AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
이 기사의 주요 저자는 Huang Yichong입니다. Huang Yichong은 하얼빈 공과대학교 소셜 컴퓨팅 및 정보 검색 연구 센터의 박사 과정 학생이자 Pengcheng 연구소의 인턴입니다. 그는 Qin Bing 교수와 Feng Xiaocheng 교수 밑에서 공부하고 있습니다. 연구 방향에는 대형 언어 모델 앙상블 학습 및 다중 언어 대형 모델이 포함되며, 관련 논문은 최고의 자연어 처리 컨퍼런스인 ACL, EMNLP 및 COLING에 게재되었습니다. 대형 언어 모델이 놀라운 언어 지능을 입증함에 따라 주요 AI 기업들이 자체 대형 모델을 출시했습니다. 이러한 대형 모델은 일반적으로 다양한 분야와 작업에서 고유한 강점을 가지고 있습니다. 이를 통합하여 상호 보완적인 잠재력을 활용하는 방법은 AI 연구의 주요 주제가 되었습니다. 최근 하얼빈 공과대학과 펑청 연구소의 연구원들은 '훈련이 필요 없는 이종 대형 모델 통합 학습 프레임워크' DeePEn을 제안했습니다. 여러 모델에서 생성된 응답을 필터링하고 융합하기 위해 외부 모듈을 훈련하는 이전 방법과 달리 DeePEn은 디코딩 프로세스 중에 여러 모델 출력의 확률 분포를 융합하고 각 단계의 출력 토큰을 공동으로 결정합니다. 이에 비해 이 방법은 모든 모델 조합에 신속하게 적용할 수 있을 뿐만 아니라 통합 모델이 서로의 내부 표현(확률 분포)에 액세스할 수 있게 하여 보다 심층적인 모델 협업을 가능하게 합니다. 결과는 DeePEn이 여러 공개 데이터 세트에서 상당한 개선을 달성하여 대형 모델의 성능 경계를 효과적으로 확장할 수 있음을 보여줍니다. 
- 논문 제목: Ensemble Learning for Heterogeneous LargeLanguage Models with Deep Parallel Collaboration
- 논문 주소: https://arxiv.org/abs/2404.12715
- 코드 주소: https://github.com/OrangeInSouth/DeePEn
이종 대형 모델 통합의 핵심 어려움은 모델 간의 어휘 차이 문제를 해결하는 방법입니다. 이를 위해 DeePEn은 상대 표현 이론을 기반으로 여러 모델 어휘 간의 공유 토큰으로 구성된 통일된 상대 표현 공간을 구축합니다. 디코딩 단계에서 DeePEn은 융합을 위해 다양한 대형 모델에서 출력된 확률 분포를 이 공간에 매핑합니다. 전체 과정에서 매개변수 교육이 필요하지 않습니다. 아래 이미지는 DeePEn의 방법을 보여줍니다. 앙상블에 대한 N 모델이 주어지면 DeePEn은 먼저 변환 행렬(즉, 상대 표현 행렬)을 구축하여 여러 이질적인 절대 공간의 확률 분포를 통합된 상대 공간으로 매핑합니다. 각 디코딩 단계에서 모든 모델은 순방향 계산을 수행하고 N개의 확률 분포를 출력합니다. 이러한 분포는 상대 공간에 매핑되어 집계됩니다. 마지막으로 집계 결과는 다음 토큰을 결정하기 위해 일부 모델(마스터 모델)의 절대 공간으로 다시 변환됩니다.
ㅋㅋ ~ 그림 1: 회로도. 그 중, 어휘에 포함된 각 토큰과 모델 간 공유되는 앵커 토큰 간의 단어 임베딩 유사도를 계산하여 상대 표현 변환 행렬을 구한다.
모델이 주어지면 DeePEn은 먼저 모든 모델 어휘의 교차점, 즉 공유 어휘를 찾습니다.
, 그리고 하위 집합 A⊆C를 추출하거나 모든 공유 단어를 앵커 단어 집합 A=C로 사용합니다. 각 모델
에 대해 DeePEn은 어휘의 각 토큰과 앵커 토큰 간의 임베딩 유사성을 계산하여 상대 표현 행렬을 얻습니다. 마지막으로, 이상치 단어의 상대 표현 저하 문제를 극복하기 위해 논문 작성자는 상대 표현 행렬에 대해 행 정규화를 수행하고 행렬의 각 행에 대해 소프트맥스 연산을 수행하여 정규화된 상대 표현 행렬
를 출력하면 DeePEn은 정규화된 상대 표현 행렬을 사용하여
모든 상대 표현의 가중 평균을 수행하여 집계된 상대 표현을 얻습니다. 여기서 는 모델의 협업 가중치입니다. 저자는 공동 가중치 값을 결정하기 위해 두 가지 방법을 시도했습니다. (1) 모든 모델에 동일한 가중치를 사용하는 DeePEn-Avg, (2) 검증 세트 성능에 따라 각 모델의 가중치를 비례적으로 설정하는 DeePEn-Adapt.
집계된 상대 표현을 기반으로 다음 토큰을 결정하기 위해 DeePEn은 이를 상대 공간에서 다시 메인 모델의 절대 공간(개발 세트에서 가장 성능이 좋은 모델)으로 변환합니다. ). 이러한 역변환을 달성하기 위해 DeePEn은 상대 표현이 집계된 상대 표현과 동일한 절대 표현을 찾기 위해 검색 기반 전략을 채택합니다.
여기서 는 모델의 절대 공간을 나타내고 거리 간의 상대적 손실 함수(KL 발산)를 측정한 것입니다. DeePEn은 절대 표현 과 관련하여 손실 함수의 기울기 를 활용하여 검색 프로세스를 안내하고 검색을 반복적으로 수행합니다. 특히 DeePEn은 검색 시작점을 마스터 모델의 원래 절대 표현으로 초기화하고 업데이트합니다.
여기서 θ는 상대 앙상블 학습률이라는 하이퍼파라미터이고, T는 검색 반복 단계 수입니다. 마지막으로 업데이트된 절대 표현을 사용하여 다음 단계에서 출력할 토큰을 결정합니다.
표 1: 주요 실험 결과. 첫 번째 부분은 단일 모델의 성능, 두 번째 부분은 각 데이터 세트에 대한 상위 2개 모델의 앙상블 학습, 세 번째 부분은 상위 4개 모델의 통합입니다. 실험을 통해 논문의 저자는 다음과 같은 결론에 도달했습니다. (1) 대형 모델은 다양한 작업에 고유한 강점을 가지고 있습니다. 표 1에서 볼 수 있듯이 다양한 데이터 세트에서 다양한 대규모 모델의 성능에는 상당한 차이가 있습니다. 예를 들어 LLaMA2-13B는 TriviaQA 및 NQ 데이터 세트에서 가장 높은 결과를 얻었지만 다른 4개 작업에서는 상위 4위 안에 들지 못했습니다. (2) 분배 융합은 다양한 데이터 세트에서 지속적인 개선을 달성했습니다. 표 1에서 볼 수 있듯이 DeePEn-Avg와 DeePEn-Adapt는 모든 데이터 세트에서 성능 향상을 달성했습니다. GSM8K에서는 투표와 결합하여 +11.35의 성능 향상이 달성되었습니다. 표 2: 다양한 모델 수에 따른 앙상블 학습 성능.
통합 모델 수가 증가하면 통합 성능이 먼저 증가하다가 감소합니다
. 저자는 모델 성능에 따라 높은 순서대로 앙상블에 모델을 추가한 후 성능 변화를 관찰합니다. 표 2에서 보는 바와 같이, 성능이 낮은 모델이 계속해서 도입되면서 적분 성능이 먼저 증가하다가 감소한다. ㅋㅋㅋ 표 3: 대규모 간의 앙상블 학습 다국어 기계 번역 데이터 세트 Flores의 모델 및 번역 전문가 모델.
(4) 대형 모델과 전문가 모델을 통합하여 특정 작업의 성능을 효과적으로 개선합니다
. 저자는 또한 기계 번역 작업에 대형 모델 LLaMA2-13B와 다국어 번역 모델 NLLB를 통합했습니다. Table 3에서 보는 바와 같이 일반 대형 모델과 업무별 전문가 모델의 통합을 통해 성능을 크게 향상시킬 수 있다.
결론
대형 모델의 흐름은 끝없이 많지만 모든 작업에서 한 모델이 다른 모델을 종합적으로 압도하기는 어렵습니다. 따라서 서로 다른 모델 간의 상호 보완적인 장점을 어떻게 활용하는가가 중요한 연구 방향이 되었습니다. 이 기사에 소개된 DeePEn 프레임워크는 매개변수 훈련 없이 분포 융합에서 서로 다른 대형 모델 간의 어휘 차이 문제를 해결합니다. 수많은 실험을 통해 DeePEn이 다양한 작업, 다양한 모델 번호, 다양한 모델 아키텍처를 사용하는 앙상블 학습 설정에서 안정적인 성능 향상을 달성했음을 보여줍니다. 위 내용은 LLama+Mistral+…+Yi=? 훈련이 필요 없는 이기종 대형 모델 통합 학습 프레임워크 DeePEn이 출시되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!







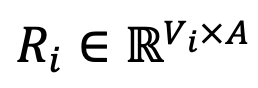
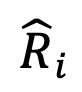
 으로 변환합니다.
으로 변환합니다. 


 여기서
여기서  는 모델의 협업 가중치
는 모델의 협업 가중치
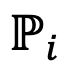 는 모델의 절대 공간
는 모델의 절대 공간 거리 간의 상대적 손실 함수(KL 발산)를 측정한 것입니다.
거리 간의 상대적 손실 함수(KL 발산)를 측정한 것입니다.  과 관련하여 손실 함수의 기울기
과 관련하여 손실 함수의 기울기 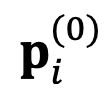 을 마스터 모델의 원래 절대 표현으로 초기화하고 업데이트합니다.
을 마스터 모델의 원래 절대 표현으로 초기화하고 업데이트합니다. 
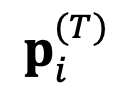 다음 단계에서 출력할 토큰을 결정합니다.
다음 단계에서 출력할 토큰을 결정합니다. 

 대형 모델과 전문가 모델을 통합하여 특정 작업의 성능을 효과적으로 개선합니다
대형 모델과 전문가 모델을 통합하여 특정 작업의 성능을 효과적으로 개선합니다
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



