

PRO | MoE 기반의 대형 모델이 더 주목받는 이유는 무엇인가요?

2023년에는 AI의 거의 모든 분야가 전례 없는 속도로 진화하고 있습니다. 동시에 AI는 구현 지능, 자율 주행 등 핵심 트랙의 기술적 한계를 지속적으로 확장하고 있습니다. 멀티모달 추세 하에서 Transformer는 대형 AI 모델의 주류 아키텍처로 흔들릴까요? MoE(Mixture of Experts) 아키텍처를 기반으로 한 대형 모델 탐색이 업계에서 새로운 트렌드가 된 이유는 무엇입니까? LVM(Large Vision Model)이 일반 시력 분야에서 새로운 돌파구가 될 수 있을까요? ...지난 6개월 동안 공개된 본 사이트의 2023 PRO 회원 뉴스레터에서 위 분야의 기술 동향과 산업 변화에 대한 심층 분석을 제공하는 10가지 특별 해석을 선택하여 새로운 환경에서 귀하의 목표를 달성하는 데 도움을 드립니다. 년. 준비하세요. 이 해석은 2023 Week50 업계 뉴스레터 ?

날짜: 12월 12일
이벤트: Mistral AI는 MoE(Mixture-of-Experts, Expert Mixture) 아키텍처를 기반으로 하는 Mixtral 8x7B 모델을 오픈소스화했으며 성능은 Llama 2 70B 및 GPT-3.5" 이벤트 수준에 도달했습니다.
먼저 MoE가 무엇인지, 그 내용을 알아보겠습니다
1. 개념:
MoE(Mixture of Experts)는 여러 하위 모델(예: 전문가)로 구성된 하이브리드 모델입니다. , 각 하위 모델 입력 공간의 하위 집합을 전문적으로 처리하는 로컬 모델입니다. MoE의 핵심 아이디어는 게이팅 네트워크를 사용하여 각 데이터별로 어떤 모델을 학습해야 하는지 결정하여 간의 간섭을 완화하는 것입니다.
2. 주요 구성 요소:
혼합 전문가 모델 기술(MoE)은 전문가 모델과 게이트 모델로 구성된 스파스 게이트로 제어되는 딥 러닝 기술입니다. 각 모델은 자신이 가장 잘하는 작업에 집중하여 모델의 희소성을 달성합니다.
① Gated 네트워크의 교육에서는 각 샘플이 한 명 이상의 전문가에게 할당됩니다. ;
② 전문가 네트워크의 교육에서는 각 전문가가 할당된 샘플의 오류를 최소화하도록 교육됩니다.
3 MoE의 "전임자"는 Ensemble Learning입니다. . 앙상블 학습은 동일한 문제를 해결하기 위해 여러 모델(기본 학습자)을 훈련하고 단순히 예측(예: 투표 또는 평균화)을 결합하는 프로세스입니다. 앙상블 학습의 주요 목표는 과적합을 줄이고 일반화 능력을 향상시켜 예측 성능을 향상시키는 것입니다. 일반적인 앙상블 학습 방법에는 Bagged, Boosting 및 Stacking이 있습니다.
4. MoE 역사적 출처:
① MoE의 뿌리는 1991년 논문 "Adaptive Mixture of Local Experts"로 거슬러 올라갑니다. 이 아이디어는 입력 공간의 서로 다른 영역을 전문으로 하는 각 개별 네트워크 또는 전문가와 함께 서로 다른 하위 네트워크로 구성된 시스템에 대한 감독 프로세스를 제공하는 것을 목표로 한다는 점에서 앙상블 접근 방식과 유사합니다. 각 전문가의 가중치는 게이트 네트워크를 통해 결정됩니다. 교육 과정에서 전문가와 게이트키퍼 모두 교육을 받습니다.
② 2010년부터 2015년 사이에 두 가지 다른 연구 영역이 MoE의 추가 개발에 기여했습니다.
하나는 구성 요소로서의 전문가입니다. 전통적인 MoE 설정에서 전체 시스템은 게이트 네트워크와 여러 전문가로 구성됩니다. 전체 모델로서의 MoE는 지원 벡터 머신, 가우스 프로세스 및 기타 방법에서 탐색되었습니다. "전문가의 심층 혼합에서 학습 요소 표현"이라는 작업은 더 깊은 네트워크의 구성 요소로서 MoE의 가능성을 탐구합니다. 이를 통해 모델은 동시에 크고 효율적이 될 수 있습니다.
다른 하나는 조건부 계산입니다. 기존 네트워크는 각 레이어를 통해 모든 입력 데이터를 처리합니다. 이 기간 동안 Yoshua Bengio는 입력 토큰을 기반으로 구성 요소를 동적으로 활성화하거나 비활성화하는 방법을 조사했습니다.
3 결과적으로 사람들은 자연어 처리의 맥락에서 전문적인 혼합 모델을 탐색하기 시작했습니다. "Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer"라는 논문에서는 희소성을 도입하여 137B LSTM으로 확장하여 대규모에서 빠른 추론을 달성했습니다.
국토부 기반 대형 모델이 주목받는 이유는 무엇인가요?1. 일반적으로 모델 규모의 확장은 학습 비용의 상당한 증가로 이어질 것이며, 컴퓨팅 리소스의 한계는 대규모 집중 모델 학습에 병목 현상이 되었습니다. 이 문제를 해결하기 위해 희소 MoE 레이어 기반의 딥러닝 모델 아키텍처가 제안됩니다.
2. MoE(Sparse Mixed Expert Model)는 추론 비용을 늘리지 않고 LLM(대형 언어 모델)에 학습 가능한 매개변수를 추가할 수 있는 특수 신경망 아키텍처이며, 명령 조정(Instruction Tuning)은 LLM이 지침을 따르도록 훈련시키는 기술입니다. .
3. MoE+ 교육 미세 조정 기술의 결합은 언어 모델의 성능을 크게 향상시킬 수 있습니다. 2023년 7월, Google, UC Berkeley, MIT 및 기타 기관의 연구자들은 "Mixture-of-Experts Meets Instruction Tuning: A Winning Combination for Large Language Models"라는 논문을 발표하여 하이브리드 전문가 모델(MoE)과 명령어 튜닝이 입증되었습니다. 이러한 조합을 통해 LLM(대형 언어 모델)의 성능이 크게 향상될 수 있습니다.
① 구체적으로 연구원들은 명령이 미세 조정된 희소 하이브리드 전문가 모델 FLAN-MOE 세트에서 희소 활성화 MoE를 사용하고, 더 나은 모델 용량과 컴퓨팅 성능을 제공하기 위해 Transformer 계층의 피드포워드 구성 요소를 MoE 계층으로 대체했습니다. 둘째, FLAN 집단 데이터 세트를 기반으로 FLAN-MOE를 미세 조정합니다.
② 위의 방법을 바탕으로 연구원들은 명령어 튜닝 없이 단일 다운스트림 작업에 대한 직접 미세 조정, 명령어 튜닝 후 다운스트림 작업에 대한 In-Context Few-Shot 또는 Zero-Shot 일반화를 연구했으며, 명령어 튜닝에서는 단일 다운스트림 작업을 추가로 미세 조정하고 세 가지 실험 설정에서 LLM의 성능 차이를 비교합니다.
3 실험 결과에 따르면 명령 조정을 사용하지 않으면 MoE 모델이 유사한 계산 능력을 갖춘 밀도 모델보다 성능이 떨어지는 경우가 많습니다. 그러나 지시적 튜닝과 결합하면 상황이 달라집니다. 명령어 조정 MoE 모델(Flan-MoE)은 MoE 모델이 밀도 모델에 비해 계산 비용이 1/3에 불과하더라도 여러 작업에서 더 큰 밀도 모델보다 성능이 뛰어납니다. 밀도가 높은 모델과 비교. MoE 모델은 명령 조정을 통해 더욱 중요한 성능 향상을 얻습니다. 따라서 컴퓨팅 효율성과 성능을 고려할 때 MoE는 대규모 언어 모델 훈련을 위한 강력한 도구가 될 것입니다.
4. 이번에 출시된 Mixtral 8x7B 모델도 Sparse Mixed Expert Network를 사용합니다.
① Mixtral 8x7B는 디코더 전용 모델입니다. 피드포워드 모듈은 8개의 서로 다른 매개변수 세트 중에서 선택합니다. 네트워크의 각 계층에서 각 토큰에 대해 라우터 네트워크는 8개 그룹(전문가) 중 2개를 선택하여 토큰을 처리하고 해당 출력을 집계합니다.
② Mixtral 8x7B 모델은 추론 속도가 6배 더 빠르며 대부분의 벤치마크에서 Llama 2 70B 및 GPT3.5와 일치하거나 그보다 성능이 뛰어납니다.
MoE의 중요한 장점: 희소성이란 무엇인가요?
1. 기존의 밀집 모델에서는 각 입력을 전체 모델에서 계산해야 합니다. 희소 혼합 전문가 모델에서는 입력 데이터를 처리할 때 소수의 전문가 모델만 활성화되어 사용되는 반면, 대부분의 전문가 모델은 비활성 상태입니다. 그리고 희소성은 혼합 전문가의 중요한 측면입니다. 모델의 장점은 모델 훈련 및 추론 프로세스의 효율성을 높이는 열쇠이기도 합니다

위 내용은 PRO | MoE 기반의 대형 모델이 더 주목받는 이유는 무엇인가요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 세계에서 가장 강력한 오픈 소스 MoE 모델이 여기에 있습니다. 중국의 기능은 GPT-4와 비슷하며 가격은 GPT-4-Turbo의 거의 1%에 불과합니다.
May 07, 2024 pm 04:13 PM
세계에서 가장 강력한 오픈 소스 MoE 모델이 여기에 있습니다. 중국의 기능은 GPT-4와 비슷하며 가격은 GPT-4-Turbo의 거의 1%에 불과합니다.
May 07, 2024 pm 04:13 PM
기존 컴퓨팅을 능가할 뿐만 아니라 더 낮은 비용으로 더 효율적인 성능을 달성하는 인공 지능 모델을 상상해 보세요. 이것은 공상과학 소설이 아닙니다. DeepSeek-V2[1], 세계에서 가장 강력한 오픈 소스 MoE 모델이 여기에 있습니다. DeepSeek-V2는 경제적인 훈련과 효율적인 추론이라는 특징을 지닌 전문가(MoE) 언어 모델의 강력한 혼합입니다. 이는 236B 매개변수로 구성되며, 그 중 21B는 각 마커를 활성화하는 데 사용됩니다. DeepSeek67B와 비교하여 DeepSeek-V2는 더 강력한 성능을 제공하는 동시에 훈련 비용을 42.5% 절감하고 KV 캐시를 93.3% 줄이며 최대 생성 처리량을 5.76배로 늘립니다. DeepSeek은 일반 인공지능을 연구하는 회사입니다.
 'Defect Spectrum'은 기존 결함 감지의 경계를 뛰어넘어 초고정밀 및 풍부한 의미론적 산업 결함 감지를 최초로 달성합니다.
Jul 26, 2024 pm 05:38 PM
'Defect Spectrum'은 기존 결함 감지의 경계를 뛰어넘어 초고정밀 및 풍부한 의미론적 산업 결함 감지를 최초로 달성합니다.
Jul 26, 2024 pm 05:38 PM
현대 제조업에서 정확한 결함 검출은 제품 품질을 보장하는 열쇠일 뿐만 아니라 생산 효율성을 향상시키는 핵심이기도 합니다. 그러나 기존 결함 감지 데이터세트는 실제 적용에 필요한 정확성과 의미론적 풍부함이 부족한 경우가 많아 모델이 특정 결함 카테고리나 위치를 식별할 수 없게 됩니다. 이 문제를 해결하기 위해 광저우 과학기술대학교와 Simou Technology로 구성된 최고 연구팀은 산업 결함에 대한 상세하고 의미론적으로 풍부한 대규모 주석을 제공하는 "DefectSpectrum" 데이터 세트를 혁신적으로 개발했습니다. 표 1에서 볼 수 있듯이, 다른 산업 데이터 세트와 비교하여 "DefectSpectrum" 데이터 세트는 가장 많은 결함 주석(5438개의 결함 샘플)과 가장 상세한 결함 분류(125개의 결함 카테고리)를 제공합니다.
 수백만 개의 결정 데이터로 훈련하여 결정학적 위상 문제를 해결하는 딥러닝 방법인 PhAI가 Science에 게재되었습니다.
Aug 08, 2024 pm 09:22 PM
수백만 개의 결정 데이터로 훈련하여 결정학적 위상 문제를 해결하는 딥러닝 방법인 PhAI가 Science에 게재되었습니다.
Aug 08, 2024 pm 09:22 PM
Editor |KX 오늘날까지 단순한 금속부터 큰 막 단백질에 이르기까지 결정학을 통해 결정되는 구조적 세부 사항과 정밀도는 다른 어떤 방법과도 비교할 수 없습니다. 그러나 가장 큰 과제인 소위 위상 문제는 실험적으로 결정된 진폭에서 위상 정보를 검색하는 것입니다. 덴마크 코펜하겐 대학의 연구원들은 결정 위상 문제를 해결하기 위해 PhAI라는 딥러닝 방법을 개발했습니다. 수백만 개의 인공 결정 구조와 그에 상응하는 합성 회절 데이터를 사용하여 훈련된 딥러닝 신경망은 정확한 전자 밀도 맵을 생성할 수 있습니다. 연구는 이 딥러닝 기반의 순순한 구조 솔루션 방법이 단 2옹스트롬의 해상도로 위상 문제를 해결할 수 있음을 보여줍니다. 이는 원자 해상도에서 사용할 수 있는 데이터의 10~20%에 해당하는 반면, 기존의 순순한 계산은
 NVIDIA 대화 모델 ChatQA는 버전 2.0으로 발전했으며 컨텍스트 길이는 128K로 언급되었습니다.
Jul 26, 2024 am 08:40 AM
NVIDIA 대화 모델 ChatQA는 버전 2.0으로 발전했으며 컨텍스트 길이는 128K로 언급되었습니다.
Jul 26, 2024 am 08:40 AM
오픈 LLM 커뮤니티는 백개의 꽃이 피어 경쟁하는 시대입니다. Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 등을 보실 수 있습니다. 훌륭한 연기자. 그러나 GPT-4-Turbo로 대표되는 독점 대형 모델과 비교하면 개방형 모델은 여전히 많은 분야에서 상당한 격차를 보이고 있습니다. 일반 모델 외에도 프로그래밍 및 수학을 위한 DeepSeek-Coder-V2, 시각 언어 작업을 위한 InternVL과 같이 핵심 영역을 전문으로 하는 일부 개방형 모델이 개발되었습니다.
 Google AI가 IMO 수학 올림피아드 은메달을 획득하고 수학적 추론 모델 AlphaProof가 출시되었으며 강화 학습이 다시 시작되었습니다.
Jul 26, 2024 pm 02:40 PM
Google AI가 IMO 수학 올림피아드 은메달을 획득하고 수학적 추론 모델 AlphaProof가 출시되었으며 강화 학습이 다시 시작되었습니다.
Jul 26, 2024 pm 02:40 PM
AI의 경우 수학 올림피아드는 더 이상 문제가 되지 않습니다. 목요일에 Google DeepMind의 인공 지능은 AI를 사용하여 올해 국제 수학 올림피아드 IMO의 실제 문제를 해결하는 위업을 달성했으며 금메달 획득에 한 걸음 더 다가섰습니다. 지난 주 막 끝난 IMO 대회에는 대수학, 조합론, 기하학, 수론 등 6개 문제가 출제됐다. 구글이 제안한 하이브리드 AI 시스템은 4문제를 맞혀 28점을 얻어 은메달 수준에 이르렀다. 이달 초 UCLA 종신 교수인 테렌스 타오(Terence Tao)가 상금 100만 달러의 AI 수학 올림피아드(AIMO Progress Award)를 추진했는데, 예상외로 7월 이전에 AI 문제 해결 수준이 이 수준으로 향상됐다. IMO에서 동시에 질문을 해보세요. 가장 정확하게 하기 어려운 것이 IMO인데, 역사도 가장 길고, 규모도 가장 크며, 가장 부정적이기도 합니다.
 PRO | MoE 기반의 대형 모델이 더 주목받는 이유는 무엇인가요?
Aug 07, 2024 pm 07:08 PM
PRO | MoE 기반의 대형 모델이 더 주목받는 이유는 무엇인가요?
Aug 07, 2024 pm 07:08 PM
2023년에는 AI의 거의 모든 분야가 전례 없는 속도로 진화하고 있다. 동시에 AI는 구체화된 지능, 자율주행 등 핵심 트랙의 기술적 한계를 지속적으로 확장하고 있다. 멀티모달 추세 하에서 AI 대형 모델의 주류 아키텍처인 Transformer의 상황이 흔들릴까요? MoE(Mixed of Experts) 아키텍처를 기반으로 한 대형 모델 탐색이 업계에서 새로운 트렌드가 된 이유는 무엇입니까? 대형 비전 모델(LVM)이 일반 비전 분야에서 새로운 돌파구가 될 수 있습니까? ...지난 6개월 동안 공개된 본 사이트의 2023 PRO 회원 뉴스레터에서 위 분야의 기술 동향과 산업 변화에 대한 심층 분석을 제공하여 새로운 환경에서 귀하의 목표 달성에 도움이 되는 10가지 특별 해석을 선택했습니다. 년. 준비하세요. 이 해석은 2023년 50주차에 나온 것입니다.
 대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
편집자 |ScienceAI 질문 응답(QA) 데이터 세트는 자연어 처리(NLP) 연구를 촉진하는 데 중요한 역할을 합니다. 고품질 QA 데이터 세트는 모델을 미세 조정하는 데 사용될 수 있을 뿐만 아니라 LLM(대형 언어 모델)의 기능, 특히 과학적 지식을 이해하고 추론하는 능력을 효과적으로 평가하는 데에도 사용할 수 있습니다. 현재 의학, 화학, 생물학 및 기타 분야를 포괄하는 과학적인 QA 데이터 세트가 많이 있지만 이러한 데이터 세트에는 여전히 몇 가지 단점이 있습니다. 첫째, 데이터 형식이 비교적 단순하고 대부분이 객관식 질문이므로 평가하기 쉽지만 모델의 답변 선택 범위가 제한되고 모델의 과학적 질문 답변 능력을 완전히 테스트할 수 없습니다. 이에 비해 개방형 Q&A는
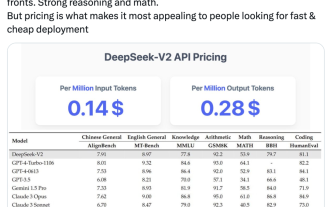 국내 오픈소스 MoE 지표 폭발: GPT-4 수준 기능, API 가격은 1%에 불과
May 07, 2024 pm 05:34 PM
국내 오픈소스 MoE 지표 폭발: GPT-4 수준 기능, API 가격은 1%에 불과
May 07, 2024 pm 05:34 PM
국내 최신 대형 오픈소스 MoE 모델은 출시 직후 인기를 끌었다. DeepSeek-V2의 성능은 GPT-4 수준에 도달하지만 오픈 소스이며 상업용으로 무료이며 API 가격은 GPT-4-Turbo의 1%에 불과합니다. 그래서 공개되자마자 많은 논란이 일었습니다. 공개된 성능 지표에 따르면 DeepSeekV2의 포괄적인 중국어 기능은 많은 오픈 소스 모델을 능가하는 동시에 GPT-4Turbo 및 Wenkuai 4.0과 같은 폐쇄 소스 모델도 첫 번째 단계에 있습니다. 종합적인 영어 능력 역시 LLaMA3-70B와 동일한 1계급에 속하며, 역시 MoE인 Mixtral8x22B를 능가합니다. 또한 지식, 수학, 추론, 프로그래밍 등에서도 좋은 성적을 보여줍니다. 그리고 128K 컨텍스트를 지원합니다. 이것을 상상해 보세요
