

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
人物交互图像生成指生成满足文本描述需求,内容为人与物体交互的图像,并要求图像尽可能真实且符合语义。近年来,文本生成图像模型在生成真实图像方面取得出了显著的进展,但这些模型在生成以人物交互为主体内容的高保真图像生成方面仍然面临挑战。其困难主要源于两个方面:一是人体姿势的复杂性和多样性给合理的人物生成带来挑战;二是交互边界区域(交互语义丰富区域)不可靠的生成可能导致人物交互语义表达的不足。
针对上述问题,来自北京大学的研究团队提出了一种姿势和交互感知的人物交互图像生成框架(SA-HOI), 利用人体姿势的生成质量和交互边界区域信息作为去噪过程的指导,生成了更合理,更真实的人物交互图像。为了全面测评生成图像的质量,他们还提出了一个全面的人物交互图像生成基准。

论文链接:https://proceedings.mlr.press/v235/xu24e.html
项目主页:https://sites.google.com/view/sa-hoi/
源代码链接:https://github.com/XZPKU/SA-HOI
实验室主页:http://www.wict.pku.edu.cn/mipl
SA-HOI 是一种语义感知的人物交互图像生成方法,从人体姿态和交互语义两方面提升人物交互图像生成的整体质量并减少存在的生成问题。通过结合图像反演的方法,生成了迭代式反演和图像修正流程,可以使生成图像逐步自我修正,提升质量。
研究团队在论文中还提出了第一个涵盖人 - 物体、人 - 动物和人 - 人交互的人物交互图像生成基准,并为人物交互图像生成设计了针对性的评估指标。大量实验表明,该方法在针对人物交互图像生成的评估指标和常规图像生成的评估指标下均优于现有的基于扩散的图像生成方法。
方法介绍
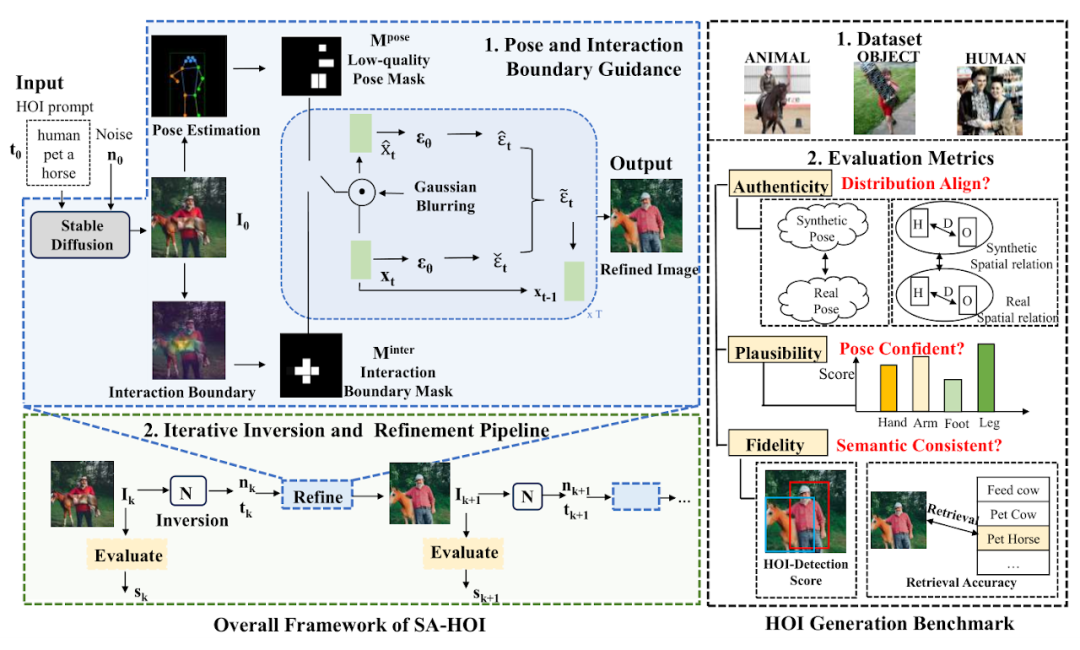
图 1:语义感知的人物交互图像生成方法框架图
论文中提出的方法如图 1 所示,主要由两个设计组成:姿态和交互指导(Pose and Interaction Guidance, PIG)和迭代反演和修正流程(Iterative Inversion and Refinement Pipeline, IIR)。
PIG에서는 주어진 문자 상호 작용 텍스트 설명 및 노이즈
및 노이즈 에 대해 먼저 안정적인 확산 모델(Stable Diffusion [2])을 사용하여
에 대해 먼저 안정적인 확산 모델(Stable Diffusion [2])을 사용하여  을 초기 이미지로 생성하고 포즈 감지기[3]를 사용하여 인체 관절 위치
을 초기 이미지로 생성하고 포즈 감지기[3]를 사용하여 인체 관절 위치  및 해당 신뢰도 점수
및 해당 신뢰도 점수  , 품질이 낮은 포즈 영역을 강조하는 포즈 마스크
, 품질이 낮은 포즈 영역을 강조하는 포즈 마스크  를 구성합니다.
를 구성합니다.
대화형 안내의 경우 분할 모델을 사용하여 상호작용 경계 영역을 찾고, 핵심 포인트 및 해당 신뢰도 점수
및 해당 신뢰도 점수 를 얻고, 상호작용 마스크
를 얻고, 상호작용 마스크 에서 상호작용 영역을 강조 표시하여 상호작용 경계의 의미적 표현을 향상시킵니다. 각 노이즈 제거 단계에서
에서 상호작용 영역을 강조 표시하여 상호작용 경계의 의미적 표현을 향상시킵니다. 각 노이즈 제거 단계에서  및
및  는 강조 표시된 영역을 수정하기 위한 제약 조건으로 사용되어 해당 영역에 존재하는 생성 문제를 줄입니다. 또한 IIR은 이미지 반전 모델 N과 결합하여 추가 보정이 필요한 이미지에서 노이즈 n과 텍스트 설명의 임베딩 t를 추출한 후 PIG를 사용하여 이미지에 대한 다음 보정을 수행하고 품질을 사용합니다. 평가자 Q는 수정된 이미지의 품질을 평가하고 연산을 사용하여 이미지 품질을 점진적으로 향상시킵니다.指 指 자세 및 상호 작용 안내
는 강조 표시된 영역을 수정하기 위한 제약 조건으로 사용되어 해당 영역에 존재하는 생성 문제를 줄입니다. 또한 IIR은 이미지 반전 모델 N과 결합하여 추가 보정이 필요한 이미지에서 노이즈 n과 텍스트 설명의 임베딩 t를 추출한 후 PIG를 사용하여 이미지에 대한 다음 보정을 수행하고 품질을 사용합니다. 평가자 Q는 수정된 이미지의 품질을 평가하고 연산을 사용하여 이미지 품질을 점진적으로 향상시킵니다.指 指 자세 및 상호 작용 안내

姿势和交互引导采样的伪代码如图 2 所示,在每个去噪步骤中,我们首先按照稳定扩散模型(Stable Diffusion)中的设计获取预测的噪声 ϵt 和中间重构 。然后我们在 上应用高斯模糊 G 来获得退化的潜在特征 和 ,随后将对应潜在特征中的信息引入去噪过程中。 여기서 여기서 фt는 시간 단계 t에서 마스크를 생성하는 임계값입니다. 마찬가지로, 대화형 안내를 위해 논문 저자는 분할 모델을 사용하여 물체의 외부 윤곽점 O와 인체 관절점 C를 획득하고 사람과 물체 사이의 거리 행렬 D를 계산하고 핵심 포인트를 샘플링합니다. 그것으로부터 상호작용 경계 반복적인 반전 및 이미지 수정 프로세스 생성된 이미지의 품질 평가를 실시간으로 얻기 위해 논문 저자는 반복 작업에 대한 가이드로 품질 평가기 Q를 소개합니다. k번째 라운드 이미지 그러나 이러한 노이즈는 쉽게 사용할 수 없으므로 이미지 반전 방법 通过比较前后迭代轮次中的质量分数,可以判断是否要继续进行优化:当 人物交互图像生成基准 考虑到没有针对人物交互图像生成任务设计的现有模型和基准,论文作者收集并整合了一个人物交互图像生成基准,包括一个含有150 个人物交互类别的真实人物交互图像数据集,以及若干为人物交互图像生成定制的测评指标。 该数据集从开源人物交互检测数据集 HICO-DET [5] 中筛选得到 150 个人物交互类别,涵盖了人 - 物体、人 - 动物和人 - 人三种不同交互场景。共计收集了 5k 人物交互真实图像作为该论文的参考数据集,用于评估生成人物交互图像的质量。 为了更好地评估生成的人物交互图像质量,论文作者为人物交互生成量身定制了几个测评标准,从可靠性(Authenticity)、可行性(Plausibility) 和保真度(Fidelity) 的角度全面评估生成图像。可靠性上,论文作者引入姿势分布距离和人 - 物体距离分布,评估生成结果和真实图像是否接近:生成结果在分布意义上越接近真实图像,就说明质量越好。可行性上,采用计算姿势置信度分数来衡量生成人体关节的可信度和合理性。保真度上,采用人物交互检测任务,以及图文检索任务评估生成图像与输入文本之间的语义一致性。 实验结果 与现有方法的对比实验结果如表 1 和表 2 所示,分别对比了人物交互图像生成指标和常规图像生成指标上的性能。 表1:与现有方法在人物交互图像生成指标的对比实验结果 表2:与现有方法在常规图像生成指标的对比实验结果 实验结果表明,该论文中的方法在人体生成质量,交互语义表达,人物交互距离,人体姿态分布,整体图像质量等多个维度的测评上都优于现有模型。 此外,论文作者还进行了主观评测,邀请众多用户从人体质量,物体外观,交互语义和整体质量等多个角度进行评分,实验结果证明SA-HOI 的方法在各个角度都更符合人类审美。 Tableau 3 : Résultats de l'évaluation subjective avec les méthodes existantes Dans les expériences qualitatives, la figure ci-dessous montre la comparaison des résultats générés par différentes méthodes pour la même description de catégorie d'interaction de personnage. Dans le groupe d'images ci-dessus, le modèle utilisant la nouvelle méthode exprime avec précision la sémantique du « baiser », et les postures du corps humain générées sont également plus raisonnables. Dans le groupe d'images ci-dessous, la méthode décrite dans l'article atténue également avec succès la distorsion et la distorsion du corps humain qui existent dans d'autres méthodes, et améliore l'interaction de « prendre la valise » en générant le levier de la valise dans la zone où la main interagit avec la valise Expression sémantique, obtenant ainsi des résultats supérieurs aux autres méthodes en termes de posture du corps humain et de sémantique d'interaction. . [1] Rombach, R., Blattmann, A., Lorenz, D., Esser, P. et Ommer, B. Synthèse d'images haute résolution avec modèles de diffusion latente. de la conférence IEEE/CVF Conférence sur la vision par ordinateur et la reconnaissance de formes (CVPR), pp. 10684-10695, juin 2022 [2] HuggingFace, 2022. URL https://huggingface . co/CompVis/stable-diffusion-v1-4 [3] Chen, K., Wang, J., Pang, J., Cao, Y., Xiong, Y., Li, X . , Sun, S., Feng, W., Liu, Z., Xu, J., Zhang, Z., Cheng, D., Zhu, C ., Cheng, T., Zhao, Q., Li , B., Lu, X., Zhu, R., Wu, Y., Dai, J., Wang, J., Shi, J., Ouyang, W., Loy, C. C. et Lin, D. MMDétection : Ouverte Boîte à outils et référence de détection mmlab. Préimpression arXiv arXiv:1906.07155, 2019. [4] Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch et Daniel Cohen-Or- texte. inversion pour l'édition d'images réelles à l'aide de modèles de diffusion guidée arXiv arXiv:2211.09794, 2022. [5] Yu-Wei Chao, Zhan Wang, Yugeng He, Jiaxuan Wang et Jia Deng. . HICO : Une référence pour la reconnaissance des interactions homme-objet dans les images. Dans les actes de la conférence internationale de l'IEEE sur la vision par ordinateur, 2015. . 和
和  被用于生成
被用于生成  和
和 ,并在
,并在  和
和  中突出低姿势质量区域,指导模型减少这些区域的畸变生成。为了指导模型改进低质量区域,将通过如下公式来高亮低姿势得分区域:
中突出低姿势质量区域,指导模型减少这些区域的畸变生成。为了指导模型改进低质量区域,将通过如下公式来高亮低姿势得分区域:
 , x, y는 이미지의 픽셀별 좌표이고, H, W는 이미지 크기이며, σ는 가우스 분포의 분산입니다.
, x, y는 이미지의 픽셀별 좌표이고, H, W는 이미지 크기이며, σ는 가우스 분포의 분산입니다.  는 i번째 관절을 중심으로 한 주의를 나타냅니다. 모든 관절의 주의를 결합하여 최종 주의 지도
는 i번째 관절을 중심으로 한 주의를 나타냅니다. 모든 관절의 주의를 결합하여 최종 주의 지도 를 형성하고 임계값을 사용하여 를 마스크로 변환할 수 있습니다.
를 형성하고 임계값을 사용하여 를 마스크로 변환할 수 있습니다.  , 사용 및 자세 안내 동일한 방법으로 상호작용 주의
, 사용 및 자세 안내 동일한 방법으로 상호작용 주의 및 마스크를 생성하고 최종 예측 노이즈를 계산하는 데 적용됩니다.
및 마스크를 생성하고 최종 예측 노이즈를 계산하는 데 적용됩니다.  의 경우 평가자 Q를 사용하여 품질 점수
의 경우 평가자 Q를 사용하여 품질 점수  를 얻은 다음
를 얻은 다음  를 기반으로
를 기반으로  를 생성합니다. 최적화 후에도 의 주요 내용을 유지하려면 해당 노이즈가 노이즈 제거 초기값으로 필요합니다.
를 생성합니다. 최적화 후에도 의 주요 내용을 유지하려면 해당 노이즈가 노이즈 제거 초기값으로 필요합니다.  을 도입하여 노이즈 잠재적인 특성
을 도입하여 노이즈 잠재적인 특성  을 얻고 텍스트 임베딩
을 얻고 텍스트 임베딩  을 PIG의 입력으로 사용하여 최적화된 결과
을 PIG의 입력으로 사용하여 최적화된 결과  를 생성합니다.
를 생성합니다.  和
和 之间没有显着差异,即低于阈值θ,可以认为该流程可能已经对图像做出了充足的修正,因此结束优化并输出质量分数最高的图像。
之间没有显着差异,即低于阈值θ,可以认为该流程可能已经对图像做出了充足的修正,因此结束优化并输出质量分数最高的图像。  图3:人物交互图像生成基准(数据集+ 测评指标)
图3:人物交互图像生成基准(数据集+ 测评指标)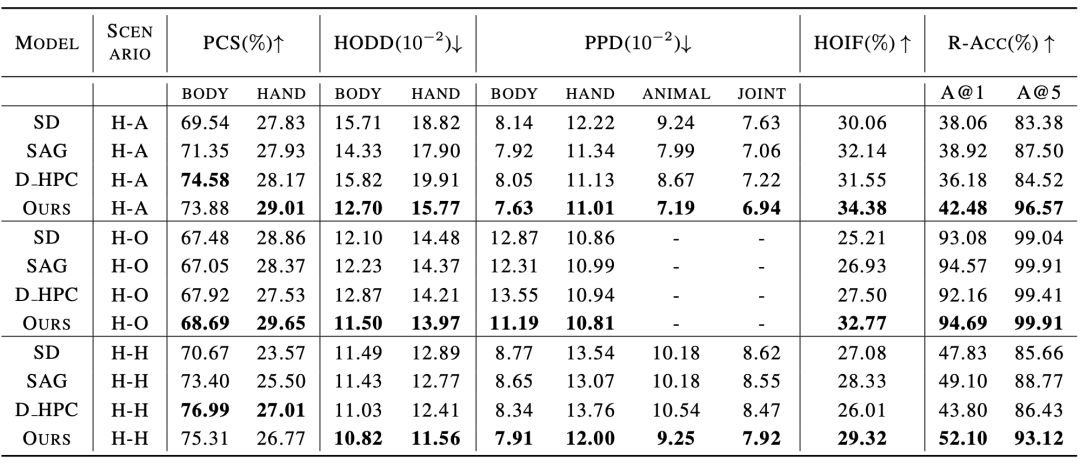



위 내용은 ICML 2024 | 문자 상호 작용 이미지, 이제 귀하의 프롬프트 단어를 더 잘 이해하게 되었습니다. Peking University는 의미 인식을 기반으로 하는 문자 상호 작용 이미지 생성 프레임워크를 출시합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



