핵심 개념
- 주요지수 / 보조지수
- 클러스터형 인덱스/비클러스터형 인덱스
- 테이블 조회/인덱스 커버
- 색인 푸시다운
- 복합 색인 / 가장 왼쪽 접두사 매칭
- 접두사 색인
- 설명
1. [지수 정의]
1. 지수 정의
데이터 자체 외에도 데이터베이스 시스템은 특정 검색 알고리즘을 만족하는 데이터 구조를 유지합니다. 이러한 구조는 특정 방식으로 데이터를 참조(지시)하여 고급 검색 알고리즘을 구현할 수 있습니다. 이러한 데이터 구조는 인덱스입니다.
2. 인덱스의 데이터 구조
- B-트리 / B+ 트리(MySQL의 InnoDB 엔진은 B+ 트리를 기본 인덱스 구조로 사용합니다)
- HASH 테이블
- 정렬된 배열
3. B 트리 대신 B+ 트리를 선택하는 이유
- B-트리 구조: 레코드가 트리 노드에 저장됩니다.

- B+ 트리 구조: 트리의 리프 노드에만 레코드가 저장됩니다.
- 데이터 크기가 1KB이고 인덱스 크기가 16B이고 데이터베이스가 디스크 데이터 페이지를 사용하고 기본 디스크 페이지 크기가 16K라고 가정하면 동일한 세 가지 I/O 작업이 생성됩니다.
B-트리는 16*16*16=4096 레코드를 가져올 수 있습니다.
B+ 트리는 1000*1000*1000=10억개의 레코드를 가져올 수 있습니다.
2. [인덱스 종류]
1. 기본키지수와 보조지수
-
기본 키 인덱스: 인덱스의 리프 노드는 데이터 행입니다.
-
보조 인덱스: 인덱스의 리프 노드는 KEY 필드에 기본 키 인덱스를 더한 것입니다. 따라서 보조 인덱스를 통해 쿼리할 경우 먼저 기본 키 값을 찾은 다음 InnoDB는 기본 키 인덱스를 통해 해당 데이터 블록을 찾습니다.
-
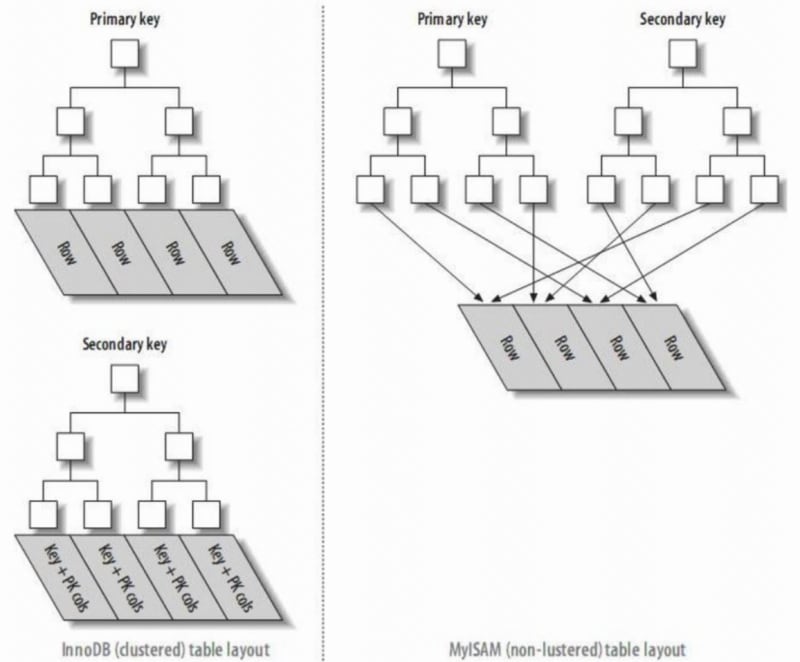
InnoDB에서 기본 인덱스 파일은 클러스터형 인덱스라고 하는 데이터 행을 직접 저장하는 반면, 보조 인덱스는 기본 키 참조를 가리킵니다.
-
MyISAM에서는 기본 인덱스와 보조 인덱스 모두 물리적 행(디스크 위치)을 가리킵니다.
2. 클러스터형 인덱스와 비클러스터형 인덱스
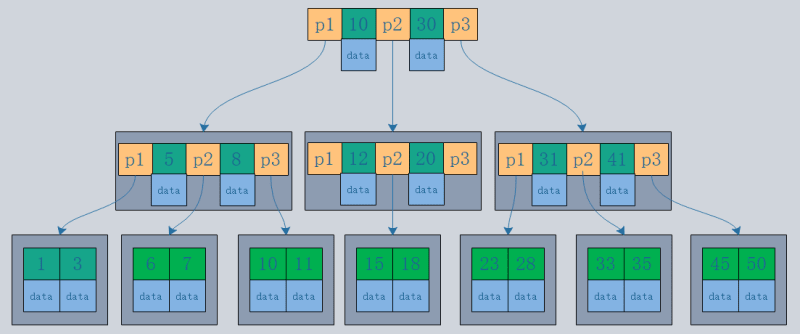
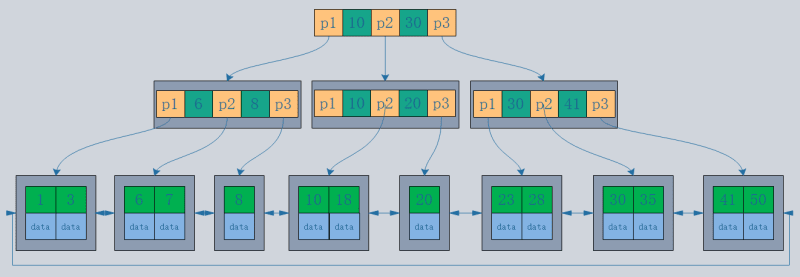
- 클러스터형 인덱스는 하나 이상의 지정된 열 값을 기준으로 정렬되도록 디스크의 실제 데이터를 재구성합니다. 특징은 데이터의 저장 순서와 인덱스 순서가 일치한다는 점이다. 일반적으로 기본 키는 기본적으로 클러스터형 인덱스를 생성하며, 테이블은 하나의 클러스터형 인덱스만 허용합니다(이유: 데이터는 한 순서로만 저장할 수 있음). 이미지에서 볼 수 있듯이 InnoDB의 기본 인덱스와 보조 인덱스는 클러스터형 인덱스입니다.
- 클러스터형 인덱스의 리프 노드가 데이터 레코드인 것에 비해 비클러스터형 인덱스의 리프 노드는 데이터 레코드에 대한 포인터입니다. 가장 큰 차이점은 데이터 레코드의 순서가 인덱스 순서와 일치하지 않는다는 점입니다.
3. Clustered Index의 장점과 단점
- 이점: 기본 키로 항목을 쿼리할 때 테이블 조회를 수행할 필요가 없습니다(데이터는 기본 키 노드 아래에 있음).
- 단점: 불규칙한 데이터 삽입으로 페이지 분할이 자주 발생할 수 있습니다.
3. [확장지수 개념]
1. 테이블 조회
테이블 조회의 개념에는 기본 키 인덱스 쿼리와 기본 키가 아닌 인덱스 쿼리의 차이가 있습니다.
- ID=500인 T에서 *를 선택하는 쿼리인 경우 기본 키 쿼리는 ID 트리만 검색하면 됩니다.
- 쿼리가 k=5인 T에서 *를 선택하는 경우 비기본 키 인덱스 쿼리는 먼저 k 인덱스 트리를 검색하여 ID 값 500을 얻은 다음 ID 인덱스 트리를 다시 검색해야 합니다.
- 기본 키가 아닌 인덱스에서 다시 기본 키 인덱스로 이동하는 과정을 테이블 조회라고 합니다.
기본 키가 아닌 인덱스를 기반으로 하는 쿼리에는 추가 인덱스 트리를 스캔해야 합니다. 따라서 애플리케이션에서는 기본 키 쿼리를 사용하도록 노력해야 합니다. 저장 공간의 관점에서 볼 때, 비기본 키 인덱스 트리의 리프 노드에는 기본 키 값이 저장되므로 기본 키 필드를 최대한 짧게 유지하는 것이 좋습니다. 이렇게 하면 비기본 키 인덱스 트리의 리프 노드가 더 작아지고 비기본 키 인덱스가 더 적은 공간을 차지합니다. 일반적으로 비기본 키 인덱스가 차지하는 공간을 최소화하기 위해 자동 증가 기본 키를 생성하는 것이 좋습니다.
2. 색인 표지
- WHERE 절 조건이 기본 키가 아닌 인덱스인 경우 쿼리는 먼저 비기본 키 인덱스를 통해 기본 키 인덱스를 찾습니다(기본 키는 기본이 아닌 키의 리프 노드에 위치함). 키 인덱스 검색 트리), 기본 키 인덱스를 통해 쿼리 내용을 찾습니다. 이 과정에서 기본키 인덱스 트리로 다시 이동하는 것을 테이블 조회라고 합니다.
- 그러나 쿼리 내용이 기본 키 값인 경우에는 테이블 조회 없이 쿼리 결과를 바로 제공할 수 있습니다. 즉, 기본 키가 아닌 인덱스는 이미 이 쿼리에서 쿼리 요구 사항을 "포함"했으므로 이를 포함 인덱스라고 합니다.
-
커버링 인덱스는 기본 인덱스에 대한 테이블 조회 없이 바로 보조 인덱스에서 쿼리 결과를 얻을 수 있어 검색 횟수를 줄이거나(보조 인덱스 트리에서 클러스터형 인덱스 트리로 이동할 필요 없이) 검색 횟수를 줄이거나 IO 작업(보조 인덱스 트리는 디스크에서 한 번에 더 많은 노드를 로드할 수 있음)으로 성능이 향상됩니다.
3. 종합지수
복합 인덱스는 테이블의 여러 열을 인덱싱하는 것을 의미합니다.
시나리오 1:
복합 인덱스(a, b)는 a, b로 정렬됩니다(먼저 a로 정렬하고, a가 같으면 b로 정렬). 따라서 다음 명령문은 복합 인덱스를 직접 사용하여 결과를 얻을 수 있습니다(사실 가장 왼쪽 접두사 원칙을 사용합니다).
- a=xxx;인 경우 xxx에서 … 선택
- a=xxx 순서가 b인 xxx에서 … 선택;
다음 문은 복합 쿼리를 사용할 수 없습니다.
시나리오 2:
복합 인덱스(a, b, c)의 경우 다음 문은 복합 인덱스를 통해 직접 결과를 얻을 수 있습니다.
- a=xxx 순서가 b인 xxx에서 … 선택;
- a=xxx이고 b=xxx인 xxx에서 c로 순서대로 ...를 선택합니다.
다음 문은 복합 인덱스를 사용할 수 없으며 파일 정렬 작업이 필요합니다.
- a=xxx가 c로 주문되는 xxx에서 … 선택;
요약:
4. 가장 왼쪽 접두사 원칙
위의 복합지수 예시를 보면 가장 왼쪽 접두사의 원리를 이해할 수 있습니다.
- 색인의 전체 정의뿐만 아니라 가장 왼쪽 접두사만 충족하면 검색 속도를 높이는 데 사용할 수 있습니다. 이 가장 왼쪽 접두사는 복합 인덱스의 가장 왼쪽 N 필드이거나 문자열 인덱스의 가장 왼쪽 M 문자일 수 있습니다.
레코드를 찾고 중복 인덱스 정의를 방지하려면 인덱스의 "가장 왼쪽 접두사" 원칙을 사용하세요.-
따라서 복합 인덱스를 정의할 때 가장 왼쪽 접두사 원칙을 바탕으로 인덱스 내 필드 순서를 고려하는 것이 중요합니다! 평가 기준은 인덱스의 재사용성이다. 예를 들어 (a, b)에 이미 인덱스가 있는 경우 일반적으로 a에 별도의 인덱스를 만들 필요는 없습니다.
-
5. 인덱스 푸시다운
MySQL 5.6에서는
인덱스 순회 중 인덱스에 포함된 필드를 기준으로 조건에 맞지 않는 레코드를 필터링하여 테이블 조회 횟수를 줄일 수 있는 인덱스 푸시다운 최적화를 도입했습니다.
CREATE TABLE `test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Auto-increment primary key',
`age` int(11) NOT NULL DEFAULT '0',
`name` varchar(255) CHARACTER SET utf8 NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
로그인 후 복사
-
SELECT * 이름이 'Chen%'과 같은 사용자의 가장 왼쪽 접두사 원칙, idx_name_age 인덱스 누르기
-
SELECT * 이름이 'Chen%'이고 나이가 20인 사용자로부터
- 5.6 이전 버전에서는 먼저 이름 인덱스를 기준으로 2개의 레코드를 일치시키고(이 시점에서는 age=20 조건 무시) 해당하는 2개의 ID를 찾아 테이블 조회를 수행한 다음 age=20을 기준으로 필터링했습니다.
- 버전 5.6 이후에는 인덱스 푸시다운이 도입되었습니다. 이름을 기준으로 2개의 레코드를 일치시킨 후 테이블 조회를 수행하기 전에 age=20 조건을 무시하지 않고 테이블 조회 전 연령을 기준으로 필터링합니다. 이 인덱스 푸시다운을 통해 테이블 조회 횟수를 줄이고 쿼리 성능을 향상시킬 수 있습니다.
6. 접두사 색인
색인이 긴 문자 시퀀스인 경우 메모리를 많이 차지하고 속도가 느려질 수 있습니다. 이 경우 접두사 인덱스를 사용할 수 있습니다. 전체 값을 인덱싱하는 대신 처음 몇 문자를 인덱싱하여 공간을 절약하고 좋은 성능을 얻습니다. 접두사 색인은 색인의 처음 몇 글자를 사용합니다. 하지만 인덱스 중복률을 줄이기 위해서는 접두어 인덱스의 고유성을 평가해야 합니다.
- 먼저 현재 문자열 필드의 고유성 비율을 계산합니다. 테스트에서 1.0*count(고유 이름)/count(*)를 선택합니다.
- 그런 다음 다양한 접두사의 고유성 비율을 계산합니다.
-
이름의 첫 번째 문자를 접두사 인덱스로 테스트하여 1.0*count(distinct left(name,1))/count(*) 를 선택하세요
-
접두사 인덱스로 이름의 처음 두 문자에 대한 테스트에서 1.0*count(distinct left(name,2))/count(*) 를 선택하세요
- ...
- left(str, n)이 크게 증가하지 않는 경우 접두사 인덱스 컷오프 값으로 n을 선택합니다.
- 인덱스 변경 테이블 만들기 test add key(name(n));
4. [인덱스 보기]
색인을 추가한 후 어떻게 보나요? 또는 명령문 실행 속도가 느린 경우 어떻게 문제를 해결합니까?
Explain은 일반적으로 인덱스가 유효한지 확인하는 데 사용됩니다.
느린 쿼리 로그를 얻은 후 어떤 명령문이 느린지 관찰하세요. 명령문 앞에 explain을 추가하고 다시 실행하십시오. Explain은 쿼리에 플래그를 설정하여 명령문을 실행하는 대신 실행 계획의 각 단계에 대한 정보를 반환하도록 합니다. 실행 계획의 각 부분과 실행을 보여주는 하나 이상의 정보 행을 반환합니다. 주문하세요.
Explain이 반환한 중요 필드:
-
type : 검색방법을 나타냅니다 (full table scan 또는 index scan)
- 키: 사용된 인덱스 필드, 사용되지 않으면 null
유형 필드 설명:
- ALL: 전체 테이블 스캔
- 인덱스: 전체 인덱스 스캔
- 범위: 인덱스 범위 스캔
- ref: 고유하지 않은 인덱스 스캔
- eq_ref: 고유 인덱스 스캔
위 내용은 초보자를 위한 MySQL 데이터베이스 인덱스 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



