
 기술 주변기기
일체 포함
최초의 대형 모델 컨퍼런스인 COLM에서 높은 점수를 받은 논문: 선호도 검색 알고리즘인 pairS를 사용하면 대형 모델의 텍스트 평가를 더욱 효율적으로 수행할 수 있습니다.
기술 주변기기
일체 포함
최초의 대형 모델 컨퍼런스인 COLM에서 높은 점수를 받은 논문: 선호도 검색 알고리즘인 pairS를 사용하면 대형 모델의 텍스트 평가를 더욱 효율적으로 수행할 수 있습니다.
최초의 대형 모델 컨퍼런스인 COLM에서 높은 점수를 받은 논문: 선호도 검색 알고리즘인 pairS를 사용하면 대형 모델의 텍스트 평가를 더욱 효율적으로 수행할 수 있습니다.


La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Les auteurs de l'article sont tous du laboratoire de technologie linguistique de l'université de Cambridge. L'un d'eux est Liu Yinhong, un doctorant de troisième année, et ses superviseurs. sont les professeurs Nigel Collier et Ehsan Shareghi. Ses intérêts de recherche portent sur l'évaluation de grands modèles et de textes, la génération de données, etc. Zhou Han, doctorant en deuxième année à Tongyi, est encadré par les professeurs Anna Korhonen et Ivan Vulić. Ses recherches portent sur les grands modèles efficaces.
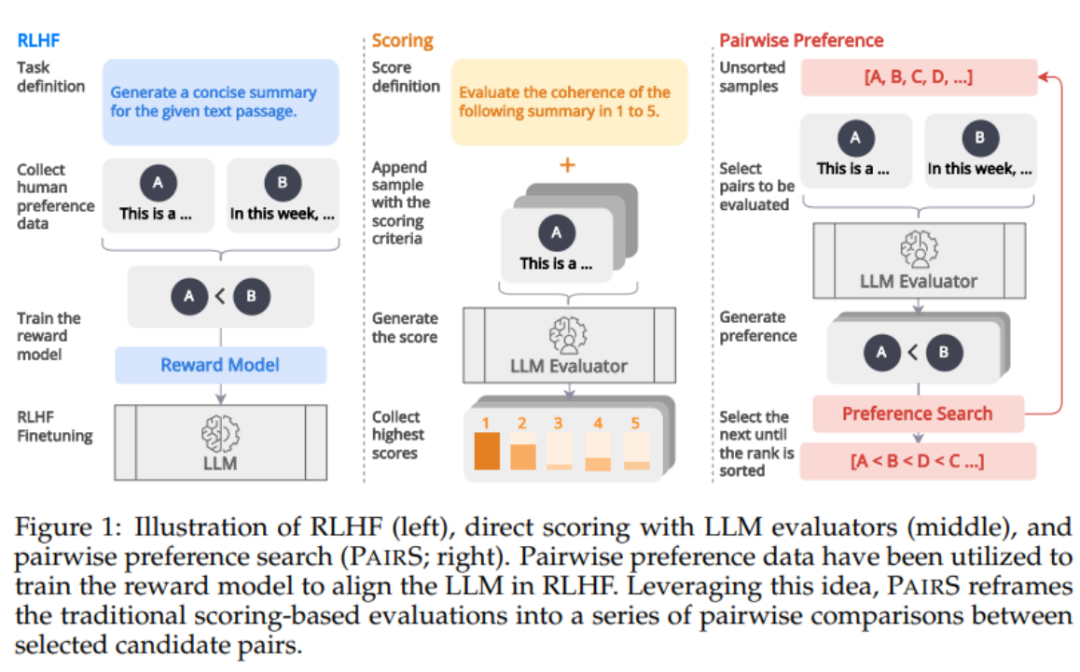
Le grand modèle présente d'excellentes capacités de suivi des commandes et de généralisation des tâches. Cette capacité unique provient de l'utilisation des données de suivi des commandes et de l'apprentissage par renforcement par rétroaction humaine (RLHF) dans la formation LLM. Dans le paradigme de formation RLHF, le modèle de récompense est aligné sur les préférences humaines sur la base des données de comparaison de classement. Cela améliore l'alignement des LLM sur les valeurs humaines, générant ainsi des réponses qui aident mieux les humains et adhèrent aux valeurs humaines.
Récemment, la première grande conférence de modèles COLM vient d'annoncer les résultats d'acceptation. L'un des travaux les plus performants a analysé le problème de biais de score difficile à éviter et à corriger lorsque le LLM est utilisé comme évaluateur de texte, et a proposé de convertir le problème. problème d'évaluation en un problème de classement des préférences, et a ainsi conçu l'algorithme PairS, un algorithme qui peut rechercher et trier à partir de préférences par paires. En tirant parti des hypothèses d'incertitude et de transitivité LLM, PairS peut donner des classements de préférences efficaces et précis et démontrer une plus grande cohérence avec le jugement humain sur plusieurs ensembles de tests.

Lien de l'article : https://arxiv.org/abs/2403.16950
Titre de l'article : Alignement avec le jugement humain : le rôle de la préférence par paire dans les évaluateurs de grands modèles linguistiques
Adresse Github : https://github.com/cambridgeltl/PairS
Quels sont les problèmes liés à l'évaluation de grands modèles ?
Un grand nombre de travaux récents ont démontré l'excellente performance des LLM dans l'évaluation de la qualité du texte, formant un nouveau paradigme pour l'évaluation sans référence des tâches génératives, évitant ainsi des coûts coûteux d'annotation humaine. Cependant, les évaluateurs LLM sont très sensibles à la conception des invites et peuvent même être affectés par de multiples biais, notamment le biais de position, le biais de verbosité et le biais contextuel. Ces préjugés empêchent les évaluateurs LLM d'être justes et dignes de confiance, entraînant des incohérences et des désalignements avec le jugement humain.
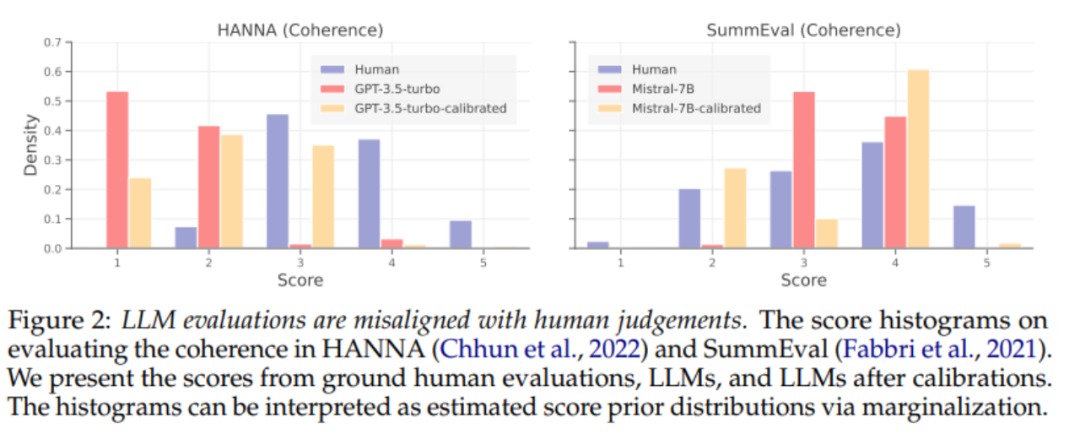
Pour réduire les prédictions biaisées des LLM, des travaux antérieurs ont développé des techniques d'étalonnage pour réduire les biais dans les prédictions des LLM. Nous effectuons d’abord une analyse systématique de l’efficacité des techniques de calage pour aligner les estimateurs LLM ponctuels. Comme le montre la figure 2 ci-dessus, les méthodes de calage existantes n'alignent toujours pas bien l'estimateur LLM, même lorsque des données de supervision sont fournies.
Comme le montre la Formule 1, nous pensons que la principale raison du désalignement de l'évaluation n'est pas les a priori biaisés sur la distribution des scores d'évaluation du LLM, mais le désalignement de la norme d'évaluation, c'est-à-dire la probabilité de l'évaluateur du LLM. Nous pensons que les évaluateurs LLM auront des critères d'évaluation plus cohérents avec ceux des humains lors de l'évaluation par paires. Nous explorons donc un nouveau paradigme d'évaluation LLM pour promouvoir des jugements plus alignés.

Inspiration apportée par RLHF
Comme le montre la figure 1 ci-dessous, inspiré par l'alignement des modèles de récompense via les données de préférence dans RLHF, nous pensons que l'évaluateur LLM peut être obtenu en générant un classement de préférences plus humain. -prédictions alignées. Certains travaux récents ont commencé à obtenir des classements de préférences en demandant à LLM d'effectuer des comparaisons par paires. Cependant, l’évaluation de la complexité et de l’évolutivité des classements de préférences a été largement négligée. Ils ignorent l'hypothèse de transitivité, rendant le nombre de comparaisons O (N^2), rendant le processus d'évaluation coûteux et irréalisable.
PairS: 효율적인 선호 검색 알고리즘
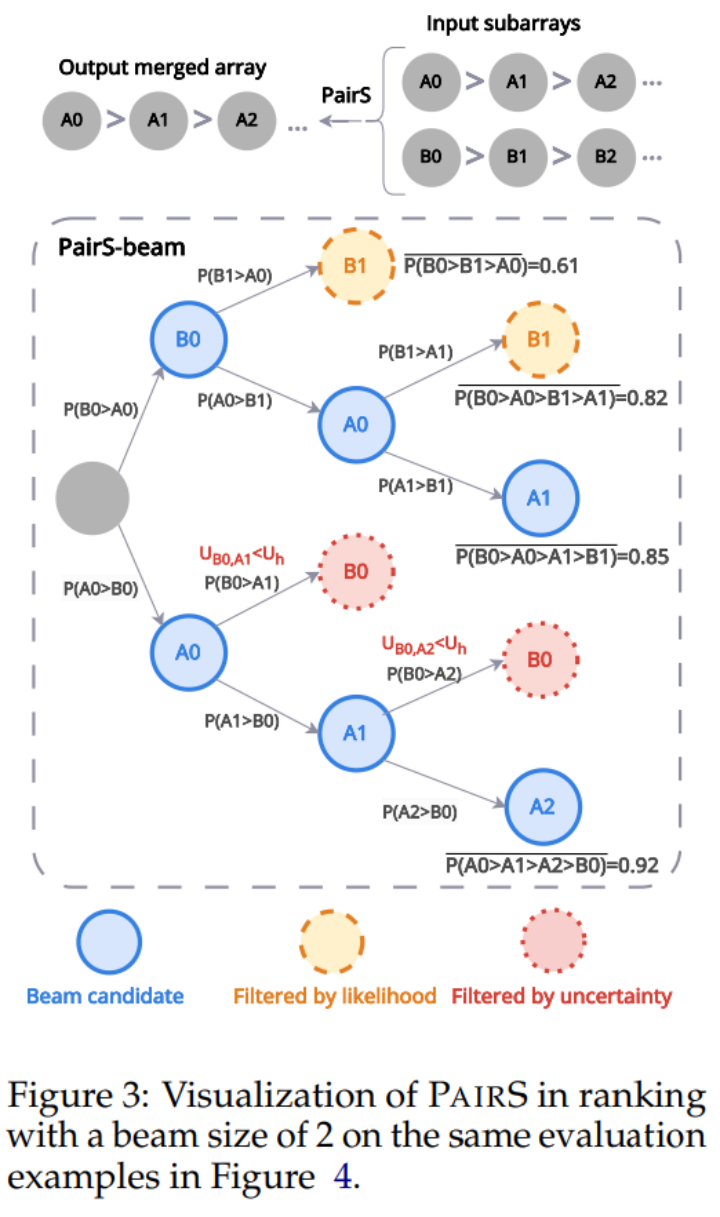
본 연구에서는 두 가지 쌍별 선호 검색 알고리즘(PairS-greedy 및 pairS-beam)을 제안합니다. pairS-greedy는 완전한 전이성 가정과 병합 정렬을 기반으로 하는 알고리즘으로 O(NlogN) 복잡도로 전역 우선 정렬을 얻을 수 있습니다. 전이성 가정은 예를 들어 3명의 후보자에 대해 LLM이 항상 A≻B 및 B≻C이면 A≻C라는 것을 의미합니다. 이 가정 하에서 우리는 쌍별 선호도로부터 선호도 순위를 얻기 위해 전통적인 순위 알고리즘을 직접 사용할 수 있습니다.
하지만 LLM은 완벽한 전이성을 가지지 못하기 때문에 pairS-beam 알고리즘을 설계했습니다. 보다 느슨한 전이성 가정 하에서 선호도 순위에 대한 우도 함수를 도출하고 단순화합니다. pairS-beam은 병합 정렬 알고리즘의 각 병합 연산에서 우도 값을 기반으로 빔 탐색을 수행하고, 선호도의 불확실성을 통해 쌍별 비교 공간을 줄이는 탐색 방법이다. pairS-beam은 대비 복잡도와 순위 품질을 조정하고 선호도 순위의 최대 우도 추정(MLE)을 효율적으로 제공할 수 있습니다. 아래 그림 3에서는 pairS-beam이 병합 작업을 수행하는 방법의 예를 보여줍니다.
실험 결과
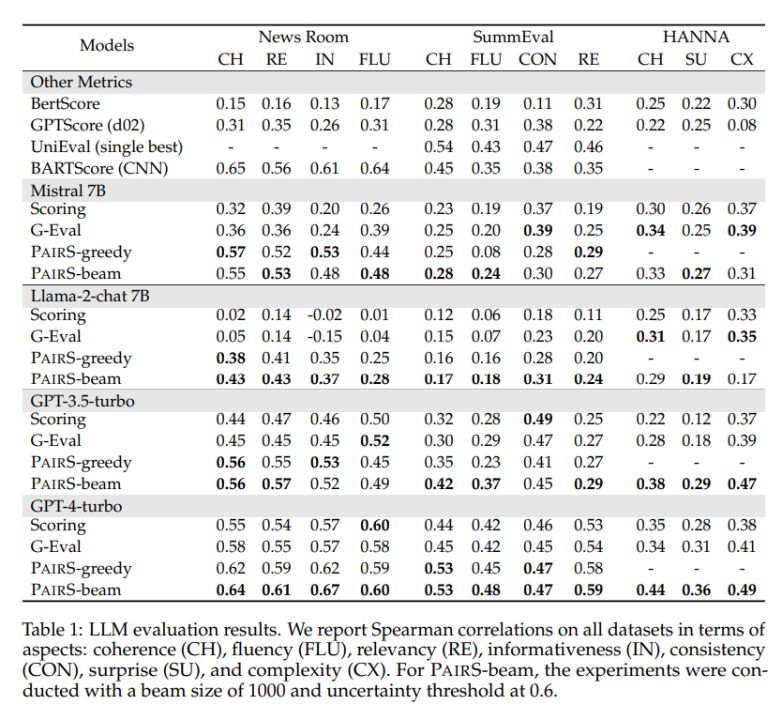
폐쇄형 약어 작업 NewsRoom 및 SummEval과 개방형 스토리 생성 작업 HANNA를 포함한 여러 대표 데이터 세트를 테스트하고 LLM 단일 지점에 대한 여러 기준 방법을 비교했습니다. 감독되지 않은 직접 채점, G-Eval, GPTScore 및 감독된 교육 UniEval 및 BARTScore를 포함한 평가. 아래 표 1에서 볼 수 있듯이 pairS는 모든 작업에서 사람 평가보다 사람 평가와의 일관성이 더 높습니다. GPT-4 터보는 SOTA 효과도 달성할 수 있습니다.
이 기사에서는 선호도 순위, 승률 및 ELO 등급에 대한 두 가지 기본 방법도 비교했습니다. pairS는 비교 횟수의 약 30%만으로 동일한 품질 선호도 순위를 달성할 수 있습니다. 또한 이 논문은 쌍별 선호도를 사용하여 LLM 추정기의 전이성을 정량적으로 계산하는 방법과 쌍별 추정기가 교정을 통해 어떤 이점을 얻을 수 있는지에 대한 더 많은 통찰력을 제공합니다.
자세한 연구 내용은 원문을 참고해주세요.
위 내용은 최초의 대형 모델 컨퍼런스인 COLM에서 높은 점수를 받은 논문: 선호도 검색 알고리즘인 pairS를 사용하면 대형 모델의 텍스트 평가를 더욱 효율적으로 수행할 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 ControlNet의 저자가 또 다른 히트를 쳤습니다! 이틀 만에 14,000개의 별을 획득하여 그림에서 그림을 생성하는 전체 과정
Jul 17, 2024 am 01:56 AM
ControlNet의 저자가 또 다른 히트를 쳤습니다! 이틀 만에 14,000개의 별을 획득하여 그림에서 그림을 생성하는 전체 과정
Jul 17, 2024 am 01:56 AM
역시 Tusheng 영상이지만 PaintsUndo는 다른 경로를 택했습니다. ControlNet 작성자 LvminZhang이 다시 살기 시작했습니다! 이번에는 회화 분야를 목표로 삼고 있습니다. 새로운 프로젝트인 PaintsUndo는 출시된 지 얼마 되지 않아 1.4kstar(여전히 상승세)를 받았습니다. 프로젝트 주소: https://github.com/lllyasviel/Paints-UNDO 이 프로젝트를 통해 사용자는 정적 이미지를 입력하고 PaintsUndo는 자동으로 라인 초안부터 완성품 따라가기까지 전체 페인팅 과정의 비디오를 생성하도록 도와줍니다. . 그리는 과정에서 선의 변화가 놀랍습니다. 최종 영상 결과는 원본 이미지와 매우 유사합니다. 완성된 그림을 살펴보겠습니다.
 오픈 소스 AI 소프트웨어 엔지니어 목록의 1위인 UIUC의 에이전트 없는 솔루션은 SWE 벤치의 실제 프로그래밍 문제를 쉽게 해결합니다.
Jul 17, 2024 pm 10:02 PM
오픈 소스 AI 소프트웨어 엔지니어 목록의 1위인 UIUC의 에이전트 없는 솔루션은 SWE 벤치의 실제 프로그래밍 문제를 쉽게 해결합니다.
Jul 17, 2024 pm 10:02 PM
AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com 이 논문의 저자는 모두 일리노이 대학교 Urbana-Champaign(UIUC)의 Zhang Lingming 교사 팀 출신입니다. Steven Code Repair, 박사 4년차, 연구원
 RLHF에서 DPO, TDPO까지 대규모 모델 정렬 알고리즘은 이미 '토큰 수준'입니다.
Jun 24, 2024 pm 03:04 PM
RLHF에서 DPO, TDPO까지 대규모 모델 정렬 알고리즘은 이미 '토큰 수준'입니다.
Jun 24, 2024 pm 03:04 PM
AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com 인공 지능 개발 과정에서 LLM(대형 언어 모델)의 제어 및 안내는 항상 핵심 과제 중 하나였으며 이러한 모델이 두 가지 모두를 보장하는 것을 목표로 했습니다. 강력하고 안전하게 인간 사회에 봉사합니다. 인간 피드백(RL)을 통한 강화 학습 방법에 초점을 맞춘 초기 노력
 OpenAI Super Alignment Team의 사후 작업: 두 개의 대형 모델이 게임을 하고 출력이 더 이해하기 쉬워졌습니다.
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment Team의 사후 작업: 두 개의 대형 모델이 게임을 하고 출력이 더 이해하기 쉬워졌습니다.
Jul 19, 2024 am 01:29 AM
AI 모델이 내놓은 답변이 전혀 이해하기 어렵다면 감히 사용해 보시겠습니까? 기계 학습 시스템이 더 중요한 영역에서 사용됨에 따라 우리가 그 결과를 신뢰할 수 있는 이유와 신뢰할 수 없는 경우를 보여주는 것이 점점 더 중요해지고 있습니다. 복잡한 시스템의 출력에 대한 신뢰를 얻는 한 가지 가능한 방법은 시스템이 인간이나 다른 신뢰할 수 있는 시스템이 읽을 수 있는 출력 해석을 생성하도록 요구하는 것입니다. 즉, 가능한 오류가 발생할 수 있는 지점까지 완전히 이해할 수 있습니다. 설립하다. 예를 들어, 사법 시스템에 대한 신뢰를 구축하기 위해 우리는 법원이 자신의 결정을 설명하고 뒷받침하는 명확하고 읽기 쉬운 서면 의견을 제공하도록 요구합니다. 대규모 언어 모델의 경우 유사한 접근 방식을 채택할 수도 있습니다. 그러나 이 접근 방식을 사용할 때는 언어 모델이 다음을 생성하는지 확인하세요.
 arXiv 논문은 '연발'로 게시될 수 있습니다. Stanford alphaXiv 토론 플랫폼은 온라인이며 LeCun은 이를 좋아합니다.
Aug 01, 2024 pm 05:18 PM
arXiv 논문은 '연발'로 게시될 수 있습니다. Stanford alphaXiv 토론 플랫폼은 온라인이며 LeCun은 이를 좋아합니다.
Aug 01, 2024 pm 05:18 PM
건배! 종이 토론이 말로만 진행된다면 어떤가요? 최근 스탠포드 대학교 학생들은 arXiv 논문에 대한 질문과 의견을 직접 게시할 수 있는 arXiv 논문에 대한 공개 토론 포럼인 alphaXiv를 만들었습니다. 웹사이트 링크: https://alphaxiv.org/ 실제로 이 웹사이트를 특별히 방문할 필요는 없습니다. URL에서 arXiv를 alphaXiv로 변경하면 alphaXiv 포럼에서 해당 논문을 바로 열 수 있습니다. 논문, 문장: 오른쪽 토론 영역에서 사용자는 저자에게 논문의 아이디어와 세부 사항에 대해 질문하는 질문을 게시할 수 있습니다. 예를 들어 다음과 같이 논문 내용에 대해 의견을 제시할 수도 있습니다.
 리만 가설의 중요한 돌파구! 타오저쉬안(Tao Zhexuan)은 MIT와 옥스퍼드의 새로운 논문을 적극 추천했으며, 37세의 필즈상 수상자도 참여했다.
Aug 05, 2024 pm 03:32 PM
리만 가설의 중요한 돌파구! 타오저쉬안(Tao Zhexuan)은 MIT와 옥스퍼드의 새로운 논문을 적극 추천했으며, 37세의 필즈상 수상자도 참여했다.
Aug 05, 2024 pm 03:32 PM
최근 새천년 7대 과제 중 하나로 알려진 리만 가설이 새로운 돌파구를 마련했다. 리만 가설은 소수 분포의 정확한 특성과 관련된 수학에서 매우 중요한 미해결 문제입니다(소수는 1과 자기 자신으로만 나눌 수 있는 숫자이며 정수 이론에서 근본적인 역할을 합니다). 오늘날의 수학 문헌에는 리만 가설(또는 일반화된 형식)의 확립에 기초한 수학적 명제가 천 개가 넘습니다. 즉, 리만 가설과 그 일반화된 형식이 입증되면 천 개가 넘는 명제가 정리로 확립되어 수학 분야에 지대한 영향을 미칠 것이며, 리만 가설이 틀린 것으로 입증된다면, 이러한 제안의 일부도 그 효과를 잃을 것입니다. MIT 수학 교수 Larry Guth와 Oxford University의 새로운 돌파구
 최초의 Mamba 기반 MLLM이 출시되었습니다! 모델 가중치, 학습 코드 등은 모두 오픈 소스입니다.
Jul 17, 2024 am 02:46 AM
최초의 Mamba 기반 MLLM이 출시되었습니다! 모델 가중치, 학습 코드 등은 모두 오픈 소스입니다.
Jul 17, 2024 am 02:46 AM
AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com 서문 최근 몇 년 동안 다양한 분야에서 MLLM(Multimodal Large Language Model)의 적용이 눈에 띄는 성공을 거두었습니다. 그러나 많은 다운스트림 작업의 기본 모델로서 현재 MLLM은 잘 알려진 Transformer 네트워크로 구성됩니다.
 LLM은 시계열 예측에 적합하지 않습니다. 추론 능력도 사용하지 않습니다.
Jul 15, 2024 pm 03:59 PM
LLM은 시계열 예측에 적합하지 않습니다. 추론 능력도 사용하지 않습니다.
Jul 15, 2024 pm 03:59 PM
시계열 예측에 언어 모델을 실제로 사용할 수 있나요? Betteridge의 헤드라인 법칙(물음표로 끝나는 모든 뉴스 헤드라인은 "아니오"로 대답할 수 있음)에 따르면 대답은 아니오여야 합니다. 사실은 사실인 것 같습니다. 이렇게 강력한 LLM은 시계열 데이터를 잘 처리할 수 없습니다. 시계열, 즉 시계열은 이름에서 알 수 있듯이 시간 순서대로 배열된 데이터 포인트 시퀀스 집합을 나타냅니다. 시계열 분석은 질병 확산 예측, 소매 분석, 의료, 금융 등 다양한 분야에서 중요합니다. 시계열 분석 분야에서는 최근 많은 연구자들이 LLM(Large Language Model)을 사용하여 시계열의 이상 현상을 분류, 예측 및 탐지하는 방법을 연구하고 있습니다. 이 논문에서는 텍스트의 순차적 종속성을 잘 처리하는 언어 모델이 시계열로도 일반화될 수 있다고 가정합니다.
