
Scrapy로 웹사이트를 크롤링할 때 스크래핑하려는 페이지와 창의력을 발휘하거나 상호 작용해야 하는 모든 종류의 시나리오를 빠르게 접하게 됩니다. 이러한 시나리오 중 하나는 무한 스크롤 페이지를 크롤링해야 하는 경우입니다. 이러한 유형의 웹사이트 페이지는 소셜 미디어 피드처럼 페이지를 아래로 스크롤할 때 더 많은 콘텐츠를 로드합니다.
이러한 유형의 페이지를 크롤링하는 방법은 여러 가지가 있습니다. 최근에 제가 접근한 한 가지 방법은 페이지 길이가 더 이상 늘어나지 않을 때까지(즉, 아래쪽으로 스크롤) 계속 스크롤하는 것이었습니다. 이 게시물은 이 과정을 단계별로 안내합니다.
이 게시물에서는 Scrapy 프로젝트가 설정되어 실행되고 있으며 수정하고 실행할 수 있는 Spider가 있다고 가정합니다.
이 통합에서는 scrapy-playwright 플러그인을 사용하여 Playwright for Python을 Scrapy와 통합합니다. Playwright는 웹페이지와 상호작용하고 데이터를 추출하는 데 사용되는 헤드리스 브라우저 자동화 라이브러리입니다.
저는 Python 패키지 설치 및 관리에 uv를 사용해 왔습니다.
그런 다음 다음과 같이 uv에서 바로 가상 환경을 사용합니다.
uv venv source .venv/bin/activate
가상 환경에 다음 명령을 사용하여 scrapy-playwright 플러그인과 Playwright를 설치하세요.
uv pip install scrapy-playwright
Playwright와 함께 사용하고 싶은 브라우저를 설치하세요. 예를 들어 Chromium을 설치하려면 다음 명령을 실행할 수 있습니다.
playwright install chromium
필요한 경우 Firefox와 같은 다른 브라우저를 설치할 수도 있습니다.
참고: 아래 Scrapy 코드와 Playwright 통합은 Chromium에서만 테스트되었습니다.
DOWNLOAD_HANDLERS 및 PLAYWRIGHT_LAUNCH_OPTIONS 설정을 포함하도록 스파이더의 settings.py 파일 또는 custom_settings 속성을 업데이트하세요.
# settings.py
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
DOWNLOAD_HANDLERS = {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
PLAYWRIGHT_LAUNCH_OPTIONS = {
# optional for CORS issues
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
# optional for debugging
"headless": False,
},
PLAYWRIGHT_LAUNCH_OPTIONS의 경우 헤드리스 옵션을 False로 설정하여 브라우저 인스턴스를 열고 프로세스 실행을 볼 수 있습니다. 이는 초기 스크레이퍼를 디버깅하고 구축하는 데 좋습니다.
웹 보안을 비활성화하고 출처를 격리하기 위해 추가 인수를 전달합니다. 이는 CORS 문제가 있는 사이트를 크롤링할 때 유용합니다.
예를 들어 CORS로 인해 필수 JavaScript 자산이 로드되지 않거나 네트워크 요청이 이루어지지 않는 상황이 있을 수 있습니다. 특정 페이지 작업(예: 버튼 클릭)이 예상대로 작동하지 않지만 다른 모든 작업은 작동하는 경우 브라우저 콘솔에서 오류를 확인하여 이 문제를 더 빨리 격리할 수 있습니다.
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
"headless": False,
}
이것은 무한 스크롤 페이지를 크롤링하는 스파이더의 예입니다. 스파이더는 페이지를 700픽셀씩 스크롤하고 요청이 완료될 때까지 750ms를 기다립니다. 스파이더는 루프를 통과할 때 스크롤 위치가 변하지 않고 표시된 페이지 하단에 도달할 때까지 계속 스크롤합니다.
설정을 한곳에 유지하기 위해 custom_settings를 사용하여 스파이더 자체에서 설정을 수정하고 있습니다. 이러한 설정을 settings.py 파일에 추가할 수도 있습니다.
# /<project>/spiders/infinite_scroll.py
import scrapy
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
class InfinitePageSpider(CrawlSpider):
"""
Spider to crawl an infinite scroll page
"""
name = "infinite_scroll"
allowed_domains = ["<allowed_domain>"]
start_urls = ["<start_url>"]
custom_settings = {
"TWISTED_REACTOR": "twisted.internet.asyncioreactor.AsyncioSelectorReactor",
"DOWNLOAD_HANDLERS": {
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
},
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
"headless": False,
},
"LOG_LEVEL": "INFO",
}
def start_requests(self):
yield scrapy.Request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=True,
playwright_include_page=True,
),
callback=self.parse,
)
async def parse(
self,
response,
):
page = response.meta["playwright_page"]
page.set_default_timeout(10000)
await page.wait_for_timeout(5000)
try:
last_position = await page.evaluate("window.scrollY")
while True:
# scroll by 700 while not at the bottom
await page.evaluate("window.scrollBy(0, 700)")
await page.wait_for_timeout(750) # wait for 750ms for the request to complete
current_position = await page.evaluate("window.scrollY")
if current_position == last_position:
print("Reached the bottom of the page.")
break
last_position = current_position
except Exception as error:
print(f"Error: {error}")
pass
print("Getting content")
content = await page.content()
print("Parsing content")
selector = Selector(text=content)
print("Extracting links")
links = selector.xpath("//a[contains(@href, '/<link-pattern>/')]//@href").getall()
print(f"Found {len(links)} links...")
print("Yielding links")
for link in links:
yield {"link": link}
제가 배운 한 가지 사실은 두 페이지나 사이트가 동일하지 않으므로 페이지를 고려하기 위해 스크롤 양과 대기 시간을 조정해야 할 수도 있고 요청에 대한 네트워크 왕복 지연 시간도 조정해야 할 수도 있다는 것입니다. 완벽한. 스크롤 위치와 요청 완료에 걸리는 시간을 확인하여 프로그래밍 방식으로 이를 동적으로 조정할 수 있습니다.
페이지 로드 시 자산이 로드되고 페이지가 렌더링될 때까지 조금 더 기다립니다. Playwright 페이지는 response.meta 객체의 구문 분석 콜백 메소드에 전달됩니다. 이는 페이지와 상호작용하고 페이지를 스크롤하는 데 사용됩니다. 이는 playwright=True 및 playwright_include_page=True 옵션을 사용하여 scrapy.Request 인수에 지정됩니다.
def start_requests(self):
yield scrapy.Request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=True,
playwright_include_page=True,
),
callback=self.parse,
)
이 스파이더는 page.evaluate 및 scrollBy() JavaScript 메소드를 사용하여 페이지를 700픽셀만큼 스크롤한 다음 요청이 완료될 때까지 750ms를 기다립니다. 그런 다음 극작가 페이지 콘텐츠가 Scrapy 선택기에 복사되고 페이지에서 링크가 추출됩니다. 그런 다음 링크는 Scrapy 파이프라인에 양보되어 처리를 계속합니다.
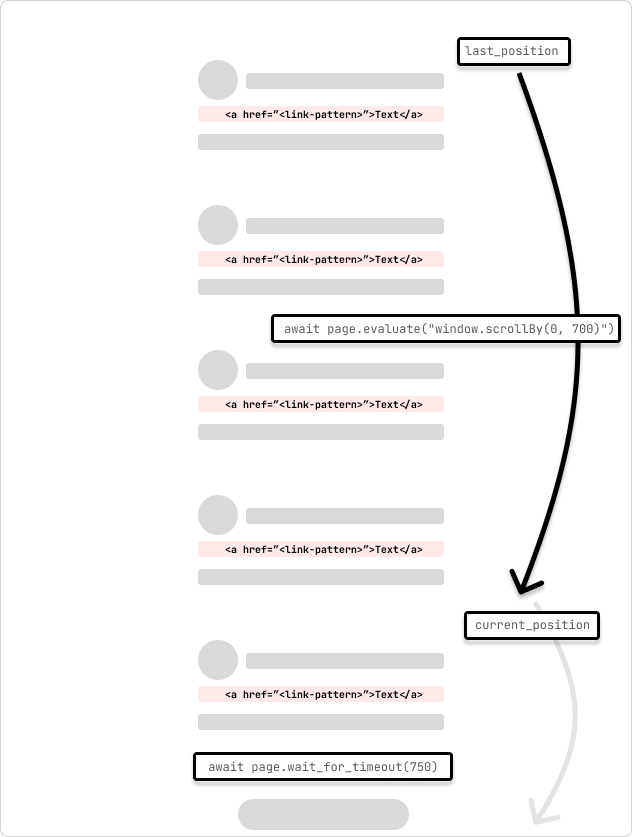
페이지 요청이 중복된 콘텐츠를 로드하기 시작하는 상황에서는 콘텐츠가 이미 로드되었는지 확인하고 루프를 중단할 수 있는지 확인하는 기능을 추가할 수 있습니다. 또는 스크롤 로드 횟수에 대한 아이디어가 있는 경우 버퍼를 더하거나 뺀 특정 수의 스크롤 후에 루프를 중단하는 카운터를 추가할 수 있습니다.
It's also possible that the page may have an element that you can scroll to (i.e. "Load more") that will trigger the next set of content to load. You can use the page.evaluate method to scroll to the element and then click it to load the next set of content.
...
try:
while True:
button = page.locator('//button[contains(., "Load more")]')
await button.wait_for()
if not button:
print("No 'Load more' button found.")
break
is_disabled = await button.is_disabled()
if is_disabled:
print("Button is disabled.")
break
await button.scroll_into_view_if_needed()
await button.click()
await page.wait_for_timeout(750)
except Exception as error:
print(f"Error: {error}")
pass
...
This method is useful when you know the page has a button that will load the next set of content. You can also use this method to click on other elements that will trigger the next set of content to load. The scroll_into_view_if_needed method will scroll the button or element into view if it is not already visible on the page. This is one of those scenarios when you will want to double-check the page actions with headless=False to see if the button is being clicked and the content is being loaded as expected before running a full crawl.
Note: As mentioned above, confirm that the page assets(.js) are loading correctly and that the network requests are being made so that the button (or element) is mounted and clickable.
Web crawling is a case-by-case scenario and you will need to adjust the code to fit the page that you are trying to scrape. The above code is a starting point to get you going with crawling infinite scroll pages with Scrapy and Playwright.
Hopefully, this helps to get you unblocked! ?
Subscribe to get my latest content by email -> Newsletter
위 내용은 Scrapy와 Playwright를 사용하여 무한 스크롤로 페이지 크롤링의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



