Kaedah pendidikan manusia juga sesuai untuk model besar.
Apabila membesarkan anak, orang sepanjang zaman telah bercakap tentang kaedah penting: memimpin melalui teladan. Maksudnya, jadikan diri anda sebagai contoh untuk ditiru dan dipelajari oleh kanak-kanak, bukannya hanya memberitahu mereka apa yang perlu dilakukan. Apabila melatih model bahasa besar (LLM), kami juga mungkin boleh menggunakan kaedah ini - menunjukkan kepada model.
Baru-baru ini, pasukan Yang Diyi di Universiti Stanford mencadangkan rangka kerja baharu DITTO yang boleh menyelaraskan LLM dengan tetapan tertentu melalui sebilangan kecil demonstrasi (contoh tingkah laku yang diingini disediakan oleh pengguna). Contoh-contoh ini boleh diperoleh daripada log interaksi sedia ada pengguna, atau dengan mengedit terus output LLM. Ini membolehkan model memahami dan menyelaraskan pilihan pengguna dengan cekap untuk pengguna dan tugasan yang berbeza. 
- Tajuk kertas: Tunjukkan, Jangan Beritahu: Menjajarkan Model Bahasa dengan Maklum Balas yang Ditunjukkan
- Alamat kertas: https://arxiv.org/pdf/2406.00888
jadilah berdasarkan Sebilangan kecil tunjuk cara (kurang daripada 10) secara automatik mencipta set data yang mengandungi sejumlah besar perbandingan keutamaan (proses yang dipanggil perancah) dengan secara senyap-senyap menyedari bahawa pengguna lebih suka LLM berbanding output LLM asal dan lelaran terdahulu . Kemudian, demonstrasi dan output model digabungkan menjadi pasangan data untuk mendapatkan set data yang dipertingkatkan. Model bahasa kemudiannya boleh dikemas kini menggunakan algoritma penjajaran seperti DPO.
Selain itu, pasukan juga mendapati bahawa DITTO boleh dilihat sebagai algoritma pembelajaran tiruan dalam talian, di mana data yang disampel daripada LLM digunakan untuk membezakan tingkah laku pakar. Daripada perspektif ini, pasukan menunjukkan bahawa DITTO boleh mencapai prestasi pakar-unggul melalui ekstrapolasi.
Pasukan juga mengesahkan kesan DITTO melalui eksperimen. Untuk menyelaraskan LLM, kaedah sebelumnya selalunya memerlukan penggunaan beribu-ribu pasangan data perbandingan, manakala DITTO boleh mengubah suai tingkah laku model dengan hanya beberapa demonstrasi. Penyesuaian pantas dan kos rendah ini dimungkinkan terutamanya oleh cerapan teras pasukan: Data perbandingan dalam talian mudah didapati melalui demonstrasi.
Simbol dan latar belakang
Model bahasa boleh dilihat sebagai dasar π(y|x), yang menghasilkan pengedaran x segera dan hasil penyelesaian y. Matlamat RLHF adalah untuk melatih LLM untuk memaksimumkan fungsi ganjaran r (x, y) yang menilai kualiti pasangan hasil penyelesaian segera (x, y). Biasanya, perbezaan KL juga ditambah untuk mengelakkan model yang dikemas kini daripada menyimpang terlalu jauh daripada model bahasa asas (π_ref). Secara keseluruhan, matlamat pengoptimuman kaedah RLHF ialah: Il s'agit de maximiser la récompense attendue sur la distribution rapide p, qui est affectée par la contrainte KL régulée par α. En règle générale, l'objectif d'optimisation utilise un ensemble de données de comparaison de la forme {(x, y^w, y^l )}, où le résultat d'achèvement "gagnant" y^w est meilleur que le résultat d'achèvement "perdant" y ^l, enregistré sous la forme y^w ⪰ y^l. De plus, nous marquons ici le petit ensemble de données de démonstration d'experts comme D_E et supposons que ces démonstrations sont générées par la politique experte π_E, qui peut maximiser la récompense de prédiction. DITTO peut utiliser directement les résultats du modèle de langage et les démonstrations d'experts pour générer des données de comparaison. Autrement dit, contrairement aux paradigmes génératifs pour les données synthétiques, DITTO ne nécessite pas un modèle déjà performant pour une tâche donnée. L'idée clé de DITTO est que le modèle de langage lui-même, associé à des démonstrations d'experts, peut conduire à un ensemble de données comparatives pour l'alignement, ce qui élimine le besoin de collecter de grandes quantités de données de préférences par paires. . Il en résulte une cible de type contrastée où les démonstrations d'experts sont des exemples positifs. Générer une comparaison. Supposons que nous échantillonnions un résultat d'achèvement y^E ∼ π_E (・|x) de la politique experte. On peut alors considérer que les récompenses correspondant aux échantillons échantillonnés dans d’autres politiques π sont inférieures ou égales aux récompenses des échantillons échantillonnés dans π_E. Sur la base de cette observation, l'équipe a construit des données comparatives (x, y^E, y^π ), où y^E ⪰ y^π. Bien que ces données comparatives proviennent de stratégies plutôt que d’échantillons individuels, des recherches antérieures ont démontré l’efficacité de cette approche. Une approche naturelle pour DITTO consiste à utiliser cet ensemble de données et un algorithme RLHF facilement disponible pour optimiser (1). Cela améliore la probabilité des réponses d'experts tout en réduisant la probabilité de l'échantillon du modèle actuel, contrairement aux méthodes de réglage fin standard qui ne font que la première. L’essentiel est qu’en utilisant des échantillons de π, un ensemble de données de préférences illimitées peut être construit avec un petit nombre de démonstrations. Cependant, l’équipe a constaté que cela pourrait être encore mieux fait en prenant en compte les aspects temporels du processus d’apprentissage. De la comparaison au classement. Utiliser uniquement des données comparatives provenant d’experts et une seule politique π peut ne pas suffire pour obtenir de bonnes performances. Cela ne fera que réduire la probabilité d'un π particulier, conduisant au problème de surapprentissage - qui tourmente également SFT avec peu de données. L'équipe propose qu'il soit également possible de considérer les données générées par toutes les politiques apprises au fil du temps au cours du RLHF, de manière similaire à la relecture dans l'apprentissage par renforcement. Soit la stratégie initiale du premier tour d'itération soit π_0. Un ensemble de données D_0 est obtenu en échantillonnant cette stratégie. Un ensemble de données de comparaison pour RLHF peut ensuite être généré sur cette base, qui peut être noté D_E ⪰ D_0. En utilisant ces données de comparaison dérivées, π_0 peut être mis à jour pour obtenir π_1. Par définition, est également valable. Après cela, continuez à utiliser π_1 pour générer des données de comparaison, et D_E ⪰ D_1. Poursuivez ce processus, en générant continuellement des données de comparaison de plus en plus diversifiées en utilisant toutes les stratégies précédentes. L’équipe appelle ces comparaisons « comparaisons de rediffusion ». Bien que cette méthode ait du sens en théorie, un surapprentissage peut se produire si D_E est petit. Cependant, des comparaisons entre politiques peuvent également être envisagées lors de la formation si l’on suppose que la politique s’améliorera après chaque itération. Contrairement à la comparaison avec les experts, nous ne pouvons pas garantir que la stratégie sera meilleure après chaque itération, mais l'équipe a constaté que le modèle global s'améliore encore après chaque itération. Cela peut être dû à la fois à la modélisation des récompenses et à (1) sa convexité. De cette manière, les données de comparaison peuvent être échantillonnées selon le classement suivant :
En ajoutant ces données de comparaison "inter-modèle" et "replay", l'effet obtenu est que la probabilité d'échantillons précoces (tels que le les échantillons dans D_1) seront plus élevés que les plus récents (comme dans D_t), appuyez plus bas, lissant ainsi l'image de récompense implicite. Dans la mise en œuvre pratique, l'approche de l'équipe consiste non seulement à utiliser des données de comparaison avec des experts, mais également à regrouper certaines données de comparaison entre ces modèles. Un algorithme pratique. En pratique, l'algorithme DITTO est un processus itératif composé de trois composants simples, comme le montre l'algorithme 1.
먼저 전문가 데모 세트에서 감독된 미세 조정을 실행하여 제한된 수의 그라디언트 단계를 수행합니다. 이를 초기 정책 π_0으로 둡니다. 두 번째 단계, 샘플 비교 데이터: 훈련 중에 D_E의 N 데모 각각에 대해 π_t에서 M개의 완료 결과를 샘플링하여 새로운 데이터 세트 D_t가 구성되고, 그런 다음 순위에 추가됩니다. 전략(2). 방정식 (2)에서 비교 데이터를 샘플링할 때 각 배치 B는 70% "온라인" 비교 데이터 D_E ⪰ D_t와 20% "재생" 비교 데이터 D_E ⪰ D_{i
로 구성됩니다. 여기서 σ는 다음의 로지스틱 함수입니다. 브래들리-테리 선호 모델. 각 업데이트 중에 SFT 전략의 참조 모델은 초기화에서 너무 멀리 벗어나는 것을 방지하기 위해 업데이트되지 않습니다. DITTO는 전문가의 시연과 온라인 데이터를 결합하여 보상 기능과 정책을 동시에 학습하는 온라인 모방 학습 관점에서 파생될 수 있습니다. 구체적으로, 전략 플레이어는 예상 보상?(π, r)을 최대화하는 반면, 보상 플레이어는 온라인 데이터 세트 D^π에 대한 손실 min_r L(D^π, r)을 최소화합니다. (1)의 정책 목표와 표준 보상 모델링 손실을 사용하여 최적화 문제를 인스턴스화합니다.
DITTO 파생, (3) 단순화의 첫 번째 단계는 내부 정책 최대 문제를 해결하는 것입니다. 다행스럽게도 팀은 이전 연구를 기반으로 정책 목표 ?_KL이 Z(x)가 정규화된 분포의 분할 함수인 형식의 폐쇄형 솔루션을 가지고 있음을 발견했습니다. 특히 이는 내부 최적화를 제거하는 데 사용할 수 있는 정책과 보상 기능 사이에 전단적 관계를 생성합니다. 이 솔루션을 재정렬하면 보상 함수는 다음과 같이 작성될 수 있습니다. 또한 이전 연구에서는 이러한 재매개변수화가 임의의 보상 함수를 나타낼 수 있음을 보여주었습니다. 따라서 방정식 (3)에 대입하면 변수 r이 π로 변경되어 DITTO 목적을 얻을 수 있습니다. 여기에서는 DPO와 유사하게 보상 함수가 암시적으로 추정된다는 점에 유의하세요. DPO와의 차이점은 DITTO가 온라인 선호도 데이터 세트 D^π에 의존한다는 것입니다. SFT를 사용하는 것보다 DITTO가 더 좋은 이유는 무엇인가요? DITTO가 더 나은 성능을 보이는 이유 중 하나는 비교 데이터를 생성하여 SFT보다 훨씬 많은 데이터를 사용한다는 것입니다. 또 다른 이유는 어떤 경우에는 온라인 모방 학습 방법이 발표자보다 성능이 뛰어난 반면 SFT는 시연만 모방할 수 있다는 것입니다. 팀은 DITTO의 효과를 입증하기 위한 실증적 연구도 진행했습니다. 실험의 특정 설정에 대해서는 원본 논문을 참조하십시오. 여기서는 실험 결과에만 중점을 둡니다. GPT-4를 이용한 정적 벤치마크 평가 결과는 표 1과 같습니다.
평균적으로 DITTO는 다른 모든 방법보다 뛰어납니다. CMCC의 평균 승률은 71.67%, CCAT50의 평균 승률은 77.09%입니다. CCAT50에서는 모든 저자에 대해 DITTO가 그 중 단 한 곳에서만 전반적인 승리를 거두지 못했습니다. CMCC에서 모든 작성자에 대해 DITTO는 전반적으로 벤치마크의 절반을 능가했으며 몇 번의 샷으로 30% 승리했습니다. SFT는 좋은 성적을 거두었지만 DITTO는 이에 비해 평균 승률을 11.7% 향상시켰습니다. 사용자 연구: 자연 작업으로 일반화하는 능력 테스트전반적으로 사용자 연구 결과는 정적 벤치마크 결과와 일치합니다. DITTO는 표 2에 표시된 것처럼 정렬된 데모에 대한 선호도 측면에서 대조 방법보다 성능이 뛰어납니다. 여기서 DITTO(72.1% 승률) > SFT(60.1%) > 소수 샷(48.1%) > 자체 프롬프트(44.2%) > 제로샷(25.0%).
DITTO를 사용하기 전에 사용자는 가지고 있는 데모 수부터 언어 모델에서 샘플링해야 하는 부정적인 예 수까지 몇 가지 전제 조건을 고려해야 합니다. 팀은 이러한 결정의 영향을 조사하고 CCAT보다 더 많은 임무를 다루기 때문에 CMCC에 중점을 두었습니다. 또한 데모와 쌍을 이루는 피드백의 샘플 효율성을 분석했습니다. 팀은 DITTO의 구성 요소에 대한 절제 연구를 수행했습니다. 그림 2(왼쪽)에 표시된 것처럼 DITTO의 반복 횟수를 늘리면 일반적으로 성능이 향상될 수 있습니다.
반복 횟수가 1에서 4로 증가하면 GPT-4에서 평가한 승률이 31.5% 증가하는 것을 볼 수 있습니다. 이러한 개선은 단조롭지 않습니다. 반복 2에서는 성능이 약간(-3.4%) 감소합니다. 이는 초기 반복이 노이즈가 많은 샘플로 끝나고 결과적으로 성능이 저하될 수 있기 때문입니다. 반면, 그림 2(가운데)에서 볼 수 있듯이 부정적인 예제의 수를 늘리면 DITTO 성능이 단조롭게 향상됩니다. 또한 더 많은 부정적인 예가 샘플링될수록 DITTO 성능의 분산이 감소합니다.
Außerdem ergaben Ablationsstudien zu DITTO, wie in Tabelle 3 gezeigt, dass die Entfernung einer seiner Komponenten zu einer Leistungsverschlechterung führte. Wenn Sie beispielsweise auf die iterative Online-Stichprobe verzichten, sinkt die Gewinnquote im Vergleich zur Verwendung von DITTO von 70,1 % auf 57,3 %. Und wenn π_ref während des Online-Prozesses kontinuierlich aktualisiert wird, führt dies zu einem erheblichen Leistungsabfall: von 70,1 % auf 45,8 %. Das Team vermutet, dass der Grund darin liegt, dass die Aktualisierung von π_ref zu einer Überanpassung führen könnte. Schließlich können wir in Tabelle 3 auch die Bedeutung von Wiederholungs- und Inter-Strategie-Vergleichsdaten erkennen. Einer der Hauptvorteile von DITTO ist seine Probeneffizienz. Das Team hat dies ausgewertet und die Ergebnisse sind in Abbildung 2 (rechts) dargestellt. Hier werden wiederum normalisierte Gewinnraten angegeben. Zunächst können Sie sehen, dass die Gewinnquote von DITTO zu Beginn schnell ansteigt. Wenn die Anzahl der Demos von 1 auf 3 steigt, verbessert sich die normalisierte Leistung mit jeder Erhöhung erheblich (0 % → 5 % → 11,9 %). Wenn jedoch die Anzahl der Demos weiter zunimmt, nimmt die Umsatzsteigerung ab (11,9 % → 15,39 % bei einer Erhöhung von 4 auf 7), was zeigt, dass mit zunehmender Anzahl der Demos die Leistung von DITTO gesättigt sein wird. Darüber hinaus spekuliert das Team, dass sich nicht nur die Anzahl der Demonstrationen auf die Leistung von DITTO, sondern auch auf die Qualität der Demonstrationen auswirken wird, dies bleibt jedoch zukünftiger Forschung überlassen. Wie ist die paarweise Präferenz im Vergleich zur Demo? Eine Kernannahme von DITTO ist, dass die Probeneffizienz durch Demonstration entsteht. Theoretisch kann ein ähnlicher Effekt erzielt werden, indem viele Paare von Präferenzdaten mit Anmerkungen versehen werden, wenn der Benutzer eine perfekte Reihe von Demonstrationen im Sinn hat. Das Team führte ein detailliertes Experiment durch, bei dem es sich um Stichproben von Compliance Mistral 7B handelte, und ließ 500 Präferenzdatenpaare auch von einem der Autoren kommentieren, der eine Demo der Benutzerstudie bereitstellte. Zusammenfassend haben sie einen paarweisen Präferenzdatensatz D_pref = {(x, y^i , y^j )} erstellt, wobei y^i ≻ y^j ist. Anschließend berechneten sie die Gewinnquote für 20 Ergebnispaare, die aus zwei Modellen entnommen wurden – eines wurde auf 4 Demos mit DITTO trainiert, das andere auf {0...500} Präferenzdatenpaaren, die nur DPO nutzten.
Wenn paarweise Präferenzdaten nur aus π_ref abgetastet werden, kann beobachtet werden, dass die generierten Datenpaare außerhalb der gezeigten Verteilung liegen – die paarweisen Präferenzen beinhalten nicht das vom Benutzer gezeigte Verhalten (Ergebnisse für die Basisrichtlinie in Abbildung 3, blaue Farbe). Selbst als sie π_ref mithilfe von Benutzerdemonstrationen verfeinerten, waren immer noch mehr als 500 Präferenzdatenpaare erforderlich, um die Leistung von DITTO zu erreichen (Ergebnisse für die durch Demo verfeinerte Richtlinie in Abbildung 3, orange). 위 내용은 Yang Diyi 팀이 제안한 DITTO는 매우 효율적입니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!





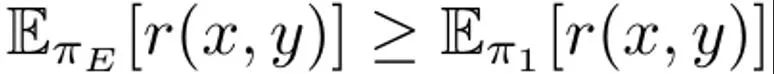 est également valable. Après cela, continuez à utiliser π_1 pour générer des données de comparaison, et D_E ⪰ D_1. Poursuivez ce processus, en générant continuellement des données de comparaison de plus en plus diversifiées en utilisant toutes les stratégies précédentes. L’équipe appelle ces comparaisons « comparaisons de rediffusion ».
est également valable. Après cela, continuez à utiliser π_1 pour générer des données de comparaison, et D_E ⪰ D_1. Poursuivez ce processus, en générant continuellement des données de comparaison de plus en plus diversifiées en utilisant toutes les stratégies précédentes. L’équipe appelle ces comparaisons « comparaisons de rediffusion ». 



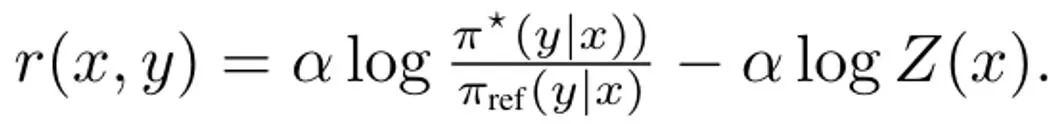
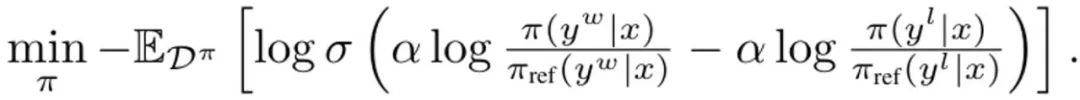




















 딥마인드 로봇이 탁구를 치는데 포핸드와 백핸드가 공중으로 미끄러져 인간 초보자를 완전히 제압했다.
Aug 09, 2024 pm 04:01 PM
딥마인드 로봇이 탁구를 치는데 포핸드와 백핸드가 공중으로 미끄러져 인간 초보자를 완전히 제압했다.
Aug 09, 2024 pm 04:01 PM
 최초의 기계식 발톱! Yuanluobao는 2024년 세계 로봇 회의에 등장하여 집에 들어갈 수 있는 최초의 체스 로봇을 출시했습니다.
Aug 21, 2024 pm 07:33 PM
최초의 기계식 발톱! Yuanluobao는 2024년 세계 로봇 회의에 등장하여 집에 들어갈 수 있는 최초의 체스 로봇을 출시했습니다.
Aug 21, 2024 pm 07:33 PM
 클로드도 게으르게 됐어요! 네티즌 : 휴가를 보내는 법을 배우십시오
Sep 02, 2024 pm 01:56 PM
클로드도 게으르게 됐어요! 네티즌 : 휴가를 보내는 법을 배우십시오
Sep 02, 2024 pm 01:56 PM
 세계로봇컨퍼런스에서 '미래 노인돌봄의 희망'을 담은 국산 로봇이 포위됐다.
Aug 22, 2024 pm 10:35 PM
세계로봇컨퍼런스에서 '미래 노인돌봄의 희망'을 담은 국산 로봇이 포위됐다.
Aug 22, 2024 pm 10:35 PM
 ACL 2024 시상식 발표: HuaTech의 Oracle 해독에 관한 최고의 논문 중 하나, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 시상식 발표: HuaTech의 Oracle 해독에 관한 최고의 논문 중 하나, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
 Li Feifei 팀은 로봇에 공간 지능을 제공하고 GPT-4o를 통합하기 위해 ReKep을 제안했습니다.
Sep 03, 2024 pm 05:18 PM
Li Feifei 팀은 로봇에 공간 지능을 제공하고 GPT-4o를 통합하기 위해 ReKep을 제안했습니다.
Sep 03, 2024 pm 05:18 PM
 분산 인공지능 컨퍼런스 DAI 2024 Call for Papers: Agent Day, 강화학습의 아버지 Richard Sutton이 참석합니다! Yan Shuicheng, Sergey Levine 및 DeepMind 과학자들이 기조 연설을 할 예정입니다.
Aug 22, 2024 pm 08:02 PM
분산 인공지능 컨퍼런스 DAI 2024 Call for Papers: Agent Day, 강화학습의 아버지 Richard Sutton이 참석합니다! Yan Shuicheng, Sergey Levine 및 DeepMind 과학자들이 기조 연설을 할 예정입니다.
Aug 22, 2024 pm 08:02 PM
 홍멍 스마트 트래블 S9과 풀시나리오 신제품 출시 컨퍼런스, 다수의 블록버스터 신제품이 함께 출시됐다
Aug 08, 2024 am 07:02 AM
홍멍 스마트 트래블 S9과 풀시나리오 신제품 출시 컨퍼런스, 다수의 블록버스터 신제품이 함께 출시됐다
Aug 08, 2024 am 07:02 AM
