

단일 저자 논문, Google은 조밀한 피드포워드 및 희박한 MoE를 능가하는 수백만 개의 전문가 혼합물을 제안합니다.
Jul 17, 2024 pm 02:34 PM계산 효율성을 유지하면서 Transformer를 더욱 확장할 수 있는 잠재력을 활용하세요.



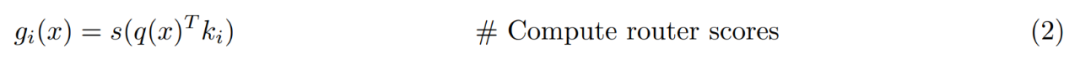



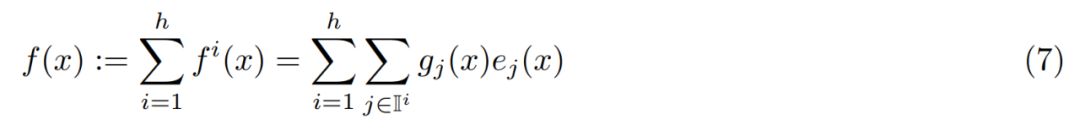


-
Curation Corpus Lambada Pile Wikitext 사전 훈련 데이터 세트 C4
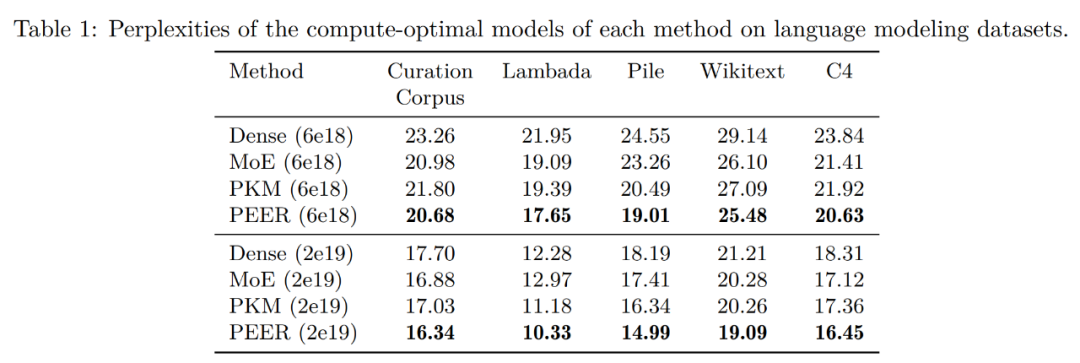
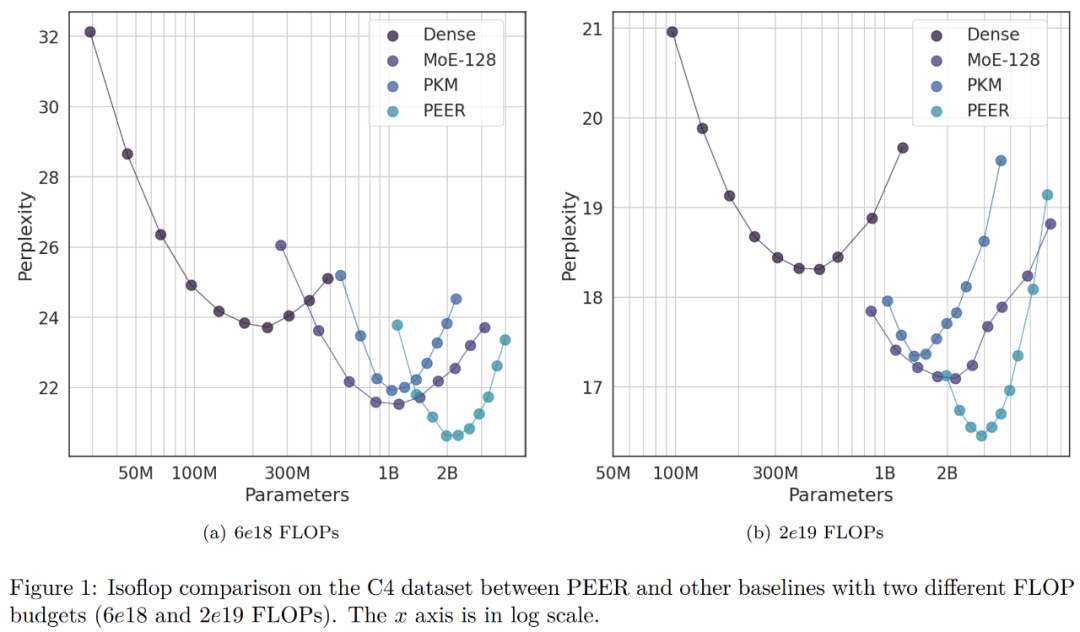




위 내용은 단일 저자 논문, Google은 조밀한 피드포워드 및 희박한 MoE를 능가하는 수백만 개의 전문가 혼합물을 제안합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

인기 기사


인기 기사

뜨거운 기사 태그

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7281
7281
 9
1622
14
1341
46
1258
25
1205
29
9
1622
14
1341
46
1258
25
1205
29

 RLHF에서 DPO, TDPO까지 대규모 모델 정렬 알고리즘은 이미 '토큰 수준'입니다.
Jun 24, 2024 pm 03:04 PM
RLHF에서 DPO, TDPO까지 대규모 모델 정렬 알고리즘은 이미 '토큰 수준'입니다.
Jun 24, 2024 pm 03:04 PM
RLHF에서 DPO, TDPO까지 대규모 모델 정렬 알고리즘은 이미 '토큰 수준'입니다.
 OpenAI Super Alignment Team의 사후 작업: 두 개의 대형 모델이 게임을 하고 출력이 더 이해하기 쉬워졌습니다.
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment Team의 사후 작업: 두 개의 대형 모델이 게임을 하고 출력이 더 이해하기 쉬워졌습니다.
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment Team의 사후 작업: 두 개의 대형 모델이 게임을 하고 출력이 더 이해하기 쉬워졌습니다.
 오픈 소스 AI 소프트웨어 엔지니어 목록의 1위인 UIUC의 에이전트 없는 솔루션은 SWE 벤치의 실제 프로그래밍 문제를 쉽게 해결합니다.
Jul 17, 2024 pm 10:02 PM
오픈 소스 AI 소프트웨어 엔지니어 목록의 1위인 UIUC의 에이전트 없는 솔루션은 SWE 벤치의 실제 프로그래밍 문제를 쉽게 해결합니다.
Jul 17, 2024 pm 10:02 PM
오픈 소스 AI 소프트웨어 엔지니어 목록의 1위인 UIUC의 에이전트 없는 솔루션은 SWE 벤치의 실제 프로그래밍 문제를 쉽게 해결합니다.
 ControlNet의 저자가 또 다른 히트를 쳤습니다! 이틀 만에 14,000개의 별을 획득하여 그림에서 그림을 생성하는 전체 과정
Jul 17, 2024 am 01:56 AM
ControlNet의 저자가 또 다른 히트를 쳤습니다! 이틀 만에 14,000개의 별을 획득하여 그림에서 그림을 생성하는 전체 과정
Jul 17, 2024 am 01:56 AM
ControlNet의 저자가 또 다른 히트를 쳤습니다! 이틀 만에 14,000개의 별을 획득하여 그림에서 그림을 생성하는 전체 과정
 무제한 비디오 생성, 계획 및 의사결정, 다음 토큰 예측의 확산 강제 통합 및 전체 시퀀스 확산
Jul 23, 2024 pm 02:05 PM
무제한 비디오 생성, 계획 및 의사결정, 다음 토큰 예측의 확산 강제 통합 및 전체 시퀀스 확산
Jul 23, 2024 pm 02:05 PM
무제한 비디오 생성, 계획 및 의사결정, 다음 토큰 예측의 확산 강제 통합 및 전체 시퀀스 확산
 리만 가설의 중요한 돌파구! 타오저쉬안(Tao Zhexuan)은 MIT와 옥스퍼드의 새로운 논문을 적극 추천했으며, 37세의 필즈상 수상자도 참여했다.
Aug 05, 2024 pm 03:32 PM
리만 가설의 중요한 돌파구! 타오저쉬안(Tao Zhexuan)은 MIT와 옥스퍼드의 새로운 논문을 적극 추천했으며, 37세의 필즈상 수상자도 참여했다.
Aug 05, 2024 pm 03:32 PM
리만 가설의 중요한 돌파구! 타오저쉬안(Tao Zhexuan)은 MIT와 옥스퍼드의 새로운 논문을 적극 추천했으며, 37세의 필즈상 수상자도 참여했다.
 arXiv 논문은 '연발'로 게시될 수 있습니다. Stanford alphaXiv 토론 플랫폼은 온라인이며 LeCun은 이를 좋아합니다.
Aug 01, 2024 pm 05:18 PM
arXiv 논문은 '연발'로 게시될 수 있습니다. Stanford alphaXiv 토론 플랫폼은 온라인이며 LeCun은 이를 좋아합니다.
Aug 01, 2024 pm 05:18 PM
arXiv 논문은 '연발'로 게시될 수 있습니다. Stanford alphaXiv 토론 플랫폼은 온라인이며 LeCun은 이를 좋아합니다.
 Axiom 교육을 통해 LLM은 인과 추론을 학습할 수 있습니다. 6,700만 개의 매개변수 모델은 1조 매개변수 수준 GPT-4와 비슷합니다.
Jul 17, 2024 am 10:14 AM
Axiom 교육을 통해 LLM은 인과 추론을 학습할 수 있습니다. 6,700만 개의 매개변수 모델은 1조 매개변수 수준 GPT-4와 비슷합니다.
Jul 17, 2024 am 10:14 AM
Axiom 교육을 통해 LLM은 인과 추론을 학습할 수 있습니다. 6,700만 개의 매개변수 모델은 1조 매개변수 수준 GPT-4와 비슷합니다.
