

AI 도구에는 훈련 데이터가 부족하지만 6가지 솔루션이 있습니다.

인공지능에는 훈련 데이터가 필요하지만 그 데이터는 제한적입니다. 그렇다면 AI가 지속적으로 성장하고 우리에게 유용하도록 AI를 어떻게 훈련시킬 수 있을까요?
인터넷과 데이터가 무한한 자원이라고 생각할 수도 있지만, AI 도구로는 채굴할 수 있는 데이터가 부족합니다. 이제 걱정하시기 전에 AI 개발이 중단되지는 않을 것입니다. AI 시스템을 교육할 준비가 된 많은 데이터가 아직 남아 있습니다.
1 온라인에는 항상 더 많은 데이터가 추가됩니다
간단히 말해서, AI 연구소인 Epoch에서는 AI가 훈련되는 고품질 데이터가 2026년이 되면 고갈될 수 있다고 말합니다.
여기서 핵심 단어는 '할 수 있다'입니다. 매년 인터넷에 추가되는 데이터의 양이 증가하므로 2026년 이전에는 뭔가 급격한 변화가 있을 수 있습니다. 그럼에도 불구하고 이는 공정한 추정입니다. 어느 쪽이든 AI 시스템은 어느 시점에서 좋은 데이터가 고갈될 것입니다.
그러나 우리는 매년 약 147제타바이트의 데이터가 (폭발적인 주제에 따라) 온라인으로 추가된다는 점을 기억해야 합니다. 1제타바이트는 1,000,000,000,000,000,000,000비트의 데이터와 같습니다. 실제적으로(글쎄, 어느 정도 현실적으로) 이는 300억 개가 넘는 4K 영화(실제이지만 헤아릴 수 없음)에 해당합니다. AI가 선별할 수 있는 정보의 양은 놀라울 정도로 많습니다.
그럼에도 불구하고 AI는 인류가 생성하는 것보다 더 빠르게 데이터를 소비합니다…
2 AI는 품질이 낮은 데이터도 잊어버릴 수 있습니다

147제타바이트의 데이터가 물론 좋은 데이터는 아닙니다. 눈에 보이는 것보다 더 많은 것이 있습니다. 하지만 2050년에는 AI가 저품질 언어 데이터도 소모할 것으로 추정됩니다.
Reuters는 한때 세계 최대의 사진 저장소 중 하나였던 Photobucket이 광범위한 라이브러리를 AI 교육 회사에 라이센스하기 위해 협상 중이라고 보도했습니다. 이미지 데이터에는 DALL-E 및 Midjourney와 같은 훈련된 시스템이 있지만 이 시스템도 2060년에는 고갈될 수 있습니다. 여기에도 더 큰 문제가 있습니다. Photobucket에는 Myspace와 같은 2000년대 소셜 미디어 플랫폼의 이미지가 저장되어 있어 표준이 높지 않습니다. 현재 사진. 이로 인해 품질이 낮은 데이터가 발생합니다.
포토버킷은 혼자가 아닙니다. 2024년 2월 Google은 Reddit과 계약을 체결하여 검색 대기업이 AI 교육에 소셜 미디어 플랫폼의 사용자 데이터를 사용할 수 있도록 허용했습니다. 다른 소셜 미디어 플랫폼도 AI 훈련 목적으로 사용자 데이터를 제공하고 있습니다. 일부는 Meta의 Llama와 같은 사내 AI 모델을 교육하는 데 이를 사용하고 있습니다.
그러나 일부 정보는 품질이 낮은 데이터에서 수집될 수 있지만 Microsoft는 AI가 데이터를 선택적으로 "학습 해제"하는 방법을 개발하고 있는 것으로 알려졌습니다. 주로 이는 IP 문제에 사용되지만 도구가 품질이 낮은 데이터 세트에서 배운 내용을 잊어버릴 수도 있음을 의미할 수도 있습니다.
지나치게 선택하지 않고도 AI에 더 많은 데이터를 제공할 수 있습니다. 그런 다음 해당 AI 시스템은 학습에 가장 유익한 것을 선택하고 선택할 수 있습니다.
3 음성 인식을 통한 비디오 및 팟캐스트 데이터
AI 도구에 공급되는 데이터는 지금까지 주로 텍스트로 구성되어 있으며, 그 정도는 적지만 이미지로 구성되어 있습니다. 음성 인식 소프트웨어는 사용 가능한 풍부한 비디오와 팟캐스트가 AI를 훈련할 수도 있다는 것을 의미하므로 이는 의심할 여지 없이 바뀔 것이며 이미 그랬을 가능성이 높습니다.
특히 OpenAI는 680,000시간의 다중 언어 및 멀티 태스킹 데이터를 사용하여 오픈 소스 자동 음성 인식(ASR) 신경망인 Whisper를 개발했습니다. 그런 다음 OpenAI는 YouTube 동영상의 백만 시간이 넘는 정보를 대규모 언어 모델인 GPT-4에 공급했습니다.
이는 음성 인식을 사용하여 다양한 소스의 비디오 및 오디오를 기록하고 AI 모델을 통해 해당 데이터를 실행하는 다른 AI 시스템에 이상적인 템플릿입니다.
Statista에 따르면 매분 500시간이 넘는 동영상이 YouTube에 업로드되며, 이는 2019년 이후 상당히 일정하게 유지되고 있습니다. Dailymotion 및 Podbean과 같은 다른 동영상 및 오디오 플랫폼은 말할 것도 없고요. AI가 이와 같은 새로운 데이터 세트에 관심을 돌릴 수 있다면 아직 채굴해야 할 정보가 엄청나게 많습니다.
4 AI는 대부분 영어에 묶여 있습니다.
이것이 우리가 Whisper에서 배울 수 있는 전부는 아닙니다. OpenAI는 117,000시간의 영어가 아닌 오디오 데이터를 사용하여 모델을 훈련했습니다. 이는 많은 AI 시스템이 주로 영어를 사용하거나 서구의 관점을 통해 다른 문화를 보면서 훈련되었기 때문에 특히 흥미롭습니다.
본질적으로 대부분의 도구는 제작자의 문화에 의해 제한됩니다.
ChatGPT를 예로 들어 보겠습니다. 2022년 출시 직후 노르웨이 베르겐 대학의 디지털 문화 교수인 Jill Walker Rettberg는 ChatGPT를 사용해 보고 다음과 같은 결론을 내렸습니다.
“ChatGPT는 노르웨이 문화에 대해 잘 모릅니다. 또는 오히려 노르웨이 문화에 대해 알고 있는 모든 것은 아마도 대부분 영어 소스에서 배운 것입니다. ChatGPT는 미국의 가치와 법률에 명시적으로 부합합니다. 대부분의 경우 이는 노르웨이와 유럽의 가치에 가깝지만 아마도 항상 그런 것은 아닐 것입니다.”
AI는 더 많은 다국적 사람들이 AI와 상호작용하거나 그러한 시스템을 훈련하는 데 더 다양한 언어와 문화를 사용할수록 발전할 수 있습니다. 현재 많은 인공지능이 단일 라이브러리에 국한되어 있습니다. 전 세계 도서관의 열쇠가 주어지면 성장할 수 있습니다.
5개의 출판사가 AI 개발을 도울 수 있습니다

IP는 분명히 엄청난 문제이지만 일부 출판사는 라이센스 계약을 체결하여 AI 개발을 도울 수 있습니다. 이는 도구에 온라인 소스에서 수집한 잠재적으로 품질이 낮은 정보보다는 책에서 가져온 고품질, 즉 신뢰할 수 있는 데이터를 제공하는 것을 의미합니다.
실제로 페이스북, 인스타그램, 왓츠앱 등의 소유주인 메타가 '빅 5' 출판사 중 하나인 사이먼 앤 슈스터 인수를 고려한 것으로 알려졌다. 아이디어는 회사가 출판한 문헌을 사용하여 Meta의 자체 AI를 훈련시키는 것이었습니다. 작가의 사전 동의 없이 IP를 처리하는 회사의 윤리적 회색 영역으로 인해 거래가 결국 실패했습니다.
고려된 또 다른 옵션은 새 타이틀에 대한 개별 라이센스 권한을 구매하는 것이었습니다. 이는 창작자들에게 큰 우려를 불러일으키겠지만, 사용 가능한 데이터가 고갈되면 AI 도구를 개발할 수 있는 흥미로운 방법이 될 것입니다.
6 합성 데이터가 미래입니다
다른 모든 솔루션은 여전히 제한적이지만 AI가 먼 미래까지 번성할 수 있는 옵션 중 하나는 바로 합성 데이터입니다. 그리고 그것은 이미 매우 현실적인 가능성으로 조사되고 있습니다.
그럼 합성데이터란 무엇일까요? 이런 의미에서 AI가 생성한 데이터입니다. 인간이 데이터를 생성하는 것처럼 이 방법을 사용하면 인공 지능이 훈련 목적으로 데이터를 생성하는 것을 볼 수 있습니다.
실제로 AI는 설득력 있는 딥페이크 동영상을 만들 수 있습니다. 해당 딥페이크 비디오는 AI에 다시 공급되어 본질적으로 상상의 시나리오로부터 학습할 수 있습니다. 이는 결국 인간이 배우는 주요 방법 중 하나입니다. 우리는 주변 세계를 이해하기 위해 무언가를 읽거나 시청합니다.
AI는 이미 합성 정보를 소비했을 가능성이 높습니다. 온라인에 유포된 딥페이크는 잘못된 정보와 허위 정보를 퍼뜨립니다. 따라서 AI 시스템이 인터넷을 검색하면 일부가 가짜 콘텐츠의 대상이 될 것이라는 것은 당연합니다.
네, 여기에는 교활한 측면이 있습니다. 또한 AI를 손상시키거나 제한하여 해당 도구로 인해 발생한 실수를 강화하고 퍼뜨릴 수도 있습니다. 기업들은 후자의 문제를 근절하기 위해 노력하고 있습니다. 그럼에도 불구하고 "AI가 서로 학습하고 오류를 범하는 것"은 많은 공상 과학 악몽 시나리오의 줄거리입니다.
7
AI는 논란의 여지가 있습니다. 많은 단점이 있지만 비방하는 사람들은 그 이점을 무시합니다. 예를 들어, 감사 및 자문 네트워크인 PwC[PDF]는 AI가 2030년까지 세계 경제에 최대 15조 7천억 달러에 기여할 수 있다고 제안합니다.
게다가 AI는 이미 전 세계에서 사용되고 있습니다. 당신은 아마도 그것을 깨닫지도 못한 채 오늘 어떤 형태로든 그것을 사용했을 것입니다. 이제 지니는 병에서 나왔습니다. 핵심은 신뢰할 수 있는 고품질 데이터로 지니를 훈련시켜 올바르게 활용할 수 있도록 하는 것입니다.
AI에는 긍정적인 면과 부정적인 면이 있습니다. 균형을 찾아야 합니다.
위 내용은 AI 도구에는 훈련 데이터가 부족하지만 6가지 솔루션이 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.
인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7315
7315
 9
1625
14
1349
46
1261
25
1208
29
9
1625
14
1349
46
1261
25
1208
29

 MCP (Model Context Protocol) 란 무엇입니까?
Mar 03, 2025 pm 07:09 PM
MCP (Model Context Protocol) 란 무엇입니까?
Mar 03, 2025 pm 07:09 PM
MCP (Model Context Protocol) : AI 및 데이터를위한 범용 커넥터 우리는 모두 매일 코딩에서 AI의 역할에 익숙합니다. Replit, Github Copilot, Black Box AI 및 Cursor IDE는 AI가 워크 플로우를 간소화하는 방법에 대한 몇 가지 예일뿐입니다. 하지만 상상해보십시오
 Omniparser V2 및 Omnitool을 사용하여 지역 비전 에이전트 구축
Mar 03, 2025 pm 07:08 PM
Omniparser V2 및 Omnitool을 사용하여 지역 비전 에이전트 구축
Mar 03, 2025 pm 07:08 PM
Microsoft의 Omniparser V2 및 Omnitool : AI를 사용한 GUI 자동화 혁명 조미료 전문가처럼 Windows 11 인터페이스와 상호 작용하는 AI를 상상해보십시오. Microsoft의 Omniparser v2와 Omnitool은 이것을 다시 만듭니다
 REPLIT 에이전트 : 실제 예제가있는 가이드
Mar 04, 2025 am 10:52 AM
REPLIT 에이전트 : 실제 예제가있는 가이드
Mar 04, 2025 am 10:52 AM
앱 개발 혁신 : REPLIT 에이전트에 대한 깊은 다이빙 복잡한 개발 환경으로 씨름하고 구성 파일을 모호하게하는 데 지쳤습니까? REPLIT 에이전트는 아이디어를 기능적 앱으로 변환하는 프로세스를 단순화하는 것을 목표로합니다. 이 ai-p
 나는 Cursor AI와 함께 Vibe 코딩을 시도했는데 놀랍습니다!
Mar 20, 2025 pm 03:34 PM
나는 Cursor AI와 함께 Vibe 코딩을 시도했는데 놀랍습니다!
Mar 20, 2025 pm 03:34 PM
Vibe Coding은 끝없는 코드 라인 대신 자연 언어를 사용하여 애플리케이션을 생성함으로써 소프트웨어 개발의 세계를 재구성하고 있습니다. Andrej Karpathy와 같은 비전가들로부터 영감을 얻은이 혁신적인 접근 방식은 Dev가
 활주로 ACT-One Guide : 나는 그것을 테스트하기 위해 스스로 촬영했다
Mar 03, 2025 am 09:42 AM
활주로 ACT-One Guide : 나는 그것을 테스트하기 위해 스스로 촬영했다
Mar 03, 2025 am 09:42 AM
이 블로그 게시물은 Web Interface와 Python API를 모두 다루는 Runway ML의 새로운 Act-One Animation Tool을 테스트하는 경험을 공유합니다. 유망하지만 내 결과는 예상보다 덜 인상적이었습니다. 생성 AI를 탐색하고 싶습니까? p에서 llms를 사용하는 법을 배우십시오
 물체 감지에 Yolo V12를 사용하는 방법은 무엇입니까?
Mar 22, 2025 am 11:07 AM
물체 감지에 Yolo V12를 사용하는 방법은 무엇입니까?
Mar 22, 2025 am 11:07 AM
Yolo (한 번만 보이면)는 주요 실시간 객체 감지 프레임 워크였으며 각 반복은 이전 버전에서 개선되었습니다. 최신 버전 Yolo V12는 정확도를 크게 향상시키는 발전을 소개합니다.
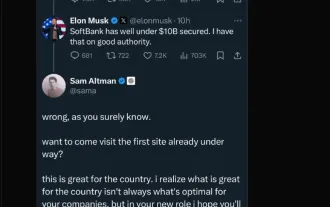 Elon Musk & Sam Altman은 5 천억 달러 이상의 Stargate 프로젝트를 충돌시킵니다.
Mar 08, 2025 am 11:15 AM
Elon Musk & Sam Altman은 5 천억 달러 이상의 Stargate 프로젝트를 충돌시킵니다.
Mar 08, 2025 am 11:15 AM
OpenAi, SoftBank, Oracle 및 Nvidia와 같은 기술 거인이 지원하고 미국 정부의 지원을받는 5 천억 달러 규모의 Stargate AI 프로젝트는 미국 AI 리더십을 굳히는 것을 목표로합니다. 이 야심 찬 사업은 AI Advanceme의 미래를 약속합니다.
 2025 년 2 월 2 일 Genai 출시 : GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
2025 년 2 월 2 일 Genai 출시 : GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
2025 년 2 월은 Generative AI의 또 다른 게임 변화 달이었으며, 가장 기대되는 모델 업그레이드와 획기적인 새로운 기능을 제공합니다. Xai 's Grok 3 및 Anthropic's Claude 3.7 Sonnet, Openai 's G에 이르기까지
