

'Defect Spectrum'은 기존 결함 감지의 경계를 뛰어넘어 초고정밀 및 풍부한 의미론적 산업 결함 감지를 최초로 달성합니다.

현대 제조업에서 정확한 결함 검출은 제품 품질을 보장하는 열쇠일 뿐만 아니라 생산 효율성을 향상시키는 핵심이기도 합니다. 그러나 기존 결함 감지 데이터세트는 실제 적용에 필요한 정확성과 의미론적 풍부함이 부족한 경우가 많아 모델이 특정 결함 카테고리나 위치를 식별할 수 없게 됩니다.
이 문제를 해결하기 위해 홍콩 과학기술대학교 광저우와 Simou Technology로 구성된 최고 연구팀이 산업 결함에 대한 상세하고 의미론적으로 풍부한 대규모 주석을 제공하는 "결함 스펙트럼" 데이터 세트를 혁신적으로 개발했습니다. 표 1에서 볼 수 있듯이, 다른 산업 데이터 세트와 비교하여 "Defect Spectrum" 데이터 세트는 가장 많은 결함 주석(5438개 결함 샘플), 가장 상세한 결함 분류(125개 결함 범주)를 제공하며 다양한 유형의 결함을 모두 제공합니다. 픽셀 수준의 상세한 라벨을 제공합니다. 또한 데이터세트는 각 결함 샘플에 대한 자세한 언어적 설명도 제공합니다. 구체적인 주석 비교는 그림 1에 나와 있습니다.

그림 1: 다른 산업용 데이터 세트와 비교하여 Defect Spectrum은 더 정확하고 주석이 더 풍부합니다
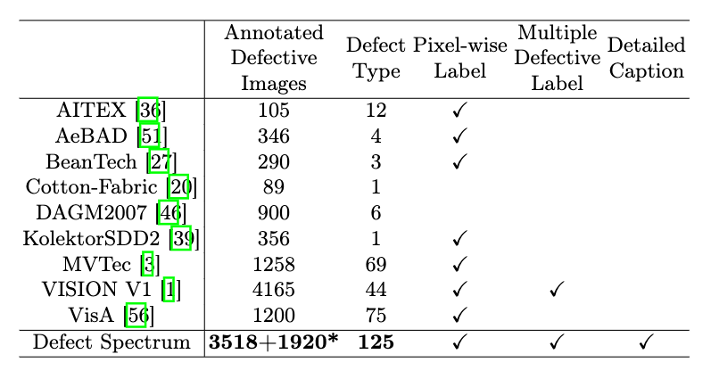
표 1: Defect Spectrum과 기타 기존 데이터 세트의 수량 및 성격 비교
"Defect Spectrum"은 최첨단 확산 모델을 기반으로 하는 혁신적인 접근 방식인 "DefectGen"을 도입합니다. 매우 적은 양의 산업 결함 데이터를 사용하여 이미지와 픽셀 수준 결함 라벨을 생성함으로써 이 방법은 산업 결함 감지 모델의 성능을 크게 향상시키며 여러 산업 표준 데이터 세트(예: MVTec AD, VISION, DAGM2007 및 Cotton-Fabric) 전례 없는 성능 혁신.
이 획기적인 연구는 결함 감지의 정확성을 크게 향상시킬 뿐만 아니라 복잡한 산업 환경에서 AI를 적용할 수 있는 새로운 가능성을 열어줍니다. 프로젝트의 코드와 모델은 완전히 오픈 소스입니다.

- Paper: 결함 스펙트럼: 풍부한 의미를 갖춘 대규모 결함 데이터 세트의 세분화된 보기
- Paper 링크:https://www.php.cn/link/136aa7fe7fd745073fec3fb4ef67e3b9
- 프로젝트 링크: https : //envision-research.github.io/Defect_Spectrum/
- Github 저장소: https://github.com/EnVision-Research/Defect_Spectrum
- 데이터세트 저장소: https://huggingface.co/datasets/DefectSpectrum/Defect_Spectrum
기존 결함 감지 한계를 극복하고 실제 생산에 더 가까이 다가가세요
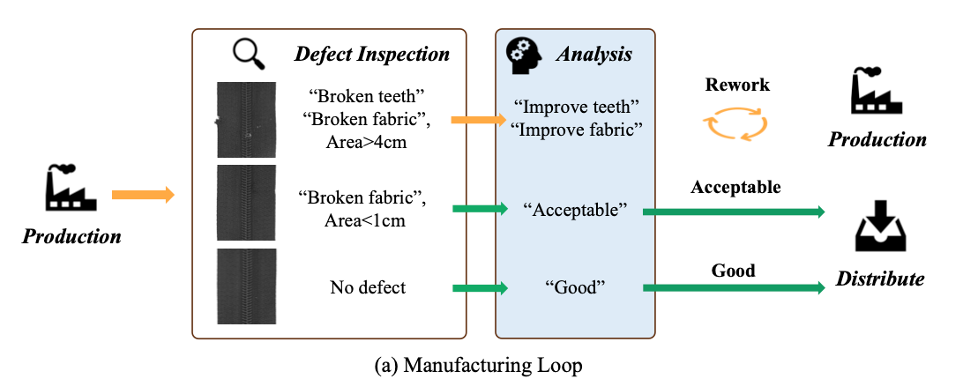
그림 2: 실제 산업 생산, 결함 감지 및 분석의 폐쇄 루프
실제 산업 생산에서는 결함 감지에 대한 요구 사항이 더 자세합니다. 공장에서는 그림 2와 같이 결함 부품을 관리하면서 수익성을 보장해야 합니다. 그러나 기존의 결함 검출 데이터 세트는 실제 응용에 필요한 정확성과 의미론적 풍부함이 부족한 경우가 많습니다. 예를 들어 금속판 표면에서 벗겨지는 페인트의 면적이 넓다면 결함 면적은 크지만 문제가 발생할 수 있습니다. 금속판에 기능적 영향은 거의 없습니다. 그러나 금속판 내부에 작은 균열이 생기면 그 균열이 머리카락만큼 작더라도 압력을 가하면 금속판이 순간적으로 부서져 성능에 큰 영향을 미치고 심지어 심각한 안전 위험을 초래할 수 있습니다.
좀 더 정확히 말하자면, 옷의 지퍼 톱니가 어긋나 있다고 가정해 보세요. 이 결함은 겉보기에는 크지 않거나 쉽게 감지할 수 없을지라도 옷의 기능에 심각한 영향을 미치고 지퍼가 제대로 작동하지 않게 됩니다. 소비자는 수리를 위해 공장에 반품해야 했습니다. 다만, 의류의 원단에 약간의 찰과상이나 약간의 색상차이 등의 불량이 발생한 경우에는 그 크기와 충격을 잘 따져볼 필요가 있습니다. 소규모 직물 결함은 허용 가능한 한도 내에서 분류될 수 있으므로 이러한 제품을 할인된 가격에 판매하는 등 다양한 유통 전략을 통해 판매할 수 있으므로 전체 품질 표준에 영향을 주지 않고 제품 흐름을 유지할 수 있습니다.
이 모든 것의 이면에는 "Defect Spectrum" 데이터 세트가 모든 것에 대한 통찰력을 갖춘 만능 탐정과 같습니다. 광범위한 산업 결함 유형을 다룰 뿐만 아니라 각 결함에 대해 상세하고 풍부한 설명을 제공합니다. 이 강력한 도구를 사용하면 결함 감지 시스템이 세부 사항을 놓치지 않고 다양한 결함을 보다 정확하게 식별하고 분류할 수 있습니다.
실제 생산 라인에서 검사 시스템이 "결함 스펙트럼" 데이터 세트의 도움으로 이 중대한 결함을 신속하게 식별하고 즉시 표시한 후 수리를 위해 공장으로 반환할 수 있다고 상상해 보세요. 동시에, 직물의 사소한 결함이나 색상 차이에 대해 시스템은 결함에 대한 상세한 표시를 기반으로 허용 범위 내에 있는지 여부를 판단하고 할인된 가격에 판매할지 여부를 결정할 수 있습니다. 이러한 유연한 처리 방법은 제품 품질을 향상시킬 뿐만 아니라 생산 효율성과 비용 관리도 보장합니다.
MVTEC 및 AeBAD와 같은 기존 데이터 세트는 픽셀 수준 주석을 제공하지만 바이너리 마스크로 제한되는 경우가 많으며 결함 유형과 위치를 자세히 구분할 수 없습니다. "결함 스펙트럼" 데이터 세트는 업계의 4가지 주요 벤치마크와의 협력을 통해 기존 결함 주석을 재평가하고 개선합니다. 예를 들어 미세한 흠집이나 찌그러진 부분은 더욱 정밀하게 윤곽을 잡아주고, 누락된 결함은 전문가의 도움을 받아 채워줌으로써 포괄적이고 정확한 주석을 보장합니다.
혁신적인 결함 생성 모델 "Defect-Gen"
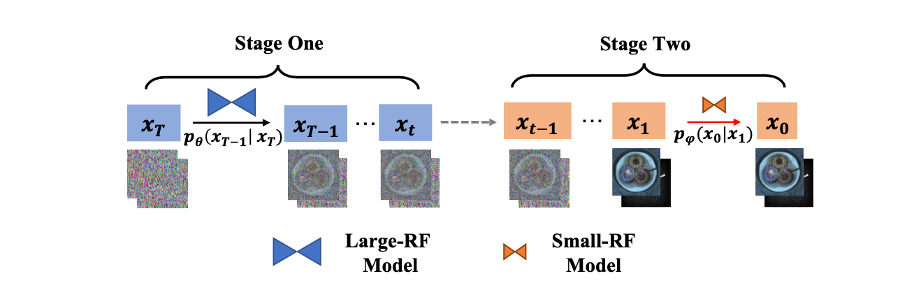
그림 3: Defect-Gen의 2단계 생성 프로세스 개략도
현재 데이터 세트에서 결함 샘플이 부족한 문제에 직면하여, 우리는 2단계 확산 발생기인 "Defect-Gen"을 제안했습니다. 이 생성기는 두 가지 주요 방법을 통해 제한된 수의 샘플로 이미지의 다양성과 품질을 향상시킵니다. 첫째, 패치 수준 모델링을 사용하고, 둘째, 수용 필드를 제한합니다.
기존 확산 모델은 훈련 샘플이 거의 없을 때 과적합되기 쉽습니다. 생성된 결과는 다양성이 부족하고 종종 훈련 샘플만 기억합니다. 우리 모델은 데이터 차원을 줄이고 표본 크기를 늘려 이러한 과적합 현상을 효과적으로 줄입니다.
전체 이미지 구조를 표현하는데 있어서 패치레벨 모델링의 단점을 보완하기 위해 2단계 확산과정을 제안합니다. 먼저 대규모 수용 필드 모델을 사용하여 초기 단계에서 기하학적 구조를 캡처한 다음 작은 수용 필드 모델로 전환하여 후속 단계에서 로컬 패치를 생성합니다. 이는 이미지 품질을 유지하면서 생성된 이미지의 다양성을 크게 향상시킵니다. 두 모델의 액세스 포인트와 수용 필드를 조정함으로써 우리 모델은 충실도와 다양성 사이의 적절한 균형을 달성합니다.
"Defect-Gen"을 통해 산업 결함 검출을 위한 보다 풍부하고 다양한 교육 샘플을 제공하여 자동화 검사 기술 발전을 촉진합니다.
종합 평가 및 향후 연구 방향
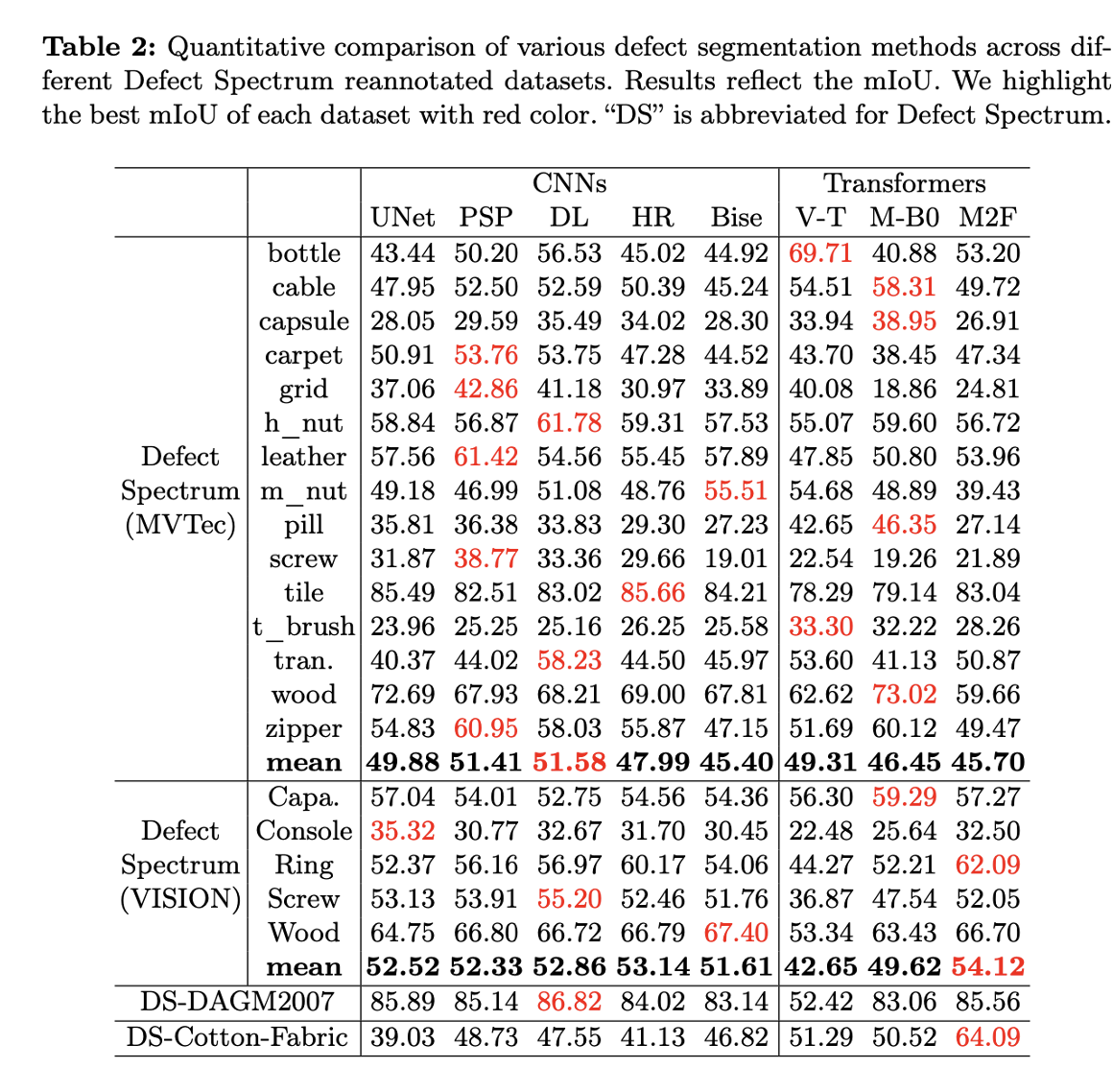 표 2: Defect Spectrum 데이터 세트의 일부 결함 탐지 네트워크
표 2: Defect Spectrum 데이터 세트의 일부 결함 탐지 네트워크

표 3: Defect Spectrum 데이터 세트의 실제 평가 기준  표 4: 실제 평가에서 Defect Spectrum의 우수한 성능
표 4: 실제 평가에서 Defect Spectrum의 우수한 성능
Defect Spectrum 데이터에 대한 우리의 평가 세트 표 3과 같이 종합적으로 평가하고 주석을 달았습니다. 이 실험을 통해 다양한 산업 결함 감지 문제에서 결함 스펙트럼의 적용 가능성과 우수성을 검증했습니다. 표 4는 원래 데이터 세트와 비교하여 데이터 세트로 훈련된 모델이 재현율을 10.74% 증가시키고 위양성율을 33.1% 감소시켰음을 보여줍니다. 또한 데이터 세트의 구성 및 평가 프로세스는 견고한 연구 기반을 제공할 뿐만 아니라 업계 및 학계 연구자들이 산업 결함 감지의 복잡한 요구 사항에 맞는 고급 모델을 평가하고 개발할 수 있는 플랫폼을 제공합니다.
Defect Spectrum 데이터 세트의 도입은 산업 생산을 위한 총격과 같습니다. 이는 결함 감지 시스템을 실제 생산 요구 사항에 더 가깝게 만들고 효율적이고 정확한 결함 관리를 달성합니다. 동시에 각 결함의 범주와 위치를 기록함으로써 공장은 지속적으로 생산 프로세스를 최적화하고 제품 수리 방법을 개선하며 궁극적으로 더 높은 생산 효율성과 제품 품질을 달성할 수 있습니다.
Summary
실제 산업 검사에 필요한 높은 정확도와 풍부한 결함 의미를 제공하고 모델이 결함 카테고리나 위치를 식별할 수 없는 문제를 해결하는 Defect Spectrum 데이터세트와 DefectGen 결함 생성기를 출시했습니다. .
우리는 결함 스펙트럼 데이터 세트에 대한 종합적인 평가를 수행하여 다양한 산업 결함 감지 과제에서 적용 가능성과 우월성을 검증했습니다. 원래 데이터 세트와 비교하여 데이터 세트로 훈련된 모델은 개선되었습니다. 재현율은 10.74%로 False 오류가 감소했습니다. 긍정률 33.1%.
참조:
1. Bai, H., Mou, S., Likhomanenko, T., Cinbis, R.G., Tuzel, O., Huang, P., Shan, J., Shi, J., Cao, M.:视觉数据集:视觉数据集的基准基于视觉的工业检测。 arXiv 预印本 arXiv:2306.07890 (2023)
2. Silvestre-Blanes, J.、Albero-Albero, T.、Miralles, I.、Pérez-Llorens, R.、Moreno, J.:用于缺陷检测方法和结果的公共织物数据库。 Autex 研究杂志19(4), 363–374 (2019)。 https://doi.org/doi:10.2478/aut-2019-0035,https://doi.org/10.2478/aut-2019-0035
3. 张Z.,赵Z.,张X.,孙C.,陈X.:具有域转移的工业异常检测:真实世界数据集和屏蔽多尺度重建。 arXiv 预印本 arXiv:2304.02216 (2023)
4。 Mishra, P.、Verk, R.、Fornasier, D.、Piciarelli, C.、Foresti, G.L.:VT-ADL:用于图像异常检测和定位的视觉变换器网络。见:第 30 届 IEEE/IES 国际工业电子研讨会 (ISIE)(2021 年 6 月)
5。 Incorporated, C.:标准织物缺陷术语表 (2023),URL:https://www.棉花公司com / 质量 - 产品 / 纺织品 - 资源 / 面料 - 缺陷 - 术语表
6。 Wieler, M., Hahn, T.:工业光学检测的弱监督学习。见:DAGM 研讨会。卷。 6(2007)
7。 Tabernik, D.、Šela, S.、Skvarč, J.、Skočaj, D.:基于分割的深度学习表面缺陷检测方法。智能制造杂志31(3), 759–776 (2020)
8. Bergmann, P., Fauser, M., Sattlegger, D., Steger, C.:Mvtec ad——用于无监督异常检测的综合现实世界数据集。见:IEEE/CVF 计算机视觉和模式识别会议论文集。第 9592–9600 页(2019)
9。 Zou, Y.、Jeong, J.、Pemula, L.、Zhang, D.、Dabeer, O.:用于异常检测和分割的找出差异自监督预训练(2022)
위 내용은 'Defect Spectrum'은 기존 결함 감지의 경계를 뛰어넘어 초고정밀 및 풍부한 의미론적 산업 결함 감지를 최초로 달성합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7499
7499
 15
1377
52
77
11
52
19
19
52
15
1377
52
77
11
52
19
19
52

 'Defect Spectrum'은 기존 결함 감지의 경계를 뛰어넘어 초고정밀 및 풍부한 의미론적 산업 결함 감지를 최초로 달성합니다.
Jul 26, 2024 pm 05:38 PM
'Defect Spectrum'은 기존 결함 감지의 경계를 뛰어넘어 초고정밀 및 풍부한 의미론적 산업 결함 감지를 최초로 달성합니다.
Jul 26, 2024 pm 05:38 PM
현대 제조업에서 정확한 결함 검출은 제품 품질을 보장하는 열쇠일 뿐만 아니라 생산 효율성을 향상시키는 핵심이기도 합니다. 그러나 기존 결함 감지 데이터세트는 실제 적용에 필요한 정확성과 의미론적 풍부함이 부족한 경우가 많아 모델이 특정 결함 카테고리나 위치를 식별할 수 없게 됩니다. 이 문제를 해결하기 위해 광저우 과학기술대학교와 Simou Technology로 구성된 최고 연구팀은 산업 결함에 대한 상세하고 의미론적으로 풍부한 대규모 주석을 제공하는 "DefectSpectrum" 데이터 세트를 혁신적으로 개발했습니다. 표 1에서 볼 수 있듯이, 다른 산업 데이터 세트와 비교하여 "DefectSpectrum" 데이터 세트는 가장 많은 결함 주석(5438개의 결함 샘플)과 가장 상세한 결함 분류(125개의 결함 카테고리)를 제공합니다.
 NVIDIA 대화 모델 ChatQA는 버전 2.0으로 발전했으며 컨텍스트 길이는 128K로 언급되었습니다.
Jul 26, 2024 am 08:40 AM
NVIDIA 대화 모델 ChatQA는 버전 2.0으로 발전했으며 컨텍스트 길이는 128K로 언급되었습니다.
Jul 26, 2024 am 08:40 AM
오픈 LLM 커뮤니티는 백개의 꽃이 피어 경쟁하는 시대입니다. Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 등을 보실 수 있습니다. 훌륭한 연기자. 그러나 GPT-4-Turbo로 대표되는 독점 대형 모델과 비교하면 개방형 모델은 여전히 많은 분야에서 상당한 격차를 보이고 있습니다. 일반 모델 외에도 프로그래밍 및 수학을 위한 DeepSeek-Coder-V2, 시각 언어 작업을 위한 InternVL과 같이 핵심 영역을 전문으로 하는 일부 개방형 모델이 개발되었습니다.
 Google AI가 IMO 수학 올림피아드 은메달을 획득하고 수학적 추론 모델 AlphaProof가 출시되었으며 강화 학습이 다시 시작되었습니다.
Jul 26, 2024 pm 02:40 PM
Google AI가 IMO 수학 올림피아드 은메달을 획득하고 수학적 추론 모델 AlphaProof가 출시되었으며 강화 학습이 다시 시작되었습니다.
Jul 26, 2024 pm 02:40 PM
AI의 경우 수학 올림피아드는 더 이상 문제가 되지 않습니다. 목요일에 Google DeepMind의 인공 지능은 AI를 사용하여 올해 국제 수학 올림피아드 IMO의 실제 문제를 해결하는 위업을 달성했으며 금메달 획득에 한 걸음 더 다가섰습니다. 지난 주 막 끝난 IMO 대회에는 대수학, 조합론, 기하학, 수론 등 6개 문제가 출제됐다. 구글이 제안한 하이브리드 AI 시스템은 4문제를 맞혀 28점을 얻어 은메달 수준에 이르렀다. 이달 초 UCLA 종신 교수인 테렌스 타오(Terence Tao)가 상금 100만 달러의 AI 수학 올림피아드(AIMO Progress Award)를 추진했는데, 예상외로 7월 이전에 AI 문제 해결 수준이 이 수준으로 향상됐다. IMO에서 동시에 질문을 해보세요. 가장 정확하게 하기 어려운 것이 IMO인데, 역사도 가장 길고, 규모도 가장 크며, 가장 부정적이기도 합니다.
 자연의 관점: 의학 분야의 인공지능 테스트는 혼란에 빠졌습니다. 어떻게 해야 할까요?
Aug 22, 2024 pm 04:37 PM
자연의 관점: 의학 분야의 인공지능 테스트는 혼란에 빠졌습니다. 어떻게 해야 할까요?
Aug 22, 2024 pm 04:37 PM
Editor | ScienceAI 제한된 임상 데이터를 기반으로 수백 개의 의료 알고리즘이 승인되었습니다. 과학자들은 누가 도구를 테스트해야 하며 최선의 방법은 무엇인지에 대해 토론하고 있습니다. 데빈 싱(Devin Singh)은 응급실에서 오랜 시간 치료를 기다리던 중 심장마비를 겪는 소아환자를 목격했고, 이를 계기로 대기시간을 단축하기 위해 AI 적용을 모색하게 됐다. SickKids 응급실의 분류 데이터를 사용하여 Singh과 동료들은 잠재적인 진단을 제공하고 테스트를 권장하는 일련의 AI 모델을 구축했습니다. 한 연구에 따르면 이러한 모델은 의사 방문 속도를 22.3% 단축하여 의료 검사가 필요한 환자당 결과 처리 속도를 거의 3시간 단축할 수 있는 것으로 나타났습니다. 그러나 인공지능 알고리즘의 연구 성공은 이를 입증할 뿐이다.
 수백만 개의 결정 데이터로 훈련하여 결정학적 위상 문제를 해결하는 딥러닝 방법인 PhAI가 Science에 게재되었습니다.
Aug 08, 2024 pm 09:22 PM
수백만 개의 결정 데이터로 훈련하여 결정학적 위상 문제를 해결하는 딥러닝 방법인 PhAI가 Science에 게재되었습니다.
Aug 08, 2024 pm 09:22 PM
Editor |KX 오늘날까지 단순한 금속부터 큰 막 단백질에 이르기까지 결정학을 통해 결정되는 구조적 세부 사항과 정밀도는 다른 어떤 방법과도 비교할 수 없습니다. 그러나 가장 큰 과제인 소위 위상 문제는 실험적으로 결정된 진폭에서 위상 정보를 검색하는 것입니다. 덴마크 코펜하겐 대학의 연구원들은 결정 위상 문제를 해결하기 위해 PhAI라는 딥러닝 방법을 개발했습니다. 수백만 개의 인공 결정 구조와 그에 상응하는 합성 회절 데이터를 사용하여 훈련된 딥러닝 신경망은 정확한 전자 밀도 맵을 생성할 수 있습니다. 연구는 이 딥러닝 기반의 순순한 구조 솔루션 방법이 단 2옹스트롬의 해상도로 위상 문제를 해결할 수 있음을 보여줍니다. 이는 원자 해상도에서 사용할 수 있는 데이터의 10~20%에 해당하는 반면, 기존의 순순한 계산은
 대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
편집자 |ScienceAI 질문 응답(QA) 데이터 세트는 자연어 처리(NLP) 연구를 촉진하는 데 중요한 역할을 합니다. 고품질 QA 데이터 세트는 모델을 미세 조정하는 데 사용될 수 있을 뿐만 아니라 LLM(대형 언어 모델)의 기능, 특히 과학적 지식을 이해하고 추론하는 능력을 효과적으로 평가하는 데에도 사용할 수 있습니다. 현재 의학, 화학, 생물학 및 기타 분야를 포괄하는 과학적인 QA 데이터 세트가 많이 있지만 이러한 데이터 세트에는 여전히 몇 가지 단점이 있습니다. 첫째, 데이터 형식이 비교적 단순하고 대부분이 객관식 질문이므로 평가하기 쉽지만 모델의 답변 선택 범위가 제한되고 모델의 과학적 질문 답변 능력을 완전히 테스트할 수 없습니다. 이에 비해 개방형 Q&A는
 PRO | MoE 기반의 대형 모델이 더 주목받는 이유는 무엇인가요?
Aug 07, 2024 pm 07:08 PM
PRO | MoE 기반의 대형 모델이 더 주목받는 이유는 무엇인가요?
Aug 07, 2024 pm 07:08 PM
2023년에는 AI의 거의 모든 분야가 전례 없는 속도로 진화하고 있다. 동시에 AI는 구체화된 지능, 자율주행 등 핵심 트랙의 기술적 한계를 지속적으로 확장하고 있다. 멀티모달 추세 하에서 AI 대형 모델의 주류 아키텍처인 Transformer의 상황이 흔들릴까요? MoE(Mixed of Experts) 아키텍처를 기반으로 한 대형 모델 탐색이 업계에서 새로운 트렌드가 된 이유는 무엇입니까? 대형 비전 모델(LVM)이 일반 비전 분야에서 새로운 돌파구가 될 수 있습니까? ...지난 6개월 동안 공개된 본 사이트의 2023 PRO 회원 뉴스레터에서 위 분야의 기술 동향과 산업 변화에 대한 심층 분석을 제공하여 새로운 환경에서 귀하의 목표 달성에 도움이 되는 10가지 특별 해석을 선택했습니다. 년. 준비하세요. 이 해석은 2023년 50주차에 나온 것입니다.
 최고의 분자를 자동으로 식별하고 합성 비용을 절감합니다. MIT는 분자 설계 의사결정 알고리즘 프레임워크를 개발합니다.
Jun 22, 2024 am 06:43 AM
최고의 분자를 자동으로 식별하고 합성 비용을 절감합니다. MIT는 분자 설계 의사결정 알고리즘 프레임워크를 개발합니다.
Jun 22, 2024 am 06:43 AM
편집자 | Ziluo AI의 신약 개발 간소화에 대한 활용이 폭발적으로 증가하고 있습니다. 신약 개발에 필요한 특성을 가질 수 있는 수십억 개의 후보 분자를 스크리닝합니다. 재료 가격부터 오류 위험까지 고려해야 할 변수가 너무 많아 과학자들이 AI를 사용하더라도 최고의 후보 분자를 합성하는 데 드는 비용을 평가하는 것은 쉬운 일이 아닙니다. 여기서 MIT 연구진은 최고의 분자 후보를 자동으로 식별하여 합성 비용을 최소화하는 동시에 후보가 원하는 특성을 가질 가능성을 최대화하기 위해 정량적 의사결정 알고리즘 프레임워크인 SPARROW를 개발했습니다. 알고리즘은 또한 이러한 분자를 합성하는 데 필요한 재료와 실험 단계를 결정했습니다. SPARROW는 여러 후보 분자를 사용할 수 있는 경우가 많기 때문에 한 번에 분자 배치를 합성하는 비용을 고려합니다.
