정적으로 유지합니다. 이 관점은 모든 지역 다중 모드 작업에 중요한 지역 세부 정보를 보존하는 데 도움이 된다는 것이 실험적으로 입증되었습니다. 


 는 참조 영역만 포함하는 뷰 인코딩의 영역 임베딩입니다. 각 영역 임베딩
는 참조 영역만 포함하는 뷰 인코딩의 영역 임베딩입니다. 각 영역 임베딩 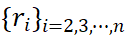 에 대해 먼저
에 대해 먼저  과 연결한 후 컨볼루셔널 레이어를 통해 2D 오프셋 맵을 계산합니다. 그런 다음
과 연결한 후 컨볼루셔널 레이어를 통해 2D 오프셋 맵을 계산합니다. 그런 다음  의 공간 특징이 2D 오프셋을 기반으로 리샘플링됩니다. 마지막으로, 정렬된 영역 임베딩은 채널 차원을 따라 연결되고 선형 레이어를 통해 융합됩니다. 출력은 시각적 리샘플링 모듈, 즉 Q-former를 통해 더욱 압축되어 원본 이미지 x(그림 3의
의 공간 특징이 2D 오프셋을 기반으로 리샘플링됩니다. 마지막으로, 정렬된 영역 임베딩은 채널 차원을 따라 연결되고 선형 레이어를 통해 융합됩니다. 출력은 시각적 리샘플링 모듈, 즉 Q-former를 통해 더욱 압축되어 원본 이미지 x(그림 3의  )의 참조 영역
)의 참조 영역  의 지역 표현을 추출합니다.
의 지역 표현을 추출합니다. 




 을 사용하여 지역 표현
을 사용하여 지역 표현 을 언어 설명으로 변환합니다.
을 언어 설명으로 변환합니다. 


 . 보기 1은 고정되어 있고(
. 보기 1은 고정되어 있고( ) 보기 2는 무작위로 선택되거나 고정됩니다.
) 보기 2는 무작위로 선택되거나 고정됩니다.  를 조정하면 동적 해상도 특성을 갖는 지역 표현을 얻을 수 있습니다. 다양한 동적 해상도에서 속성을 평가하기 위해 듀얼 뷰(n=2) DynRefer 모델을 교육하고 4가지 다중 모드 작업에 대해 평가했습니다. 그림 4의 곡선에서 볼 수 있듯이 속성 감지는 상황 정보가 없는 뷰에 대해 더 나은 결과를 얻습니다(
를 조정하면 동적 해상도 특성을 갖는 지역 표현을 얻을 수 있습니다. 다양한 동적 해상도에서 속성을 평가하기 위해 듀얼 뷰(n=2) DynRefer 모델을 교육하고 4가지 다중 모드 작업에 대해 평가했습니다. 그림 4의 곡선에서 볼 수 있듯이 속성 감지는 상황 정보가 없는 뷰에 대해 더 나은 결과를 얻습니다( ). 이는 이러한 작업에 종종 상세한 지역 정보가 필요하다는 사실로 설명할 수 있습니다. 지역 수준 캡션 및 조밀한 캡션 작업의 경우 참조 지역을 완전히 이해하려면 상황이 풍부한 보기(
). 이는 이러한 작업에 종종 상세한 지역 정보가 필요하다는 사실로 설명할 수 있습니다. 지역 수준 캡션 및 조밀한 캡션 작업의 경우 참조 지역을 완전히 이해하려면 상황이 풍부한 보기( )가 필요합니다. 너무 많은 컨텍스트(
)가 필요합니다. 너무 많은 컨텍스트( )가 포함된 보기는 지역과 관련 없는 정보를 너무 많이 도입하기 때문에 모든 작업의 성능을 저하시킨다는 점에 유의하는 것이 중요합니다. 작업 유형이 알려지면 작업 특성에 따라 적절한 보기를 샘플링할 수 있습니다. 작업 유형을 알 수 없는 경우 먼저 다양한 보간 계수 t,
)가 포함된 보기는 지역과 관련 없는 정보를 너무 많이 도입하기 때문에 모든 작업의 성능을 저하시킨다는 점에 유의하는 것이 중요합니다. 작업 유형이 알려지면 작업 특성에 따라 적절한 보기를 샘플링할 수 있습니다. 작업 유형을 알 수 없는 경우 먼저 다양한 보간 계수 t,  에 따라 후보 뷰 세트를 구성합니다. 후보 세트에서 탐욕적 검색 알고리즘을 통해 n개의 뷰가 샘플링됩니다. 검색의 목적 함수는 다음과 같이 정의됩니다.
에 따라 후보 뷰 세트를 구성합니다. 후보 세트에서 탐욕적 검색 알고리즘을 통해 n개의 뷰가 샘플링됩니다. 검색의 목적 함수는 다음과 같이 정의됩니다.  여기서
여기서  는 i번째 뷰의 보간 계수를 나타내고,
는 i번째 뷰의 보간 계수를 나타내고,  는 i번째 뷰를 나타내고, pHASH(・)는 지각 이미지 해시 함수를 나타내고,
는 i번째 뷰를 나타내고, pHASH(・)는 지각 이미지 해시 함수를 나타내고,  는 XOR을 나타냅니다. 작업. 글로벌 관점에서 뷰의 정보를 비교하기 위해 "pHASH(・)" 함수를 사용하여 뷰를 공간 영역에서 주파수 영역으로 변환한 후 해시 코드로 인코딩합니다. 이 항목
는 XOR을 나타냅니다. 작업. 글로벌 관점에서 뷰의 정보를 비교하기 위해 "pHASH(・)" 함수를 사용하여 뷰를 공간 영역에서 주파수 영역으로 변환한 후 해시 코드로 인코딩합니다. 이 항목  에서는 중복된 정보가 너무 많이 도입되지 않도록 상황이 풍부한 보기의 가중치를 줄였습니다.
에서는 중복된 정보가 너무 많이 도입되지 않도록 상황이 풍부한 보기의 가중치를 줄였습니다. 























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



