
저는 이모티콘을 좋아해요. 그렇지 않은 사람은 누구인가요?
며칠 전 지적 수준이 높은 X포스트를 정리하던 중 깨달은 사실이 있습니다.
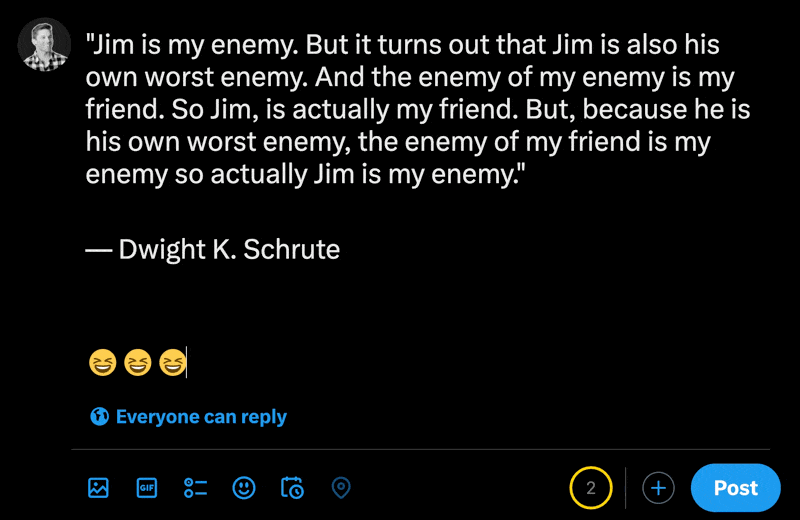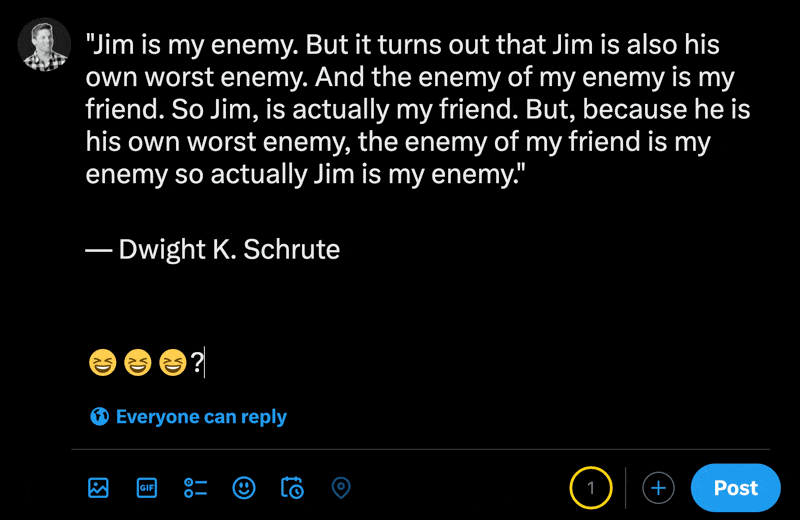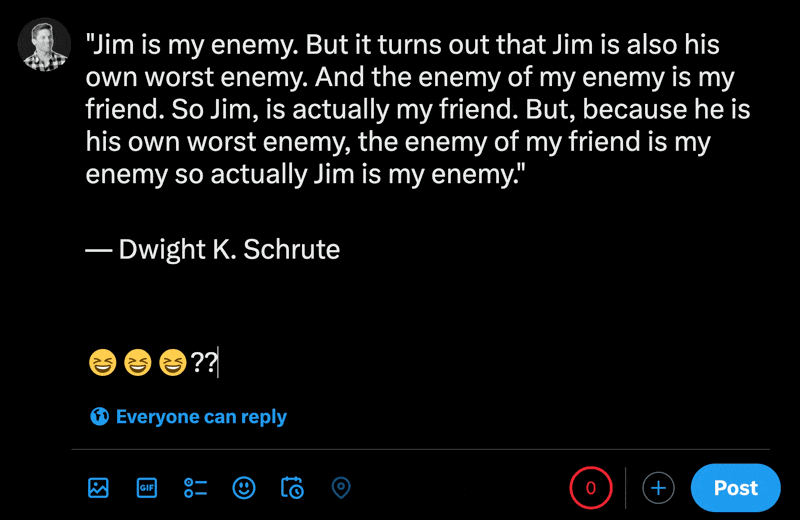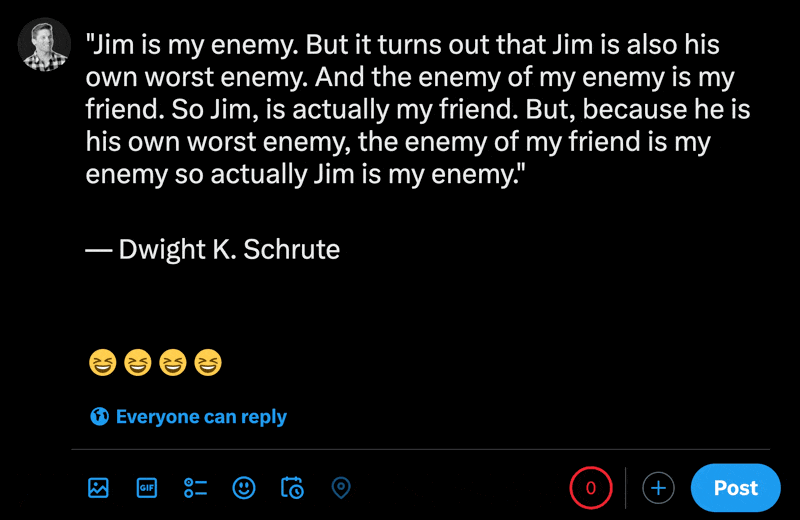
X의 새 게시물 섹션에 이모티콘을 입력하면 일반 문자가 이모티콘보다 얼마나 적은지 확인할 수 있습니다.
빠른 검색 끝에 유니코드 시스템에서 인코딩되는 방식과 관련이 있다는 것을 알게 되었습니다.
기본적으로 이모티콘은 여러 코드 포인트로 구성되며, 길이는 문자가 아닌 코드 포인트만 계산합니다.
왜 그런 일이 일어나는지와는 상관없이 내가 만든 모든 텍스트 카운터가 SaaS 땅에 얼마나 존재하는지 생각해 보았습니다.
이모지가 제대로 흔들리지 않나요?.
단순히 문자열의 길이만 취하는 것은 정확한 계산이 아닙니다. 예를 들어 다음과 같습니다.
import { useState } from "react";
export default function App() {
const [text, setText] = useState("");
function countString() {
return text.length;
}
function handleChange(e) {
setText(e.target.value);
}
return (
<div className="App">
<h1>Make the emojis count ?</h1>
<textarea value={text} onChange={handleChange} />
<small>Characters: {countString()}</small>
</div>
);
}
이것은 텍스트 필드에 입력된 문자를 추적하는 간단한 React 구성 요소입니다. 이 기능의 가장 일반적인 구현입니다.
그러나 출력 결과는 내 X 포스트와 동일한 문제를 나타냅니다.

Intl.Segmenter라는 내장 개체를 사용할 수 있습니다.
객체의 사용 사례는 훨씬 더 광범위하지만 기본적으로 제공하는 로케일을 기반으로 문자열을 단어 및 문장과 같은 더 의미 있는 항목으로 나눕니다. 단순히 코드 포인트를 사용하는 것보다 더 세분화된 기능을 제공합니다.
위의 예를 수정하려면 다음과 같이 countString 함수를 업데이트하면 됩니다.
import { useState } from "react";
export default function App() {
const [text, setText] = useState("");
function countString() {
return Array.from(new Intl.Segmenter().segment(text)).length;
}
function handleChange(e) {
setText(e.target.value);
}
return (
<div className="App">
<h1>Make the emojis count ?</h1>
<textarea value={text} onChange={handleChange} />
<small>Characters: {countString()}</small>
</div>
);
}
Intl.Segmenter 개체의 새 인스턴스를 만들고 여기에 텍스트를 전달합니다. 그 출력을 배열에 넣은 다음 최종적으로 길이를 취하는데 이는 단순히 원래 문자열의 길이를 취하는 것보다 훨씬 더 정확합니다.
결과는 다음과 같습니다.

짧은 답변: 모르겠어요.
간단한 답이 있다고 착각할 만큼 너무 오랫동안 프로그래밍을 해왔습니다.
그러나 Intl.Segmenter는 우수한 브라우저 지원을 제공하므로 성능이나 메모리 제약은 무시할 수 있습니다.
제 추측으로는 코드베이스가 너무 크고 오래되어서 리팩토링으로 인한 부작용을 감수할 가치가 없다는 것입니다.
이 문제에 대해 더 나은 통찰력을 갖고 있는 분이 계시다면 기꺼이 자세히 알아보고 싶습니다.
도움이 되었기를 바랍니다.
행복한 코딩 ?.
위 내용은 JavaScript에서 이모티콘으로 문자열을 계산하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



