

TPAMI 2024 | ProCo: 무한 대조 쌍의 롱테일 대조 학습


AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
이 논문의 첫 번째 저자인 Du Chaoqun은 2020년 칭화대학교 자동화학과 박사 과정 학생입니다. 지도교수는 황가오(Huang Gao) 부교수이다. 그는 이전에 칭화대학교 물리학과에서 이학사 학위를 받았습니다. 그의 연구 관심분야는 롱테일 학습, 준지도 학습, 전이 학습 등과 같은 다양한 데이터 분포에 대한 모델 일반화 및 견고성 연구입니다. TPAMI, ICML 등 일류 국제 저널 및 컨퍼런스에 많은 논문을 게재했습니다.
개인 홈페이지: https://andy-du20.github.io
이 글은 칭화대학교의 롱테일 시각 인식에 관한 논문인 Probabilistic Contrastive Learning for Long-Tailed Visual Recognition을 소개합니다. TPAMI 2024가 승인되었으며 코드는 오픈 소스였습니다.
이 연구는 주로 롱테일 시각적 인식 작업에 대조 학습을 적용하는 데 중점을 두고 있으며, 대조 손실을 개선하여 무제한의 대조 쌍에 대한 대조 학습을 달성하는 새로운 롱테일 대조 학습 방법을 제안합니다. 문제를 효과적으로 해결하기 지도 대조 학습[1]은 배치(메모리 뱅크) 크기에 본질적으로 의존합니다. 롱테일 시각적 분류 작업 외에도 이 방법은 롱테일 준지도 학습, 롱테일 객체 감지 및 균형 잡힌 데이터 세트에서도 실험되어 상당한 성능 향상을 달성했습니다.

- 논문 링크: https://arxiv.org/pdf/2403.06726
- 프로젝트 링크: https://github.com/LeapLabTHU/ProCo
비교 자기 지도 학습의 학습 성공은 시각적 특징 표현 학습의 효율성을 보여줍니다. 대조 학습 성능에 영향을 미치는 핵심 요소는
대조 쌍의 수로, 이는 모델이 더 많은 부정적인 샘플로부터 학습할 수 있게 하며, 이는 가장 대표적인 두 가지 방법인 SimCLR [2] 및 MoCo [3]에 각각 반영됩니다. 메모리 뱅크 크기. 그러나 롱테일 시각적 인식 작업에서는 범주 불균형으로 인해 대조 쌍의 수를 늘려서 얻는 이득이 심각한 한계 감소 효과를 생성합니다. 이는 대부분의 대조 쌍이 머리 범주로 구성되어 있기 때문입니다. .샘플로 구성되어 있어 꼬리 카테고리를 다 커버하기 어렵습니다. 예를 들어 롱테일 Imagenet 데이터 세트에서 배치 크기(메모리 뱅크)가 공통 4096 및 8192로 설정되면 각 배치(메모리 뱅크)에는 평균 212
및89 범주가 있습니다. 은행) 표본 크기는 1보다 작습니다. 따라서 ProCo 방법의 핵심 아이디어는 롱테일 데이터 세트에서 각 데이터 유형의 분포를 모델링하고 매개변수를 추정하고 샘플링하여 대조 쌍을 구축하여 모든 범주가 덮여있다. 또한, 샘플 수가 무한대에 가까워지는 경우 대조 손실의 예상 분석 솔루션을 이론적으로 엄격하게 도출할 수 있으므로 대조 쌍의 비효율적인 샘플링을 피하고 무한한 대비 손실 수를 달성하기 위한 최적화 대상으로 직접 사용할 수 있습니다. 쌍 비교 학습.
그러나 위의 아이디어를 실현하는 데에는 몇 가지 주요 어려움이 있습니다. 각 데이터 유형의 분포를 모델링하는 방법.
- 특히 표본 수가 적은 꼬리 범주의 경우 분포 모수를 효율적으로 추정하는 방법입니다.
- 예상되는 대비 손실 분석 솔루션이 존재하고 계산될 수 있는지 확인하는 방법입니다.
- 실제로 위의 문제는 통합 확률 모델로 해결할 수 있습니다. 즉, 특성 분포를 모델링하기 위해 간단하고 효과적인 확률 분포를 선택하므로 최대 우도 추정을 사용하여 의 모수를 효율적으로 추정할 수 있습니다. 분포 및 계산 대조 손실에 대한 분석적 솔루션을 기대합니다.
대조 학습의 특징은 단위 초구체에 분포하므로 가능한 해결책은 구의 vMF(von Mises-Fisher) 분포를 특징 분포로 선택하는 것입니다(이 분포는 구의 정규 분포와 유사합니다). . vMF 분포 매개변수의 최대우도 추정은 대략적인 분석적 해법을 갖고 있으며 특징의 1차 모멘트 통계에만 의존하므로 분포의 매개변수를 효율적으로 추정할 수 있으며 대비 손실에 대한 기대치를 엄격하게 도출할 수 있습니다. 무제한의 대조 쌍 비교를 달성합니다.
Rajah 1 Algoritma ProCo menganggarkan pengedaran sampel berdasarkan ciri-ciri kumpulan yang berbeza Dengan mengambil sampel bilangan sampel yang tidak terhad, penyelesaian analitik bagi kerugian kontrastif yang dijangkakan boleh diperolehi, dengan berkesan menghapuskan pergantungan yang wujud pada pembelajaran kontrastif yang diselia. saiz kumpulan (bank memori) saiz .
Butiran kaedah
Berikut akan memperkenalkan kaedah ProCo secara terperinci dari empat aspek: andaian pengedaran, anggaran parameter, objektif pengoptimuman dan analisis teori.
Andaian Agihan
Seperti yang dinyatakan sebelum ini, ciri-ciri dalam pembelajaran kontras adalah terhad kepada hipersfera unit. Oleh itu, boleh diandaikan bahawa taburan yang dipatuhi oleh ciri-ciri ini ialah taburan von Mises-Fisher (vMF), dan fungsi ketumpatan kebarangkaliannya ialah: 
di mana z ialah vektor unit ciri p-dimensi, I ialah diubah suai. Fungsi Bessel jenis pertama,
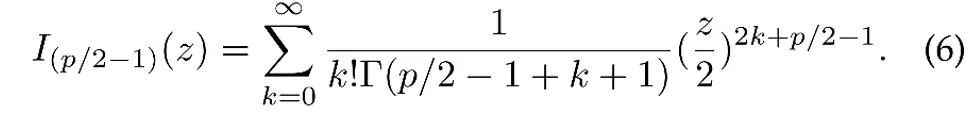
μ ialah arah min taburan, κ ialah parameter kepekatan, yang mengawal tahap kepekatan taburan Apabila κ lebih besar, tahap pengelompokan sampel berhampiran min adalah lebih tinggi; apabila κ =0, taburan vMF merosot menjadi sfera.
Anggaran parameter
Berdasarkan andaian pengedaran di atas, pengedaran keseluruhan ciri data ialah pengedaran vMF bercampur, di mana setiap kategori sepadan dengan pengedaran vMF.

di mana parameter  mewakili kebarangkalian terdahulu bagi setiap kategori, sepadan dengan kekerapan kategori y dalam set latihan. Purata vektor
mewakili kebarangkalian terdahulu bagi setiap kategori, sepadan dengan kekerapan kategori y dalam set latihan. Purata vektor  dan parameter terkumpul
dan parameter terkumpul  taburan ciri dianggarkan mengikut anggaran kemungkinan maksimum.
taburan ciri dianggarkan mengikut anggaran kemungkinan maksimum.
Dengan mengandaikan bahawa N vektor unit bebas dijadikan sampel daripada taburan vMF kategori y, anggaran kemungkinan maksimum (anggaran) [4] bagi arah min dan parameter kepekatan memenuhi persamaan berikut:
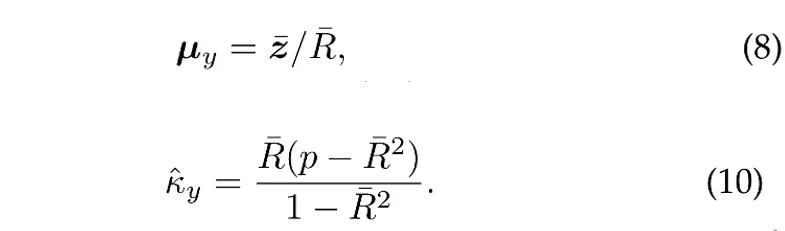
di mana  ialah sampel min,
ialah sampel min,  ialah panjang modulus bagi min sampel. Di samping itu, untuk menggunakan sampel sejarah, ProCo menggunakan kaedah anggaran dalam talian, yang boleh menganggarkan parameter kategori ekor dengan berkesan. . Oleh itu, kajian ini secara teorinya memanjangkan bilangan sampel kepada infiniti dan dengan tegas memperoleh penyelesaian analisis bagi fungsi kehilangan kontras yang dijangkakan secara langsung sebagai sasaran pengoptimuman.
ialah panjang modulus bagi min sampel. Di samping itu, untuk menggunakan sampel sejarah, ProCo menggunakan kaedah anggaran dalam talian, yang boleh menganggarkan parameter kategori ekor dengan berkesan. . Oleh itu, kajian ini secara teorinya memanjangkan bilangan sampel kepada infiniti dan dengan tegas memperoleh penyelesaian analisis bagi fungsi kehilangan kontras yang dijangkakan secara langsung sebagai sasaran pengoptimuman.
Dengan memperkenalkan cawangan ciri tambahan (pembelajaran perwakilan berdasarkan matlamat pengoptimuman ini) semasa proses latihan, cawangan ini boleh dilatih bersama-sama dengan cawangan klasifikasi dan tidak akan meningkat kerana hanya cawangan klasifikasi diperlukan semasa inferens Pengiraan tambahan kos. Jumlah wajaran kerugian kedua-dua cabang digunakan sebagai matlamat pengoptimuman akhir, dan α=1 ditetapkan dalam eksperimen Akhirnya, proses keseluruhan algoritma ProCo adalah seperti berikut: Analisis teori
Untuk meneruskan. menganalisis Untuk mengesahkan keberkesanan kaedah ProCo secara teori, para penyelidik menganalisis terikat ralat generalisasi dan terikat risiko yang berlebihan. Untuk memudahkan analisis, diandaikan di sini hanya terdapat dua kategori, iaitu y∈{-1+1}. Analisis menunjukkan bahawa terikat ralat generalisasi dikawal terutamanya oleh bilangan sampel latihan dan varians data Pengedaran. Dapatan ini konsisten dengan Analisis teori kerja berkaitan [6][7] adalah konsisten, memastikan bahawa kehilangan ProCo tidak memperkenalkan faktor tambahan dan tidak meningkatkan terikat ralat generalisasi, yang secara teorinya menjamin keberkesanan kaedah ini. 
Selain itu, kaedah ini bergantung pada andaian tertentu tentang pengagihan ciri dan anggaran parameter. Untuk menilai kesan parameter ini pada prestasi model, penyelidik juga menganalisis lebihan risiko kerugian ProCo, yang mengukur sisihan antara risiko yang dijangka menggunakan parameter anggaran dan risiko optimum Bayes, yang berada dalam pengedaran sebenar risiko Dijangka parameter.

Ini menunjukkan bahawa lebihan risiko kerugian ProCo dikawal terutamanya oleh terma urutan pertama ralat anggaran parameter.
Hasil eksperimen
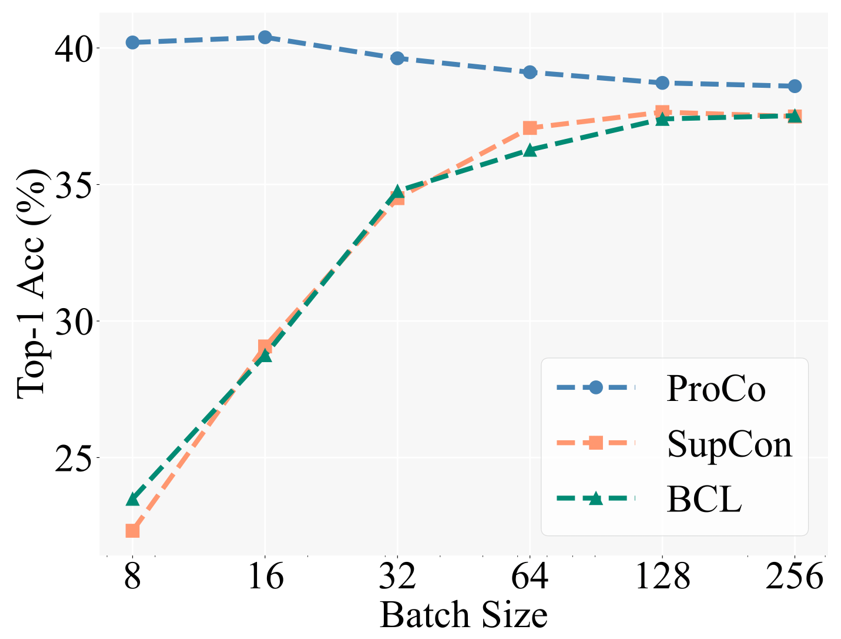
Sebagai pengesahan motivasi teras, penyelidik terlebih dahulu membandingkan prestasi kaedah pembelajaran kontrastif yang berbeza di bawah saiz kelompok yang berbeza. Baseline termasuk Pembelajaran Kontrastif Seimbang [5] (BCL), kaedah yang dipertingkatkan juga berdasarkan SCL pada tugas pengecaman ekor panjang. Tetapan percubaan khusus mengikut strategi latihan dua peringkat Pembelajaran Kontrastif Terselia (SCL), iaitu, pertama sekali hanya menggunakan kehilangan kontrastif untuk latihan pembelajaran perwakilan, dan kemudian melatih pengelas linear untuk ujian dengan tulang belakang beku.
Angka di bawah menunjukkan keputusan percubaan pada set data CIFAR100-LT (IF100) Prestasi BCL dan SupCon jelas terhad oleh saiz kelompok, tetapi ProCo secara berkesan menghapuskan kesan SupCon pada saiz kelompok dengan memperkenalkan ciri tersebut. pengedaran setiap kategori pergantungan, dengan itu mencapai prestasi terbaik di bawah saiz kelompok yang berbeza.
Selain itu, para penyelidik juga menjalankan eksperimen tentang tugas pengecaman ekor panjang, pembelajaran separa penyeliaan ekor panjang, pengesanan objek ekor panjang dan set data seimbang. Di sini kami terutamanya menunjukkan hasil percubaan pada set data ekor panjang berskala besar Imagenet-LT dan iNaturalist2018. Pertama, di bawah jadual latihan selama 90 zaman, berbanding kaedah serupa untuk meningkatkan pembelajaran kontrastif, ProCo mempunyai sekurang-kurangnya 1% peningkatan prestasi pada dua set data dan dua tulang belakang.

Keputusan berikut seterusnya menunjukkan bahawa ProCo juga boleh mendapat manfaat daripada jadual latihan yang lebih panjang Di bawah jadual 400 zaman, ProCo mencapai prestasi SOTA pada set data iNaturalist2018, dan juga mengesahkan bahawa ia boleh bersaing dengan kombinasi bukan A yang lain. kaedah pembelajaran kontrastif, termasuk penyulingan (NCL) dan kaedah lain. "Rangka kerja ringkas untuk pembelajaran kontras perwakilan visual." mengenai penglihatan komputer dan pengecaman corak 2020.

-
J. Zhu, et al. "Pembelajaran kontrastif seimbang untuk pengecaman visual ekor panjang," dalam CVPR, 2022. - W. Jitkrittum, et al. "ELM: Membenamkan dan margin logit untuk pembelajaran ekor panjang," pracetak arXiv, 2022.
- A K. Menon, et al.
위 내용은 TPAMI 2024 | ProCo: 무한 대조 쌍의 롱테일 대조 학습의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 ControlNet의 저자가 또 다른 히트를 쳤습니다! 이틀 만에 14,000개의 별을 획득하여 그림에서 그림을 생성하는 전체 과정
Jul 17, 2024 am 01:56 AM
ControlNet의 저자가 또 다른 히트를 쳤습니다! 이틀 만에 14,000개의 별을 획득하여 그림에서 그림을 생성하는 전체 과정
Jul 17, 2024 am 01:56 AM
역시 Tusheng 영상이지만 PaintsUndo는 다른 경로를 택했습니다. ControlNet 작성자 LvminZhang이 다시 살기 시작했습니다! 이번에는 회화 분야를 목표로 삼고 있습니다. 새로운 프로젝트인 PaintsUndo는 출시된 지 얼마 되지 않아 1.4kstar(여전히 상승세)를 받았습니다. 프로젝트 주소: https://github.com/lllyasviel/Paints-UNDO 이 프로젝트를 통해 사용자는 정적 이미지를 입력하고 PaintsUndo는 자동으로 라인 초안부터 완성품 따라가기까지 전체 페인팅 과정의 비디오를 생성하도록 도와줍니다. . 그리는 과정에서 선의 변화가 놀랍습니다. 최종 영상 결과는 원본 이미지와 매우 유사합니다. 완성된 그림을 살펴보겠습니다.
 오픈 소스 AI 소프트웨어 엔지니어 목록의 1위인 UIUC의 에이전트 없는 솔루션은 SWE 벤치의 실제 프로그래밍 문제를 쉽게 해결합니다.
Jul 17, 2024 pm 10:02 PM
오픈 소스 AI 소프트웨어 엔지니어 목록의 1위인 UIUC의 에이전트 없는 솔루션은 SWE 벤치의 실제 프로그래밍 문제를 쉽게 해결합니다.
Jul 17, 2024 pm 10:02 PM
AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com 이 논문의 저자는 모두 일리노이 대학교 Urbana-Champaign(UIUC)의 Zhang Lingming 교사 팀 출신입니다. Steven Code Repair, 박사 4년차, 연구원
 RLHF에서 DPO, TDPO까지 대규모 모델 정렬 알고리즘은 이미 '토큰 수준'입니다.
Jun 24, 2024 pm 03:04 PM
RLHF에서 DPO, TDPO까지 대규모 모델 정렬 알고리즘은 이미 '토큰 수준'입니다.
Jun 24, 2024 pm 03:04 PM
AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com 인공 지능 개발 과정에서 LLM(대형 언어 모델)의 제어 및 안내는 항상 핵심 과제 중 하나였으며 이러한 모델이 두 가지 모두를 보장하는 것을 목표로 했습니다. 강력하고 안전하게 인간 사회에 봉사합니다. 인간 피드백(RL)을 통한 강화 학습 방법에 초점을 맞춘 초기 노력
 arXiv 논문은 '연발'로 게시될 수 있습니다. Stanford alphaXiv 토론 플랫폼은 온라인이며 LeCun은 이를 좋아합니다.
Aug 01, 2024 pm 05:18 PM
arXiv 논문은 '연발'로 게시될 수 있습니다. Stanford alphaXiv 토론 플랫폼은 온라인이며 LeCun은 이를 좋아합니다.
Aug 01, 2024 pm 05:18 PM
건배! 종이 토론이 말로만 진행된다면 어떤가요? 최근 스탠포드 대학교 학생들은 arXiv 논문에 대한 질문과 의견을 직접 게시할 수 있는 arXiv 논문에 대한 공개 토론 포럼인 alphaXiv를 만들었습니다. 웹사이트 링크: https://alphaxiv.org/ 실제로 이 웹사이트를 특별히 방문할 필요는 없습니다. URL에서 arXiv를 alphaXiv로 변경하면 alphaXiv 포럼에서 해당 논문을 바로 열 수 있습니다. 논문, 문장: 오른쪽 토론 영역에서 사용자는 저자에게 논문의 아이디어와 세부 사항에 대해 질문하는 질문을 게시할 수 있습니다. 예를 들어 다음과 같이 논문 내용에 대해 의견을 제시할 수도 있습니다.
 OpenAI Super Alignment Team의 사후 작업: 두 개의 대형 모델이 게임을 하고 출력이 더 이해하기 쉬워졌습니다.
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment Team의 사후 작업: 두 개의 대형 모델이 게임을 하고 출력이 더 이해하기 쉬워졌습니다.
Jul 19, 2024 am 01:29 AM
AI 모델이 내놓은 답변이 전혀 이해하기 어렵다면 감히 사용해 보시겠습니까? 기계 학습 시스템이 더 중요한 영역에서 사용됨에 따라 우리가 그 결과를 신뢰할 수 있는 이유와 신뢰할 수 없는 경우를 보여주는 것이 점점 더 중요해지고 있습니다. 복잡한 시스템의 출력에 대한 신뢰를 얻는 한 가지 가능한 방법은 시스템이 인간이나 다른 신뢰할 수 있는 시스템이 읽을 수 있는 출력 해석을 생성하도록 요구하는 것입니다. 즉, 가능한 오류가 발생할 수 있는 지점까지 완전히 이해할 수 있습니다. 설립하다. 예를 들어, 사법 시스템에 대한 신뢰를 구축하기 위해 우리는 법원이 자신의 결정을 설명하고 뒷받침하는 명확하고 읽기 쉬운 서면 의견을 제공하도록 요구합니다. 대규모 언어 모델의 경우 유사한 접근 방식을 채택할 수도 있습니다. 그러나 이 접근 방식을 사용할 때는 언어 모델이 다음을 생성하는지 확인하세요.
 리만 가설의 중요한 돌파구! 타오저쉬안(Tao Zhexuan)은 MIT와 옥스퍼드의 새로운 논문을 적극 추천했으며, 37세의 필즈상 수상자도 참여했다.
Aug 05, 2024 pm 03:32 PM
리만 가설의 중요한 돌파구! 타오저쉬안(Tao Zhexuan)은 MIT와 옥스퍼드의 새로운 논문을 적극 추천했으며, 37세의 필즈상 수상자도 참여했다.
Aug 05, 2024 pm 03:32 PM
최근 새천년 7대 과제 중 하나로 알려진 리만 가설이 새로운 돌파구를 마련했다. 리만 가설은 소수 분포의 정확한 특성과 관련된 수학에서 매우 중요한 미해결 문제입니다(소수는 1과 자기 자신으로만 나눌 수 있는 숫자이며 정수 이론에서 근본적인 역할을 합니다). 오늘날의 수학 문헌에는 리만 가설(또는 일반화된 형식)의 확립에 기초한 수학적 명제가 천 개가 넘습니다. 즉, 리만 가설과 그 일반화된 형식이 입증되면 천 개가 넘는 명제가 정리로 확립되어 수학 분야에 지대한 영향을 미칠 것이며, 리만 가설이 틀린 것으로 입증된다면, 이러한 제안의 일부도 그 효과를 잃을 것입니다. MIT 수학 교수 Larry Guth와 Oxford University의 새로운 돌파구
 LLM은 시계열 예측에 적합하지 않습니다. 추론 능력도 사용하지 않습니다.
Jul 15, 2024 pm 03:59 PM
LLM은 시계열 예측에 적합하지 않습니다. 추론 능력도 사용하지 않습니다.
Jul 15, 2024 pm 03:59 PM
시계열 예측에 언어 모델을 실제로 사용할 수 있나요? Betteridge의 헤드라인 법칙(물음표로 끝나는 모든 뉴스 헤드라인은 "아니오"로 대답할 수 있음)에 따르면 대답은 아니오여야 합니다. 사실은 사실인 것 같습니다. 이렇게 강력한 LLM은 시계열 데이터를 잘 처리할 수 없습니다. 시계열, 즉 시계열은 이름에서 알 수 있듯이 시간 순서대로 배열된 데이터 포인트 시퀀스 집합을 나타냅니다. 시계열 분석은 질병 확산 예측, 소매 분석, 의료, 금융 등 다양한 분야에서 중요합니다. 시계열 분석 분야에서는 최근 많은 연구자들이 LLM(Large Language Model)을 사용하여 시계열의 이상 현상을 분류, 예측 및 탐지하는 방법을 연구하고 있습니다. 이 논문에서는 텍스트의 순차적 종속성을 잘 처리하는 언어 모델이 시계열로도 일반화될 수 있다고 가정합니다.
 최초의 Mamba 기반 MLLM이 출시되었습니다! 모델 가중치, 학습 코드 등은 모두 오픈 소스입니다.
Jul 17, 2024 am 02:46 AM
최초의 Mamba 기반 MLLM이 출시되었습니다! 모델 가중치, 학습 코드 등은 모두 오픈 소스입니다.
Jul 17, 2024 am 02:46 AM
AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com 서문 최근 몇 년 동안 다양한 분야에서 MLLM(Multimodal Large Language Model)의 적용이 눈에 띄는 성공을 거두었습니다. 그러나 많은 다운스트림 작업의 기본 모델로서 현재 MLLM은 잘 알려진 Transformer 네트워크로 구성됩니다.
