

AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
이 기사의 주 저자는 홍콩 대학교 데이터 인텔리전스 연구소 출신입니다. 저자 중 제1저자 Ren Xubin과 제2저자 Tang Jiabin은 모두 홍콩대학교 데이터사이언스학과 박사과정 1학년생이며, 지도교수는 Data Intelligence Lab@HKU의 Huang Chao 교수입니다. 홍콩대학교 데이터 인텔리전스 연구소(Data Intelligence Laboratory)는 대규모 언어 모델, 그래프 신경망, 정보 검색, 추천 시스템, 시공간 데이터 마이닝 등의 분야를 다루는 인공 지능 및 데이터 마이닝 관련 연구에 전념하고 있습니다. 이전 작업에는 일반 그래프 대규모 언어 모델 GraphGPT, HiGPT, 스마트 시티 대규모 언어 모델 UrbanGPT, 해석 가능한 대규모 언어 모델 추천 알고리즘 XRec 등이 포함됩니다.
오늘날의 정보 폭발 시대, 광대한 데이터 바다에서 어떻게 깊은 연결을 탐색할 수 있을까요?
이와 관련하여 홍콩 대학교, 노트르담 대학교 및 기타 기관의 전문가와 학자들이 그래프 학습 및 대규모 언어 모델 분야에 대한 최신 리뷰에서 답을 공개했습니다.
그래프는 현실 세계의 다양한 관계를 묘사하는 기본 데이터 구조로서 그 중요성은 자명합니다. 이전 연구에서는 그래프 신경망이 그래프 관련 작업에서 인상적인 결과를 얻었음을 입증했습니다. 그러나 그래프 데이터 응용 시나리오의 복잡성이 계속 증가함에 따라 그래프 기계 학습의 병목 현상 문제가 점점 더 두드러지고 있습니다. 최근 자연어 처리 분야에서는 대규모 언어 모델이 주목을 받고 있으며, 뛰어난 언어 이해 및 요약 능력이 큰 주목을 받고 있습니다. 이러한 이유로 대규모 언어 모델과 그래프 학습 기술을 통합하여 그래프 학습 작업의 성능을 향상시키는 것이 업계의 새로운 연구 핫스팟이 되었습니다.
이 리뷰는 모델 일반화 능력, 견고성, 복잡한 그래프 데이터에 대한 이해 등 현재 그래프 학습 분야의 주요 기술적 과제에 대한 심층 분석을 제공하며, 향후 대규모 모델 기술의 혁신을 기대합니다. 이러한 "미지의 국경"이라는 측면에서 잠재력이 있습니다.

논문 주소: https://arxiv.org/abs/2405.08011
프로젝트 주소: https://github.com/HKUDS/Awesome-LLM4Graph-Papers
HKU Data Intelligence 연구실: https://sites.google.com/view/chaoh/home
이 리뷰는 그래프 학습에 적용된 최신 LLM에 대한 심층적인 검토를 제공하고 프레임워크 설계를 기반으로 한 새로운 분류 방법을 제안합니다. 기존 기술은 체계적으로 분류됩니다. 네 가지 알고리즘 설계 아이디어에 대한 자세한 분석을 제공합니다. 하나는 접두사 그래프 신경망, 두 번째는 접두어가 큰 언어 모델, 세 번째는 큰 언어 모델을 그래프와 통합하는 것, 네 번째는 큰 언어 모델만 사용하는 것입니다. 각 카테고리에 대해 핵심 기술 방법에 중점을 둡니다. 또한, 검토는 다양한 프레임워크의 장점과 한계에 대한 통찰력을 제공하고 향후 연구의 잠재적 방향을 식별합니다.
홍콩대학교 데이터 인텔리전스 연구소의 Huang Chao 교수가 이끄는 연구팀은 KDD 2024 컨퍼런스에서 그래프 학습 분야에서 대형 모델이 직면하는 "알 수 없는 경계"에 대해 심층적으로 논의할 예정입니다.
1 기본 지식
컴퓨터 과학 분야에서 그래프(Graph)는 중요한 비선형 데이터 구조로 노드 세트(V)와 에지 세트(E)로 구성됩니다. 각 모서리는 한 쌍의 노드를 연결하며 방향이 지정되거나(명확한 시작 및 끝 지점이 있음) 방향이 지정되지 않을 수 있습니다(방향이 지정되지 않음). 특히 그래프의 특수한 형태인 TAG(Text-Attributed Graph)가 문장과 같은 직렬화된 텍스트 기능을 각 노드에 할당한다는 점은 언급할 가치가 있습니다. 필수적인. 텍스트 속성 그래프는 정규적으로 노드 세트 V, 에지 세트 E, 텍스트 특징 세트 T로 구성된 삼중항으로 표현될 수 있습니다. 즉, G* = (V, E, T)입니다.
GNN(Graph Neural Networks)은 그래프 구조 데이터용으로 설계된 딥 러닝 프레임워크입니다. 이웃 노드의 정보를 집계하여 노드의 임베딩 표현을 업데이트합니다. 구체적으로, GNN의 각 계층은 특정 기능을 통해 노드 임베딩 h를 업데이트하며, 이는 현재 노드의 임베딩 상태와 주변 노드의 임베딩 정보를 종합적으로 고려하여 다음 계층의 노드 임베딩을 생성합니다.
Large Language Models (LLMs) is a powerful regression model. Recent research has shown that language models containing billions of parameters perform well in solving a variety of natural language tasks, such as translation, summary generation, and instruction execution, and are therefore called large language models. Currently, most cutting-edge LLMs are built based on Transformer blocks employing the query-key-value (QKV) mechanism, which efficiently integrates information in token sequences. According to the application direction and training method of attention, language models can be divided into two major types:
Masked Language Modeling (MLM) is a popular pre-training target for LLMs. It involves selectively masking specific tokens in a sequence and training the model to predict these masked tokens based on the surrounding context. In order to achieve accurate prediction, the model will comprehensively consider the contextual environment of the masked word elements.
Causal Language Modeling (CLM) is another mainstream pre-training objective for LLMs. It requires the model to predict the next token based on the previous tokens in the sequence. In this process, the model only relies on the context before the current word element to make accurate predictions.
2 Graph learning and large language models
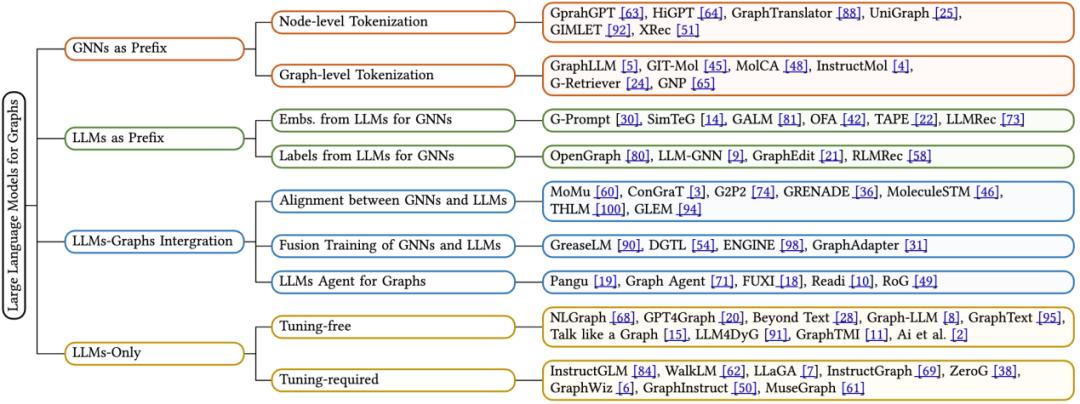
In this review article, the author relies on the model’s inference process - that is, the processing of graph data, text data, and large language models (LLMs) Interactive methods, a new classification method is proposed. Specifically, we summarize four main types of model architecture design, as follows:
GNNs as Prefix: In this category, graph neural networks (GNNs) serve as the primary component, responsible for processing graphs. data, and provide LLMs with structure-aware tags (such as node-level, edge-level, or graph-level tags) for subsequent inference.
LLMs as Prefix: In this category, LLMs first process graph data accompanied by textual information and subsequently provide node embeddings or generated labels for the training of graph neural networks.
LLMs-Graphs Integration (LLMs and Graphs Integration): Methods in this category strive to achieve deeper integration between LLMs and graph data, such as through fusion training or alignment with GNNs. In addition, an LLM-based agent was built to interact with graph information.
LLMs-Only (only using LLMs): This category designs practical hints and techniques to embed graph structured data into token sequences to facilitate inference by LLMs. At the same time, some methods also incorporate multi-modal markers to further enrich the model's processing capabilities.
2.1 GNNs as Prefix
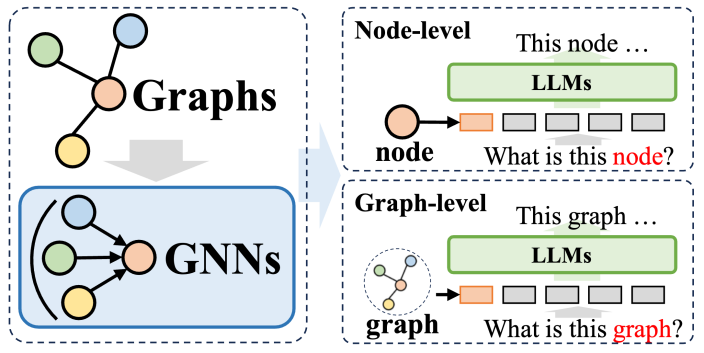
In the method system where graph neural networks (GNNs) are used as prefixes, GNNs play the role of structural encoders, significantly improving the performance of large language models (LLMs) on graph structures Data parsing capabilities, thereby benefiting a variety of downstream tasks. In these methods, GNNs mainly serve as encoders, responsible for converting complex graph data into graph token sequences containing rich structural information. These sequences are then input into LLMs, which is consistent with the natural language processing process.
These methods can be roughly divided into two categories: The first is node-level tokenization, that is, each node in the graph structure is individually input into LLM. The purpose of this approach is to enable LLM to deeply understand fine-grained node-level structural information and accurately identify the correlations and differences between different nodes. The second is graph-level tokenization, which uses specific pooling technology to compress the entire graph into a fixed-length token sequence, aiming to capture the overall high-level semantics of the graph structure.
For node-level tokenization, it is particularly suitable for graph learning tasks that require modeling node-level fine structure information, such as node classification and link prediction. In these tasks, the model needs to be able to distinguish subtle semantic differences between different nodes. Traditional graph neural networks generate a unique representation for each node based on the information of neighboring nodes, and then perform downstream classification or prediction based on this. The node-level tokenization method can retain the unique structural characteristics of each node to the greatest extent, which is of great benefit to the execution of downstream tasks.
On the other hand, graph-level tokenization is to adapt to graph-level tasks that require extracting global information from node data. Under the framework of GNN as a prefix, through various pooling operations, graph-level tokenization can synthesize many node representations into a unified graph representation, which not only captures the global semantics of the graph, but also further improves the performance of various downstream tasks. Execution effect.
2.2 LLMs as Prefix
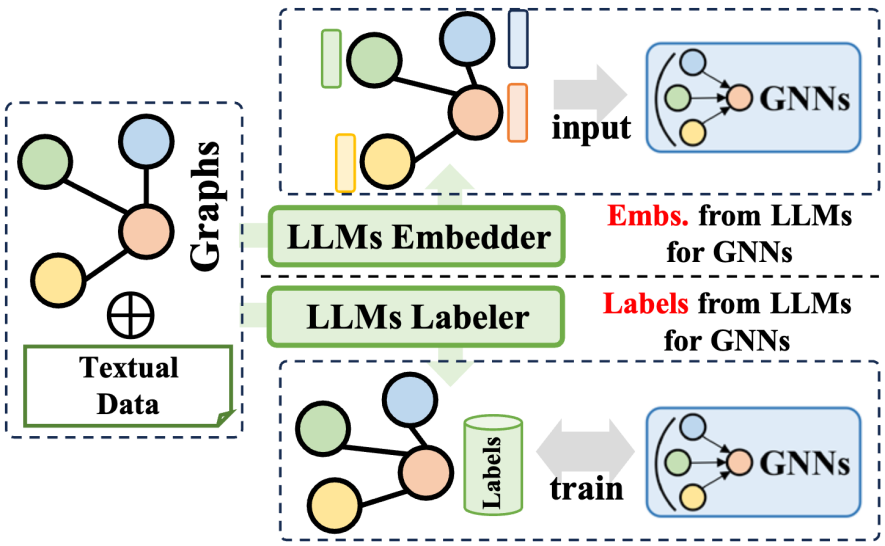
The Large Language Models (LLMs) prefix method utilizes the rich information generated by large language models to optimize the training process of graph neural networks (GNNs). This information covers various data such as text content, tags or embeddings generated by LLMs. According to how this information is applied, related technologies can be divided into two major categories: one is to use the embeddings generated by LLMs to assist the training of GNNs; the other is to integrate the labels generated by LLMs into the training process of GNNs.
In terms of utilizing LLMs embeddings, the inference process of GNNs involves the transfer and aggregation of node embeddings. However, the quality and diversity of initial node embeddings vary significantly across domains, such as ID-based embeddings in recommender systems or bag-of-words model embeddings in citation networks, and may lack clarity and richness. This lack of embedding quality sometimes limits the performance of GNNs. Furthermore, the lack of a universal node embedding design also affects the generalization ability of GNNs when dealing with different node sets. Fortunately, by leveraging the superior capabilities of large language models in language summarization and modeling, we can generate meaningful and effective embeddings for GNNs, thereby improving their training performance.
In terms of integrating LLMs labels, another strategy is to use these labels as supervision signals to enhance the training effect of GNNs. It is worth noting that the supervised labels here are not limited to traditional classification labels, but also include embeddings, graphs and other forms. The information generated by LLMs is not directly used as input data for GNNs, but constitutes a more refined optimization supervision signal, thereby helping GNNs achieve better performance on various graph-related tasks.
2.3 LLMs-Graphs Integration
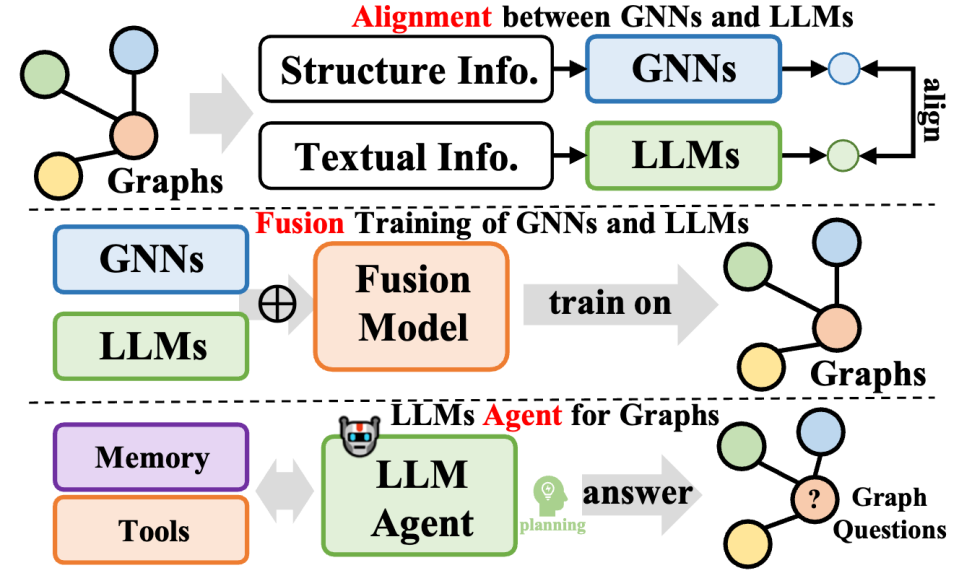
This type of method further integrates large language models and graph data, covers diverse methodologies, and not only improves the capabilities of large language models (LLMs) in graph processing tasks, At the same time, the parameter learning of graph neural networks (GNNs) is also optimized. These methods can be summarized into three types: one is the fusion of GNNs and LLMs, aiming to achieve deep integration and joint training between models; the other is the alignment between GNNs and LLMs, focusing on the representation or task level of the two models. The third is to build autonomous agents based on LLMs to plan and execute graph-related tasks.
In terms of the fusion of GNNs and LLMs, usually GNNs focus on processing structured data, while LLMs are good at processing text data, which results in the two having different feature spaces. To address this issue and promote the common gain of both data modalities on the learning of GNNs and LLMs, some methods adopt techniques such as contrastive learning or expectation maximization (EM) iterative training to align the feature spaces of the two models. This approach improves the accuracy of modeling graph and text information, thereby improving performance in a variety of tasks.
Regarding the alignment of GNNs with LLMs, although the representation alignment achieves joint optimization and embedding-level alignment of both models, they are still independent during the inference stage. To achieve tighter integration between LLMs and GNNs, some research focuses on designing deeper module architecture fusion, such as combining transformer layers in LLMs with graph neural layers in GNNs. By jointly training GNNs and LLMs, it is possible to bring bidirectional gains to both modules in graph tasks.
Finally, in terms of LLM-based graph agents, with the help of LLMs’ excellent capabilities in instruction understanding and self-planning to solve problems, the new research direction is to build autonomous agents based on LLMs to process or Research-related tasks. Typically, such an agent includes three modules: memory, perception, and action, forming a cycle of observation, memory recall, and action to solve specific tasks. In the field of graph theory, agents based on LLMs can directly interact with graph data and perform tasks such as node classification and link prediction.
2.4 LLMs-Only
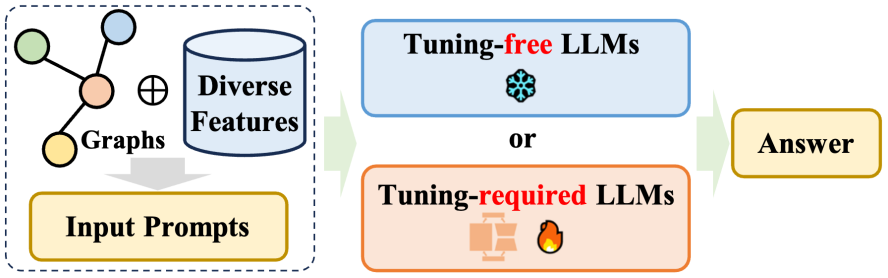
This review elaborates on the direct application of large language models (LLMs) to various graph-oriented tasks in the chapter on LLMs-Only, the so-called "only" LLMs” category. The goal of these methods is to enable LLMs to directly accept graph structure information, understand it, and combine this information to reason about various downstream tasks. These methods can be mainly divided into two categories: i) methods that do not require fine-tuning, aiming to design cues that LLMs can understand, and directly prompt pre-trained LLMs to perform graph-oriented tasks; ii) methods that require fine-tuning, focusing on The graph is converted into a sequence in a specific manner, and the graph token sequence and the natural language token sequence are aligned through fine-tuning methods.
Approche sans réglage fin : étant donné les caractéristiques structurelles uniques des données graphiques, deux défis clés se posent : premièrement, construire efficacement des graphiques au format langage naturel, deuxièmement, déterminer si les grands modèles de langage (LLM) peuvent comprendre avec précision le la forme du langage représentait la structure du graphe. Pour résoudre ces problèmes, un groupe de chercheurs a développé des méthodes sans réglage pour modéliser et raisonner sur des graphiques dans un espace de texte pur, explorant ainsi le potentiel des LLM pré-entraînés pour améliorer la compréhension structurelle.
Méthodes qui nécessitent un réglage précis : En raison des limites de l'utilisation de texte brut pour exprimer les informations sur la structure du graphe, la méthode courante récente consiste à utiliser le graphe comme une séquence de jetons de nœud et une séquence de jetons en langage naturel lors de la saisie du graphique dans grands modèles de langage (LLM). Différente de la méthode GNN susmentionnée en tant que méthode de préfixe, la seule méthode LLM qui doit être ajustée abandonne l'encodeur graphique et utilise à la place une description textuelle spécifique pour refléter la structure du graphique, ainsi que des invites soigneusement conçues dans les invites, qui sont liées à divers éléments en aval. Des performances prometteuses ont été obtenues au cours de la mission.
3 Orientations de recherche futures
Cette revue aborde également certaines questions ouvertes et de futures orientations de recherche potentielles pour les grands modèles de langage dans le domaine des graphes :
La fusion de graphes multimodaux et de grands modèles de langage (LLM). Des recherches récentes montrent que les grands modèles de langage ont démontré des capacités extraordinaires dans le traitement et la compréhension des données multimodales telles que les images et les vidéos. Cette avancée offre de nouvelles opportunités pour combiner les LLM avec des données cartographiques multimodales contenant plusieurs fonctionnalités modales. Le développement de LLM multimodaux capables de traiter de telles données graphiques nous permettra de mener des inférences plus précises et plus complètes sur les structures graphiques basées sur une prise en compte approfondie de plusieurs types de données tels que le texte, la vision et l'audition.
Améliorez l'efficacité et réduisez les coûts informatiques. Actuellement, les coûts de calcul élevés impliqués dans les phases de formation et d'inférence des LLM sont devenus un goulot d'étranglement majeur dans leur développement, limitant leur capacité à traiter des données graphiques à grande échelle contenant des millions de nœuds. Lorsqu’on essaie de combiner des LLM avec des réseaux de neurones graphiques (GNN), ce défi devient encore plus grave en raison de la fusion de deux modèles puissants. Par conséquent, il existe un besoin urgent de découvrir et de mettre en œuvre des stratégies efficaces pour réduire le coût de calcul de la formation des LLM et des GNN. Cela contribuera non seulement à atténuer les limitations actuelles, mais élargira également le champ d'application des LLM dans les tâches liées aux graphes. améliorant ainsi leur rôle dans la science des données, leur valeur pratique et leur influence sur le terrain.
Gérez diverses tâches graphiques. Les méthodes de recherche actuelles se concentrent principalement sur les tâches traditionnelles liées aux graphes, telles que la prédiction de liens et la classification des nœuds. Cependant, compte tenu des puissantes capacités des LLM, il est nécessaire d'explorer davantage leur potentiel dans le traitement de tâches plus complexes et génératives, telles que la génération de graphiques, la compréhension des graphiques et la réponse aux questions basées sur des graphiques. En étendant les méthodes basées sur le LLM pour couvrir ces tâches complexes, nous ouvrirons d'innombrables nouvelles opportunités pour l'application des LLM dans différents domaines. Par exemple, dans le domaine de la découverte de médicaments, les LLM peuvent faciliter la génération de nouvelles structures moléculaires ; dans le domaine de l’analyse des réseaux sociaux, ils peuvent fournir des informations approfondies sur des modèles de relations complexes ; dans le domaine de la construction de graphes de connaissances, les LLM peuvent aider à créer base de connaissances plus complète et contextuellement précise.
Créez des agents graphiques conviviaux. Actuellement, la plupart des agents basés sur LLM conçus pour les tâches liées aux graphiques sont personnalisés pour une seule tâche. Ces agents fonctionnent généralement en mode mono-coup et sont conçus pour résoudre les problèmes en une seule fois. Cependant, un agent idéal basé sur LLM doit être convivial et capable de rechercher dynamiquement des réponses dans les données graphiques en réponse à diverses questions ouvertes posées par les utilisateurs. Pour atteindre cet objectif, nous devons développer un agent à la fois flexible et robuste, capable d'interactions itératives avec les utilisateurs et apte à gérer la complexité des données graphiques pour fournir des réponses précises et pertinentes. Cela nécessitera que les agents soient non seulement très adaptables, mais également qu’ils fassent preuve d’une grande robustesse.
4 Résumé
Cette revue a mené une discussion approfondie sur les modèles de langage à grande échelle (LLM) personnalisés pour les données graphiques et a proposé une méthode de classification basée sur des cadres d'inférence basés sur des modèles, divisant soigneusement les différents modèles en quatre types. . Conception de cadre unique. Chaque conception présente ses propres forces et limites. De plus, cette revue fournit également une discussion complète de ces fonctionnalités, explorant en profondeur le potentiel et les défis de chaque framework lorsqu'il s'agit de tâches de traitement de données graphiques. Ce travail de recherche vise à fournir une ressource de référence aux chercheurs désireux d'explorer et d'appliquer des modèles de langage à grande échelle pour résoudre des problèmes liés aux graphes, et on espère qu'à terme, grâce à ce travail, il favorisera une compréhension plus approfondie de l'application de LLM et données graphiques, et produire en outre des innovations technologiques et des percées dans ce domaine.
위 내용은 KDD 2024│홍콩 대황 차오팀, 그래프 머신러닝 분야 대형 모델의 '알 수 없는 경계' 심층 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



