
탐색적 데이터 분석은 데이터 세트를 분석하고 결과를 시각적으로 제시하는 데 널리 사용되는 접근 방식입니다. 이는 데이터 세트와 구조에 대한 최대한의 통찰력을 제공하는 데 도움이 됩니다. 이는 탐색적 데이터 분석을 데이터의 다양한 측면을 이해하는 기술로 식별합니다.
데이터를 더 잘 이해하려면 데이터가 깨끗하고 중복성, 누락된 값 또는 NULL 값이 없는지 확인해야 합니다.
세 가지 주요 유형이 있습니다.
일변량: 언제든지 하나의 변수(열)를 보는 곳입니다. 변수의 성격을 더 잘 이해하는 데 도움이 되며 가장 쉬운 유형의 EDA라고 합니다.
이변량: 두 변수를 함께 살펴보는 곳입니다. 이는 변수 A와 B가 독립인지 상관인지 관계를 이해하는 데 도움이 됩니다.
다변량: 한 번에 3개 이상의 변수를 살펴보는 작업이 포함됩니다. 이는 "고급" 이변량으로 식별됩니다.
그래픽: 여기에는 그래프 및 차트와 같은 시각적 표현을 통해 데이터를 탐색하는 작업이 포함됩니다. 일반적인 시각화에는 상자 그림, 막대 그래프, 산점도 및 열 지도가 포함됩니다.
비그래픽: 이는 통계 기법을 통해 수행됩니다. 사용되는 측정 항목에는 평균, 중앙값, 모드, 표준 편차 및 백분위수가 포함됩니다.
EDA에 사용되는 가장 일반적인 도구는 다음과 같습니다
Python: 기존 구성 요소를 연결하고 누락된 값을 식별하는 데 사용되는 객체 지향 프로그래밍 언어
R: 통계 컴퓨팅에 사용되는 오픈 소스 프로그래밍 언어
이 예시에 사용된 데이터세트는 Iris 데이터세트입니다. 여기에서 확인하세요
df = pd.read_csv(io.BytesIO(uploaded['Iris.csv'])) df.head()

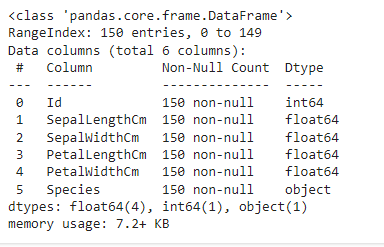


df.plot(kind='scatter', x='SepalLengthCm', y='SepalWidthCm') ; plt.show()

위 내용은 데이터 이해: 탐색적 데이터 분석의 필수 요소의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



