
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und sehen viele weitere hervorragende Leistungen. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch deutliche Lücken auf.
Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie z. B. DeepSeek-Coder-V2 für Programmierung und Mathematik, InternVL 1.5 für visuell-sprachliche Aufgaben (das in einigen Bereichen vergleichbar mit GPT ist). 4-Turbo-2024-04-09).
Als „Schaufelkönig der KI-Goldrausch-Ära“ leistet NVIDIA selbst auch Beiträge zum Bereich der offenen Modelle, wie zum Beispiel der von ihm entwickelten Modellreihe ChatQA. Bitte beachten Sie den Bericht auf dieser Seite “ NVIDIAs neues Dialog-QA-Modell ist genauer als GPT-4, aber ich wurde kritisiert: Ungewichteter Code hat wenig Bedeutung.》. Anfang dieses Jahres wurde ChatQA 1.5 veröffentlicht, das die RAG-Technologie (Retrieval-Augmented Generation) integriert und GPT-4 bei der Beantwortung von Konversationsfragen übertrifft.
Jetzt wurde ChatQA auf Version 2.0 weiterentwickelt. Die Hauptrichtung der Verbesserung besteht dieses Mal darin, das Kontextfenster zu erweitern.

Papiertitel: ChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG Capabilities
Papieradresse: https://arxiv.org/pdf/2407.14482
Vor Kurzem, Die Erweiterung der Kontextfensterlänge von LLM ist ein wichtiger Forschungs- und Entwicklungs-Hotspot. Diese Website berichtete beispielsweise einmal „Direkt auf unendliche Länge erweitern, Google Infini-Transformer beendet die Kontextlängendebatte“ .
Alle führenden proprietären LLMs unterstützen sehr große Kontextfenster – Sie können Hunderte von Textseiten in einer einzigen Eingabeaufforderung eingeben. Beispielsweise betragen die Kontextfenstergrößen von GPT-4 Turbo und Claude 3.5 Sonnet 128 KB bzw. 200 KB. Gemini 1.5 Pro kann einen Kontext mit einer Länge von 10 Mio. unterstützen, was erstaunlich ist.
Aber auch große Open-Source-Modelle holen auf. QWen2-72B-Instruct und Yi-34B unterstützen beispielsweise 128 KB bzw. 200 KB Kontextfenster. Allerdings sind die Trainingsdaten und technischen Details dieser Modelle nicht öffentlich verfügbar, was ihre Reproduktion erschwert. Darüber hinaus basiert die Bewertung dieser Modelle meist auf synthetischen Aufgaben und kann die Leistung bei realen Downstream-Aufgaben nicht genau darstellen. Mehrere Studien haben beispielsweise gezeigt, dass es immer noch eine erhebliche Lücke zwischen offenem LLM und führenden proprietären Modellen für reale Langzeitkontextverständnisaufgaben gibt.
Und dem NVIDIA-Team gelang es, die Leistung des offenen Llama-3 bei realen Langzeitkontextverständnisaufgaben mit dem proprietären GPT-4 Turbo gleichzuziehen.
In der LLM-Community werden Long-Context-Funktionen manchmal als eine Technologie angesehen, die mit RAG konkurriert. Aber realistisch gesehen können sich diese Technologien gegenseitig ergänzen.
Für LLM mit einem langen Kontextfenster können Sie abhängig von den nachgelagerten Aufgaben und dem Kompromiss zwischen Genauigkeit und Effizienz in Betracht ziehen, eine große Textmenge an die Eingabeaufforderung anzuhängen, oder Sie können Abrufmethoden verwenden, um relevante Informationen effizient daraus zu extrahieren eine große Textmenge. RAG hat klare Effizienzvorteile und kann für abfragebasierte Aufgaben problemlos relevante Informationen aus Milliarden von Token abrufen. Dies ist ein Vorteil, den lange Kontextmodelle nicht haben können. Andererseits eignen sich Modelle mit langem Kontext sehr gut für Aufgaben wie die Zusammenfassung von Dokumenten, für die RAG möglicherweise nicht gut geeignet ist.
Daher sind für ein fortgeschrittenes LLM beide Fähigkeiten erforderlich, sodass eine davon basierend auf den nachgelagerten Aufgaben und Genauigkeits- und Effizienzanforderungen berücksichtigt werden kann.
Zuvor konnte NVIDIAs Open-Source-Modell ChatQA 1.5 GPT-4-Turbo bei RAG-Aufgaben übertreffen. Aber das ist noch nicht alles. Jetzt verfügen sie über Open-Source-ChatQA 2, das auch Funktionen zum Verständnis langer Kontexte integriert, die mit GPT-4-Turbo vergleichbar sind!
Konkret basieren sie auf dem Llama-3-Modell, erweitern dessen Kontextfenster auf 128 KB (auf Augenhöhe mit GPT-4-Turbo) und statten es gleichzeitig mit dem besten derzeit verfügbaren Long Context Retriever aus.
Erweitern Sie das Kontextfenster auf 128K.
Wie hat NVIDIA also das Kontextfenster von Llama-3 von 8K auf 128K vergrößert? Zunächst erstellten sie ein langes Kontext-Pre-Training-Korpus auf der Grundlage von Slimpajama und verwendeten dabei die Methode aus dem Artikel „Data Engineering for scaling language models to 128k context“ von Fu et al.
Sie haben während des Trainingsprozesses auch eine interessante Entdeckung gemacht: Im Vergleich zur Verwendung der ursprünglichen Start- und End-Tokens zur Trennung verschiedener Dokumente eine bessere Wirkung. Sie spekulieren, dass der Grund darin liegt, dass die
Verwendung langer Kontextdaten zur Feinabstimmung von Anweisungen
Das Team hat außerdem eine Methode zur Feinabstimmung von Anweisungen entwickelt, die gleichzeitig die Fähigkeiten des Modells zum Verständnis langer Kontexte und die RAG-Leistung verbessern kann.
Konkret ist diese Methode zur Feinabstimmung der Anleitung in drei Phasen unterteilt. Die ersten beiden Phasen sind die gleichen wie bei ChatQA 1.5, d. h. zuerst wird das Modell auf dem hochwertigen 128K-Datensatz zur Befehlskonformität trainiert und dann auf einer Mischung aus Gesprächs-Q&A-Daten und bereitgestelltem Kontext trainiert. Allerdings sind die in beiden Phasen beteiligten Kontexte relativ kurz – die maximale Sequenzlänge beträgt nicht mehr als 4K-Tokens. Um die Größe des Kontextfensters des Modells auf 128.000 Token zu erhöhen, sammelte das Team einen Long-Supervised-Fine-Tuning-Datensatz (SFT).
Es werden zwei Erfassungsmethoden angewendet:
1. Für SFT-Datensequenzen, die kürzer als 32.000 sind: Verwendung vorhandener langer Kontextdatensätze basierend auf LongAlpaca12k, GPT-4-Proben von Open Orca und Long Data Collections.
2. Für Daten mit Sequenzlängen zwischen 32k und 128k: Aufgrund der Schwierigkeit, solche SFT-Proben zu sammeln, wählten sie synthetische Datensätze. Sie verwendeten NarrativeQA, das sowohl die Grundwahrheit als auch semantisch relevante Absätze enthält. Sie stellten alle relevanten Absätze zusammen und fügten nach dem Zufallsprinzip echte Zusammenfassungen ein, um wirklich lange Dokumente für Frage- und Antwortpaare zu simulieren.
Dann werden der in den ersten beiden Phasen erhaltene SFT-Datensatz voller Länge und der kurze SFT-Datensatz miteinander kombiniert und dann trainiert. Hier ist die Lernrate auf 3e-5 und die Stapelgröße auf 32 eingestellt.
Long Context Retriever trifft auf Long Context LLM
Es gibt einige Probleme mit dem RAG-Prozess, der derzeit von LLM verwendet wird:
1 Um genaue Antworten zu generieren, führt der Top-k-Block-für-Block-Abruf nicht- vernachlässigbare Kontextfragmente. Beispielsweise unterstützten frühere hochmoderne Retriever, die auf dichter Einbettung basieren, nur 512 Token.
2. Ein kleiner Top-K (z. B. 5 oder 10) führt zu einer relativ niedrigen Rückrufrate, während ein großer Top-K (z. B. 100) zu schlechten Generierungsergebnissen führt, da das vorherige LLM nicht gut verwendet werden kann . Gestückelter Kontext.
Um dieses Problem zu lösen, schlägt das Team vor, den neuesten Long Context Retriever zu verwenden, der Tausende von Token unterstützt. Konkret entschieden sie sich für die Verwendung des E5-Mistral-Einbettungsmodells als Retriever.
Tabelle 1 vergleicht den Top-K-Abruf für verschiedene Blockgrößen und die Gesamtzahl der Token im Kontextfenster.

Beim Vergleich der Änderungen in der Anzahl der Token von 3000 auf 12000 stellte das Team fest, dass die Ergebnisse umso besser waren, je mehr Token vorhanden waren, was bestätigte, dass die Langzeitkontextfähigkeit des neuen Modells tatsächlich gut ist. Sie fanden außerdem heraus, dass es einen besseren Kompromiss zwischen Kosten und Leistung gibt, wenn die Gesamtzahl der Token 6000 beträgt. Als die Gesamtzahl der Token auf 6000 festgelegt wurde, stellten sie fest, dass die Ergebnisse umso besser waren, je größer der Textblock war. Daher wählten sie in ihren Experimenten als Standardeinstellungen eine Blockgröße von 1200 und Top-5-Textblöcke.
Experimente
Bewertungsbenchmarks
Um eine umfassende Bewertung durchzuführen und verschiedene Kontextlängen zu analysieren, verwendete das Team drei Arten von Bewertungsbenchmarks:
1. Lange Kontextbenchmarks, mehr als 100.000 Token;
2. Mittellanger Kontext-Benchmark, weniger als 32.000 Token;
3. Kurzer Kontext-Benchmark, weniger als 4.000 Token.
Wenn eine Downstream-Aufgabe RAG verwenden kann, wird sie RAG verwenden.
Ergebnisse
Das Team führte zunächst einen „Nadel im Heuhaufen“-Test auf Basis synthetischer Daten durch und testete dann das reale Langzeitkontextverständnis und die RAG-Fähigkeiten des Modells.
1. Die Nadel im Heuhaufen-Test
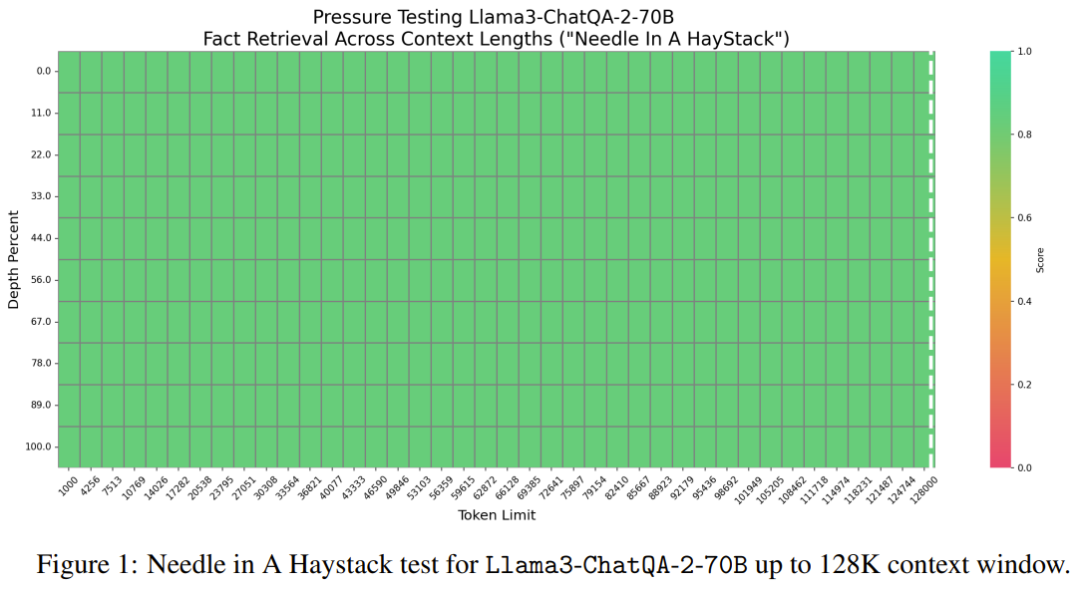
Llama3-ChatQA-2-70B Kannst du die Zielnadel im Textmeer finden? Dies ist eine synthetische Aufgabe, die üblicherweise zum Testen der Langkontextfähigkeit von LLM verwendet wird und als Beurteilung des Schwellenwerts von LLM angesehen werden kann. Abbildung 1 zeigt die Leistung des neuen Modells in 128.000 Token. Es ist ersichtlich, dass die Genauigkeit des neuen Modells 100 % erreicht. Dieser Test bestätigte, dass das neue Modell über perfekte Fähigkeiten zum Abrufen langer Kontexte verfügt.
2. Lange Kontextauswertung über 100.000 Token
Bei realen Aufgaben von InfiniteBench bewertete das Team die Leistung des Modells, als die Kontextlänge 100.000 Token überschritt. Die Ergebnisse sind in Tabelle 2 dargestellt.
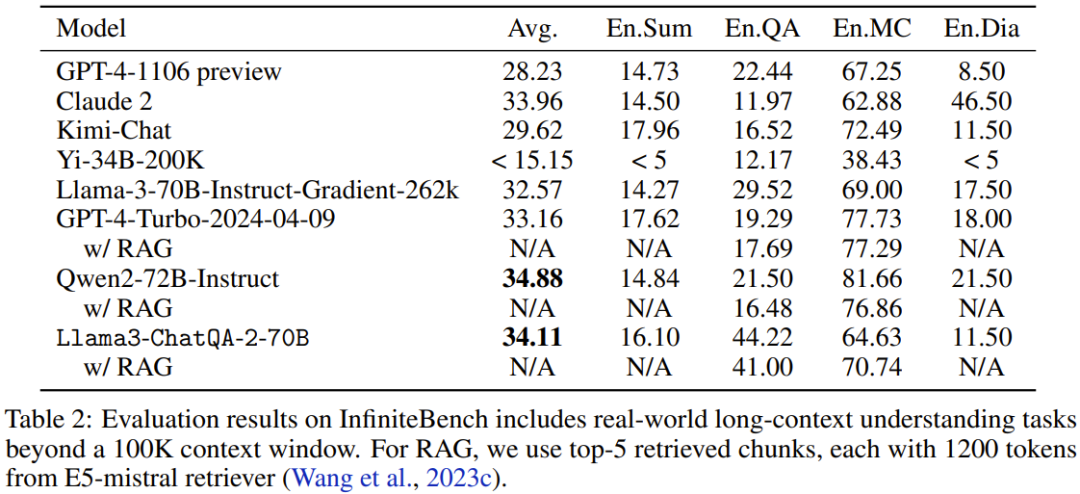
Es ist ersichtlich, dass das neue Modell eine bessere Leistung erbringt als viele derzeit beste Modelle, wie z. B. GPT4-Turbo-2024-04-09 (33,16), GPT4-1106 Vorschau (28,23), Llama-3-70B- Instruct -Gradient-262k (32,57) und Claude 2 (33,96). Darüber hinaus liegt die Punktzahl des neuen Modells sehr nahe an der Höchstpunktzahl von 34,88, die von Qwen2-72B-Instruct erzielt wurde. Insgesamt ist Nvidias neues Modell durchaus konkurrenzfähig.
3. Auswertung mittellanger Kontexte mit einer Anzahl von Token innerhalb von 32.000.
Tabelle 3 zeigt die Leistung jedes Modells, wenn die Anzahl der Token im Kontext innerhalb von 32.000 liegt.
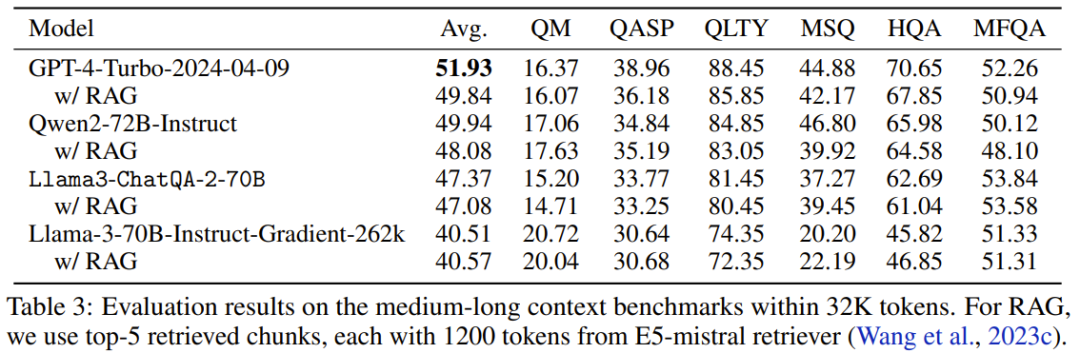
보시다시피 GPT-4-Turbo-2024-04-09의 점수가 51.93으로 가장 높습니다. 새로운 모델의 점수는 47.37점으로 Llama-3-70B-Instruct-Gradient-262k보다 높지만 Qwen2-72B-Instruct보다는 낮습니다. 그 이유는 Qwen2-72B-Instruct의 사전 훈련이 32K 토큰을 많이 사용하는 반면 팀에서 사용하는 지속적인 사전 훈련 코퍼스는 훨씬 작기 때문일 수 있습니다. 또한 그들은 모든 RAG 솔루션이 긴 컨텍스트 솔루션보다 더 나쁜 성능을 발휘한다는 사실을 발견했습니다. 이는 이러한 모든 최첨단 긴 컨텍스트 LLM이 컨텍스트 창 내에서 32K 토큰을 처리할 수 있음을 나타냅니다.
4. ChatRAG Bench: 4K 미만의 토큰 수를 사용한 짧은 컨텍스트 평가
ChatRAG Bench에서 팀은 컨텍스트 길이가 4K 토큰 미만일 때 모델의 성능을 평가했습니다. 표 4를 참조하세요.
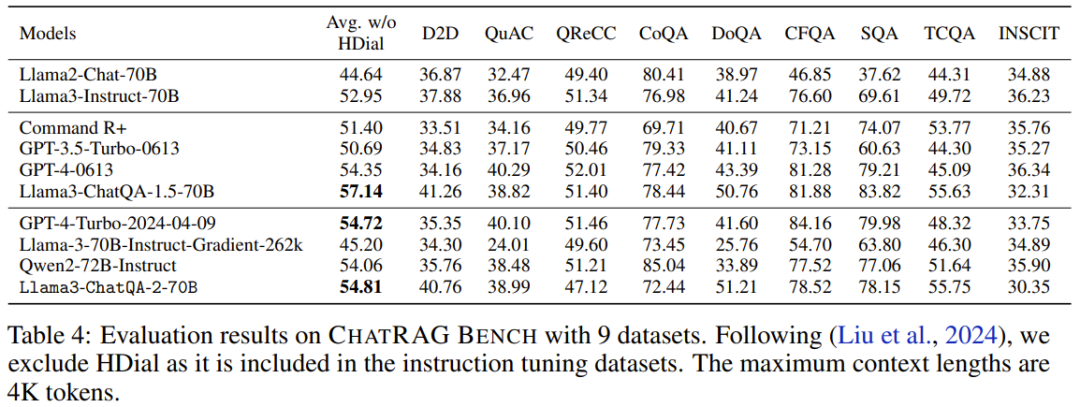
새 모델의 평균 점수는 54.81점입니다. 이 결과는 Llama3-ChatQA-1.5-70B만큼 좋지는 않지만 GPT-4-Turbo-2024-04-09 및 Qwen2-72B-Instruct보다는 여전히 좋습니다. 이는 요점을 입증합니다. 짧은 컨텍스트 모델을 긴 컨텍스트 모델로 확장하는 데는 비용이 듭니다. 이는 또한 탐색할 가치가 있는 연구 방향으로 이어집니다. 짧은 컨텍스트 작업의 성능에 영향을 주지 않고 컨텍스트 창을 더 확장하는 방법은 무엇입니까?
5. RAG와 긴 컨텍스트 비교
표 5와 6은 다양한 컨텍스트 길이를 사용할 때 긴 컨텍스트 솔루션과 RAG의 성능을 비교합니다. 시퀀스 길이가 100K를 초과하면 En.Sum 및 En.Dia에 대해 RAG 설정을 직접 사용할 수 없기 때문에 En.QA 및 En.MC의 평균 점수만 보고됩니다.
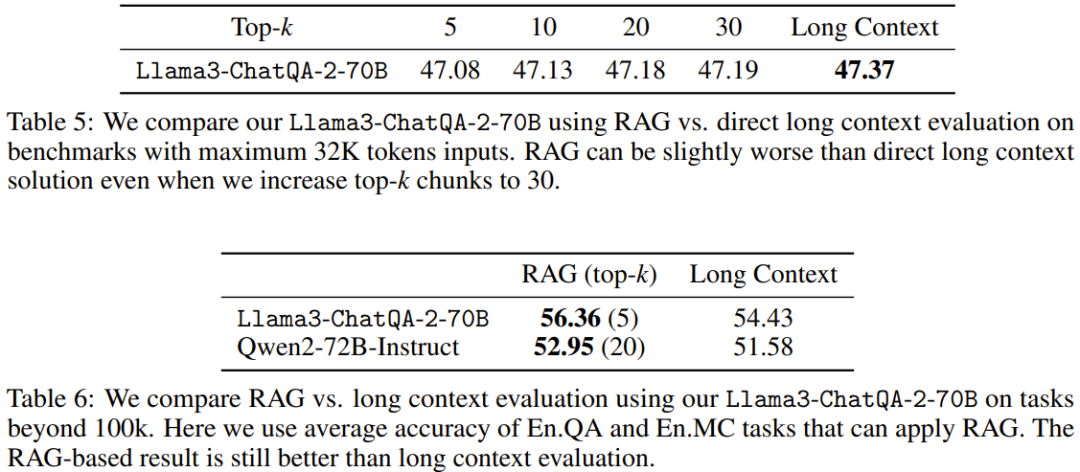
다운스트림 작업의 시퀀스 길이가 32K 미만인 경우 새로 제안된 긴 컨텍스트 솔루션이 RAG보다 성능이 뛰어난 것을 볼 수 있습니다. 즉, RAG를 사용하면 비용이 절감되지만 정확성이 떨어지게 됩니다.
반면에 RAG(Llama3-ChatQA-2-70B의 경우 상위 5위, Qwen2-72B-Instruct의 경우 상위 20위)는 컨텍스트 길이가 100K를 초과할 때 긴 컨텍스트 솔루션보다 성능이 뛰어납니다. 이는 토큰 수가 128K를 초과하면 현재 최고의 장기 컨텍스트 LLM이라도 효과적인 이해와 추론을 달성하는 데 어려움을 겪을 수 있음을 의미합니다. 이 경우 정확도는 높이고 추론 비용은 낮출 수 있으므로 가능하면 RAG를 사용하는 것이 좋습니다.
위 내용은 NVIDIA 대화 모델 ChatQA는 버전 2.0으로 발전했으며 컨텍스트 길이는 128K로 언급되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



